وصف الخدمة
أقدم خدمة Fine-Tuning لنماذج الذكاء الاصطناعي (LLM) لتخصيصها وفقًا لبياناتك ومجال عملك، مما يساعد على تحسين دقة الإجابات وفهم النموذج لسياق مشروعك بشكل أفضل. هذه الخدمة مناسبة لتطوير نماذج محادثات، تصنيف نصوص، تحليل تعليمات، أو مهام محددة حسب مجال عملك.
متطلبات البيانات
البيانات يجب أن تكون موجودة وجاهزة من طرف العميل قبل بدء العمل.
يمكن أن تكون البيانات في صورة: محادثات، مستندات نصية، بيانات تصنيف، أو بيانات تعليمات (Instruction Dataset).
الحد الأدنى المقترح للبيانات:
1000 مثال للمهام البسيطة
3000 – 5000 مثال للحصول على أداء جيد
10000 مثال للحصول على نتائج قوية ومستقرة
كلما كانت البيانات أكثر جودة وتنظيمًا، تحسن أداء النموذج بشكل أكبر.
نوع وحجم النماذج المتاحة
الحد الأقصى لحجم النموذج المتاح للتدريب هو 7B Parameters لضمان استقرار التدريب وكفاءة التشغيل اكثر من ذلك سيتحمل العميل السعر وقت التدريب.
أمثلة للنماذج التي يمكن تدريبها:
نماذج LLaMA-based
نماذج Mistral
نماذج Transformer مفتوحة المصدر مناسبة للمهام المختلفة
يتم اختيار النموذج الأنسب حسب نوع المهمة وحجم البيانات والنتائج المطلوبة.
ما الذي يتضمنه العمل:
1. تجهيز وتنظيف البيانات وتحويلها إلى صيغة مناسبة للتدريب
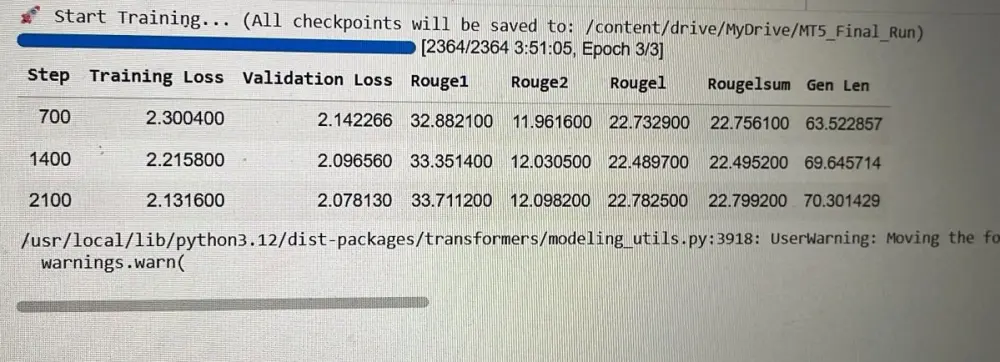
2. تنفيذ Fine-Tuning باستخدام تقنيات حديثة مثل **PEFT / LoRA**
3. تقييم أداء النموذج وتحسينه
4. تجهيز كود التشغيل (**Inference Script**) لاستخدام النموذج بسهولة
5. إمكانية توفير **FastAPI API** للنموذج لتشغيله داخل تطبيقك
التقنيات المستخدمة:
Python
Transformers
PEFT / LoRA
PyTorch
ما الذي سيستلمه العميل:
النموذج بعد Fine-Tuning كاملًا
جميع ملفات النموذج و Tokenizer
كود التشغيل (Inference Script)
إمكانية تشغيل النموذج عبر FastAPI API داخل تطبيقك
دليل تشغيل كامل يوضح طريقة الإعداد والاستخدام
مميزات الخدمة:
تنفيذ مخصص حسب احتياجات العميل
كود Python منظم وسهل التعديل (**Clean Code**)
اختيار أفضل Architecture وتقنيات مناسبة للمشروع
إمكانية التوسع والتطوير مستقبلاً بسهولة
الالتزام بالجودة وموعد التسليم