شراء الخدمة الآن
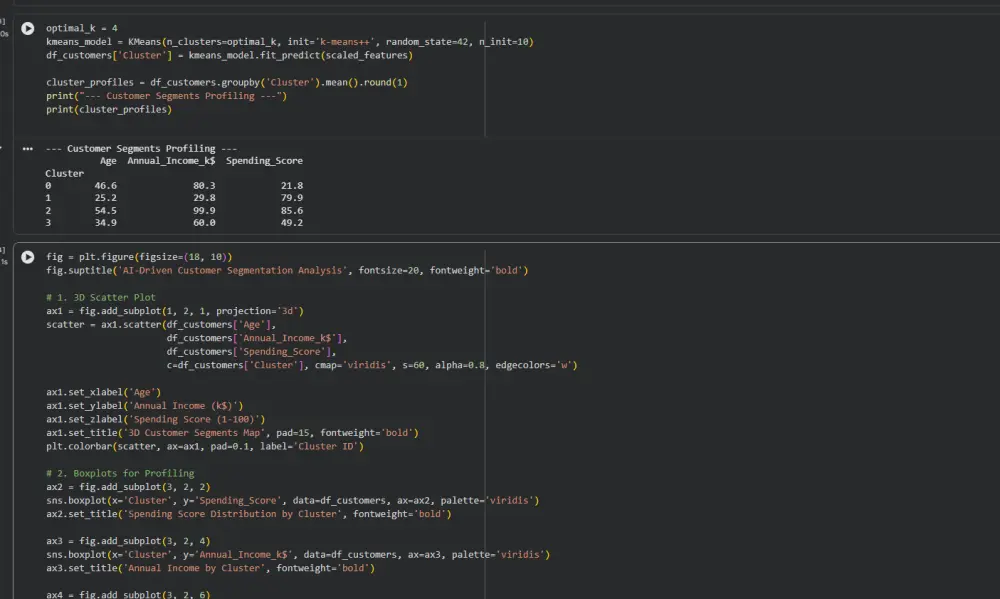
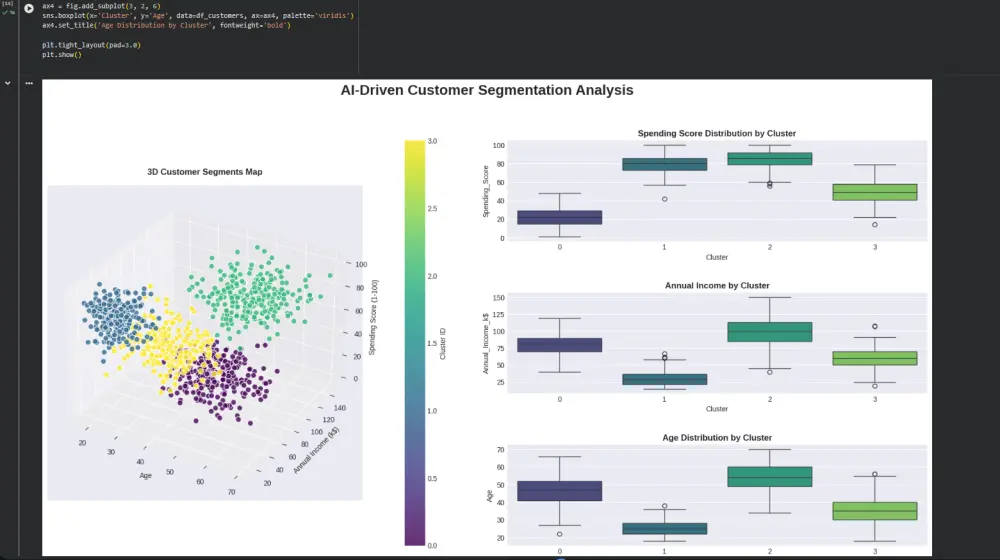
تحليل تقسيم العملاء باستخدام الذكاء الاصطناعي (AI-Driven Customer Segmentation Analysis)
شراء الخدمة
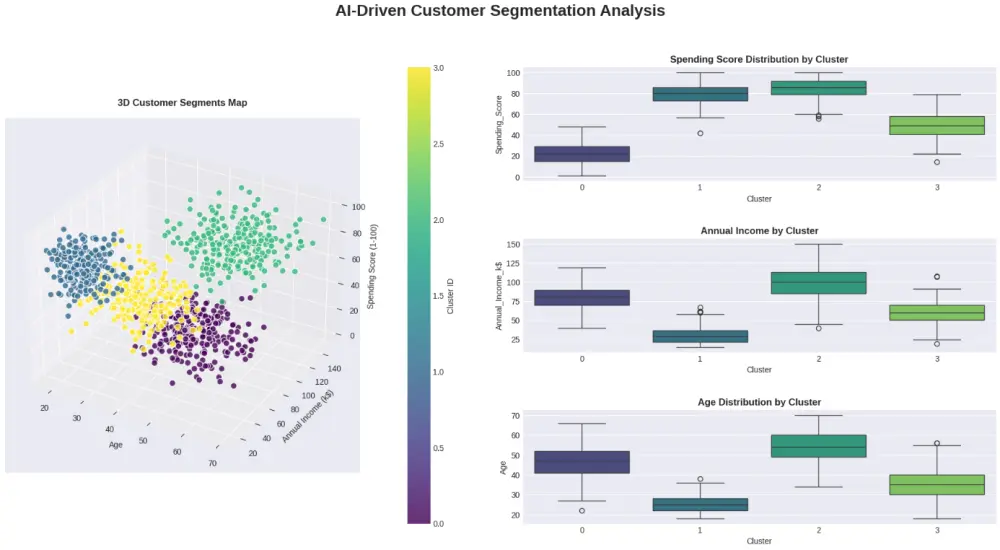
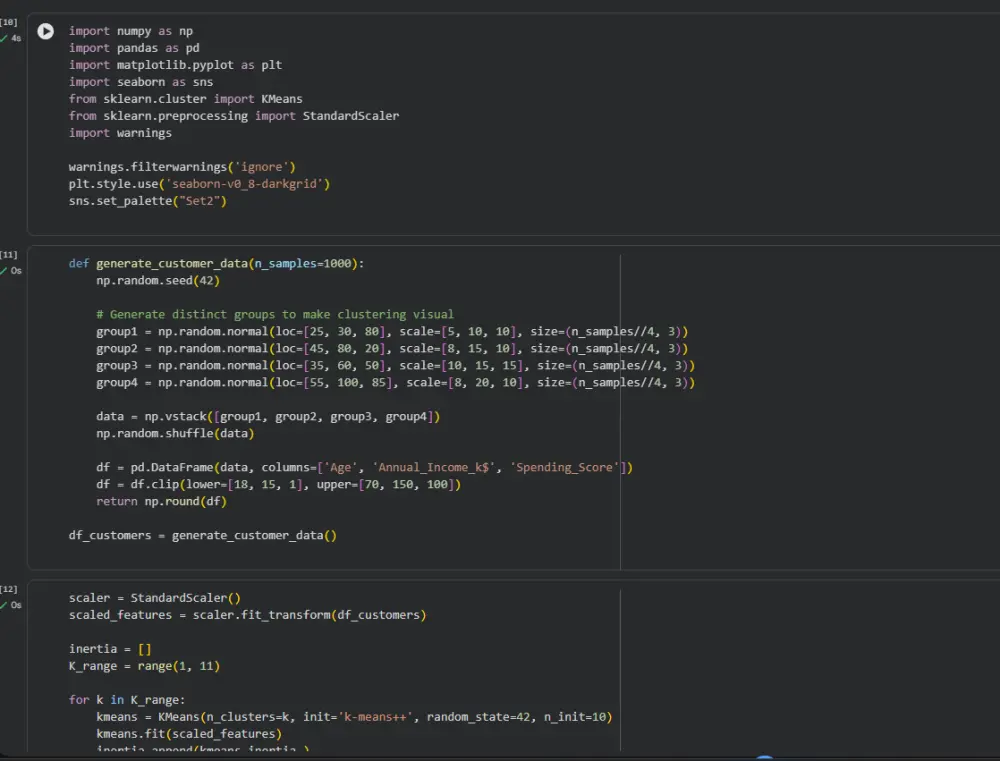
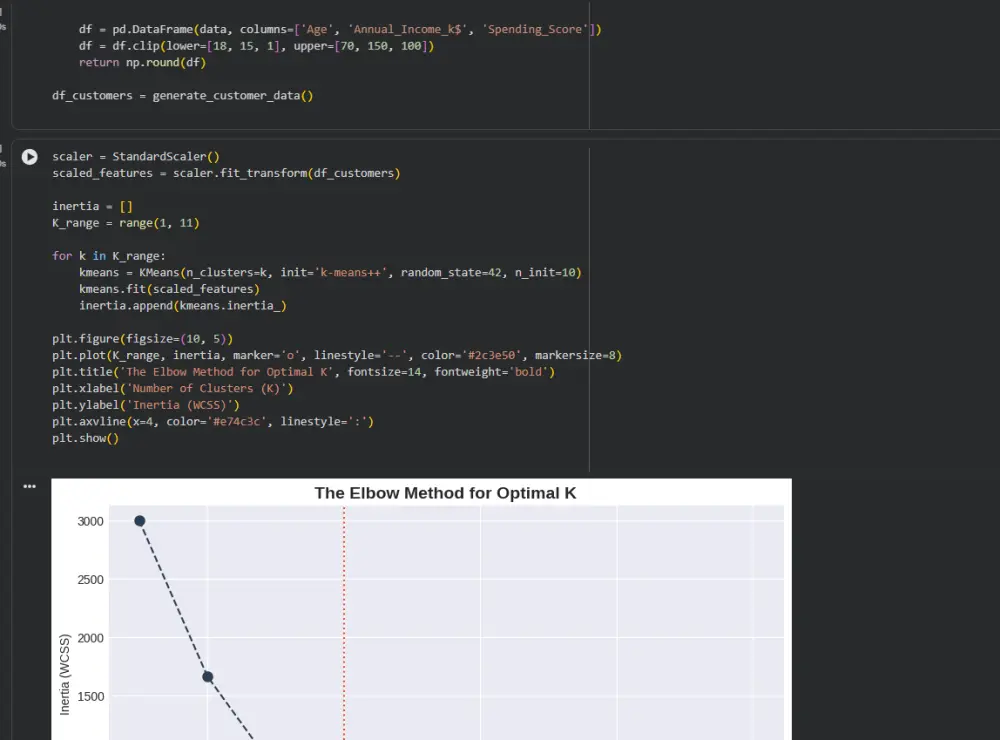
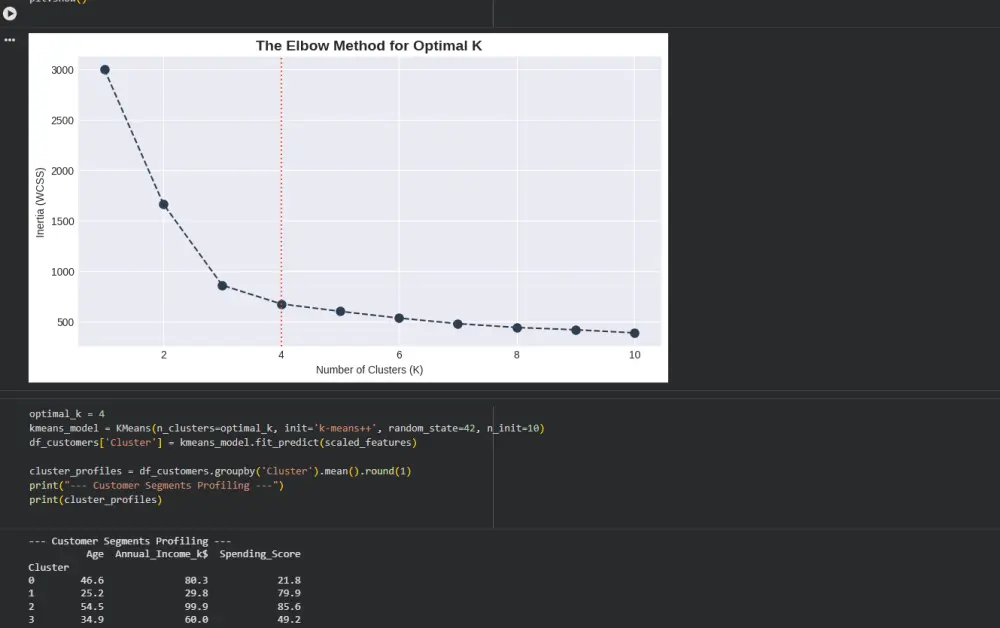
شراء الخدمة الآن
مهارات البائع
بطاقة الخدمة

شراء الخدمة الآن













