شراء الخدمة الآن
تحليل بيانات الافلام مع انشاء web scraping python تفاعلي
شراء الخدمة
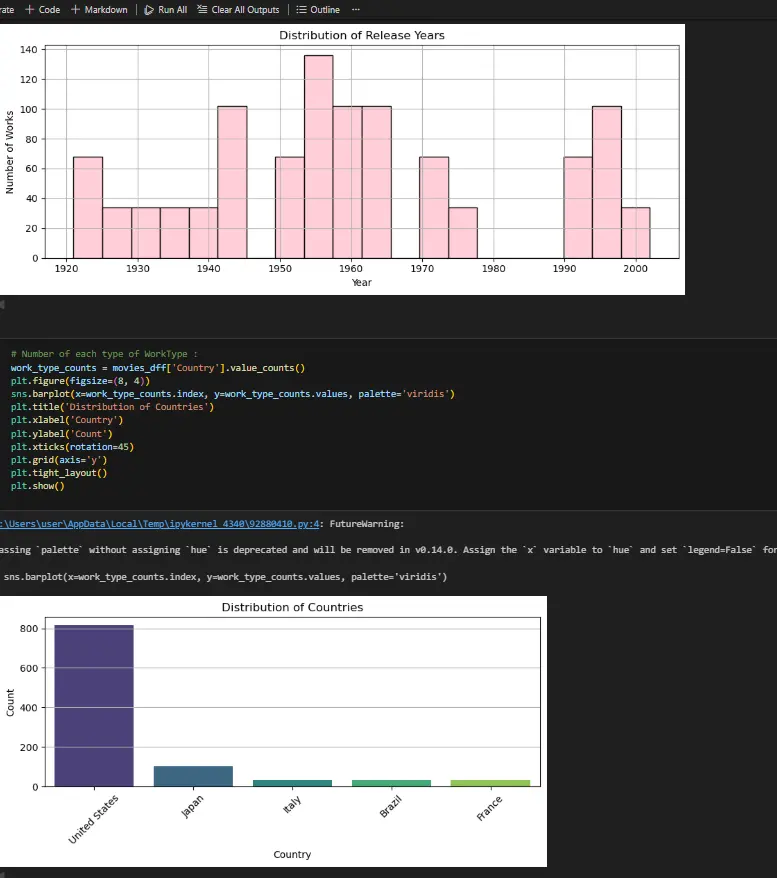
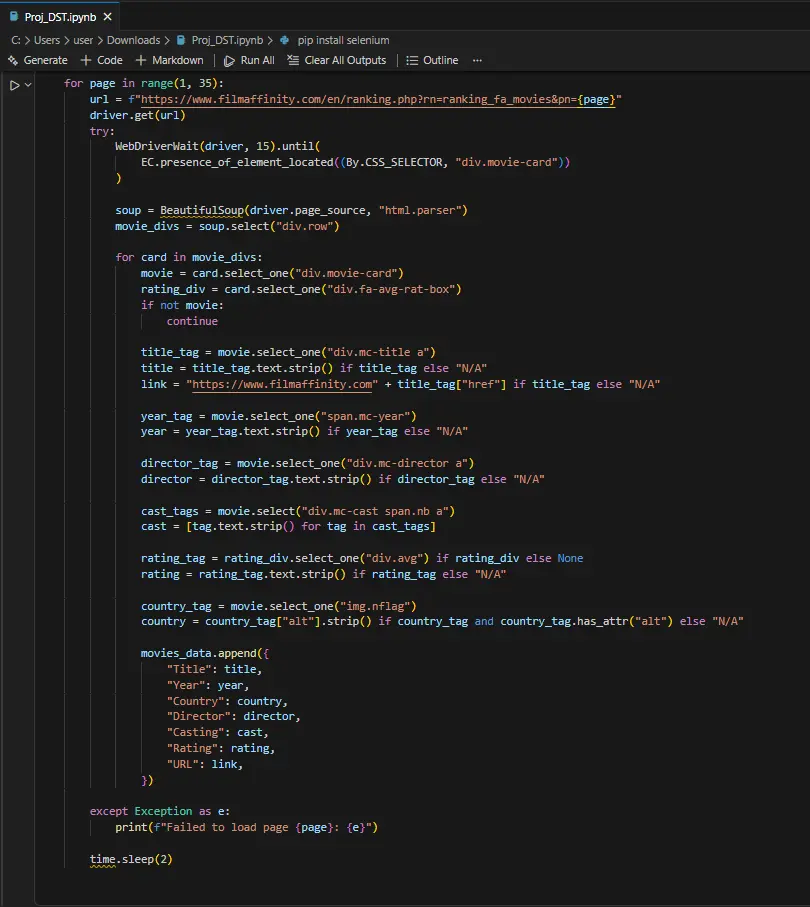
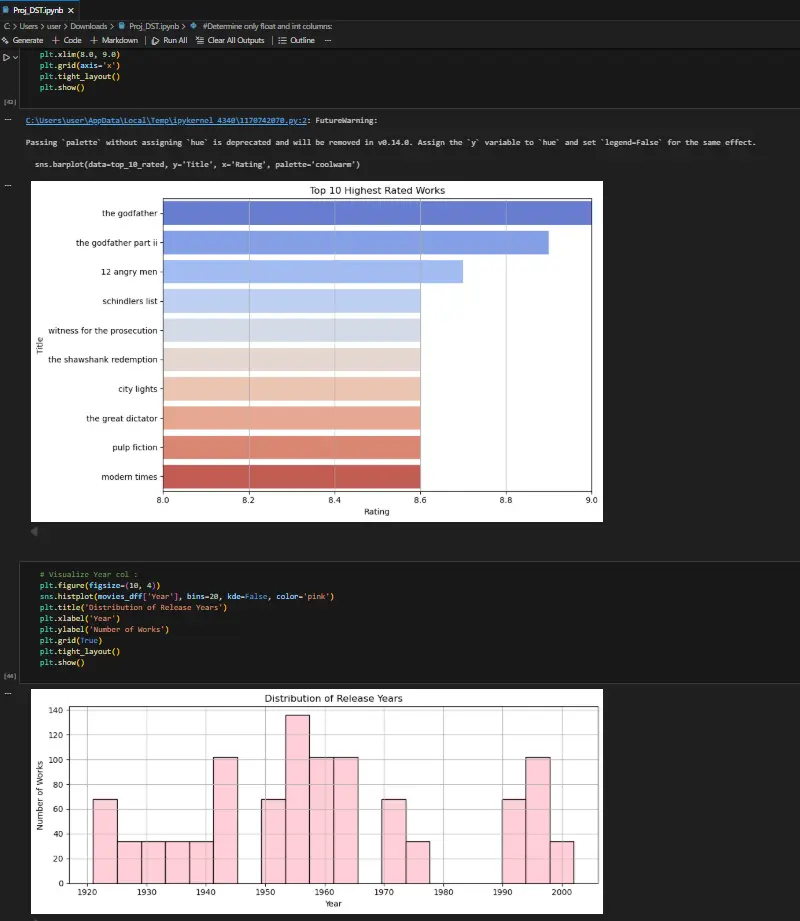
شراء الخدمة الآن














