شراء الخدمة الآن
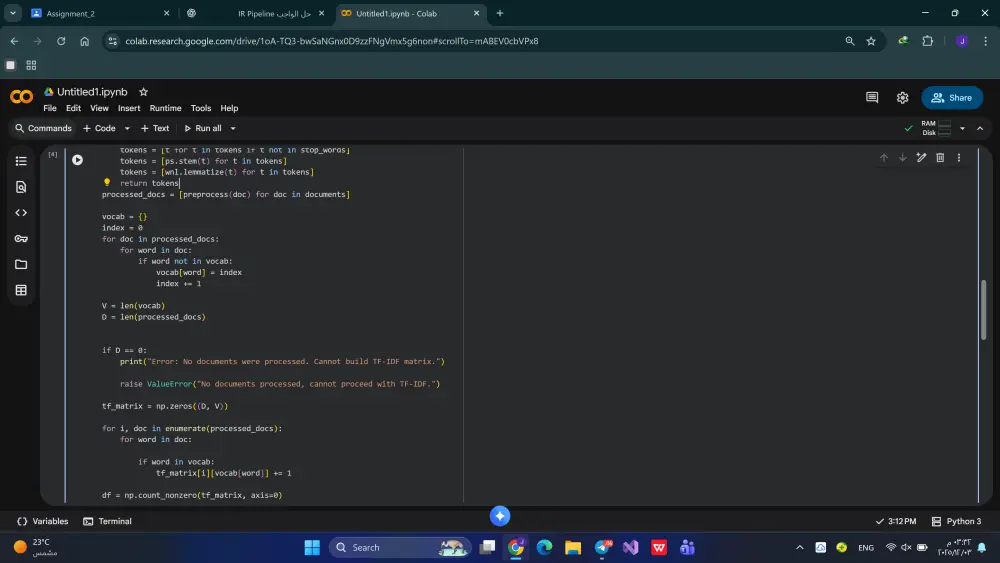
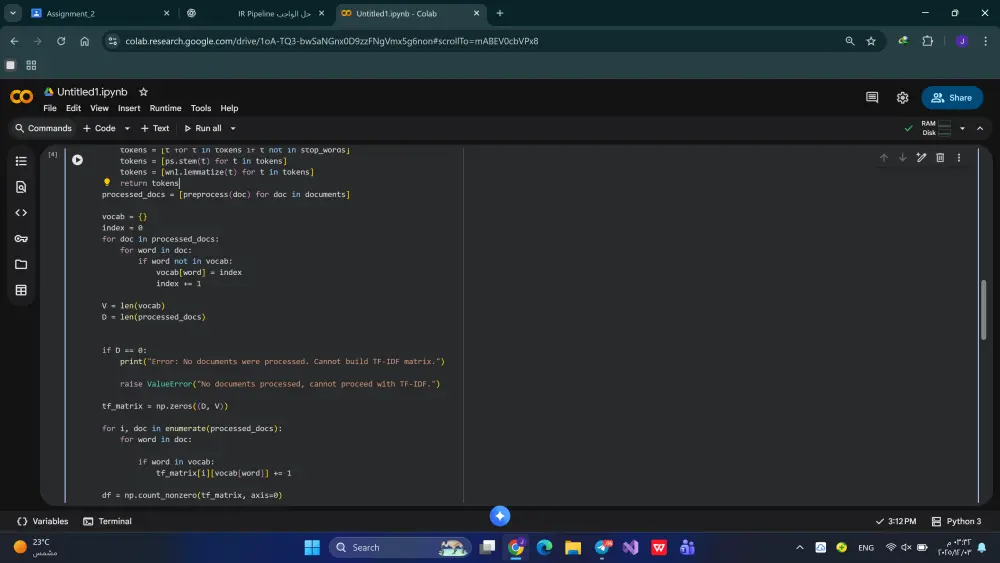
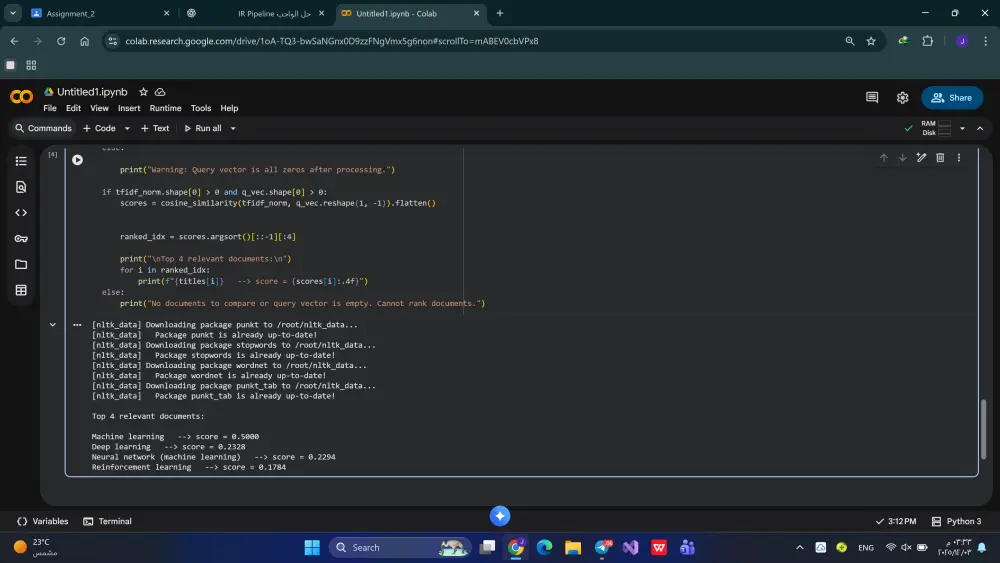
preprocessing
شراء الخدمة
شراء الخدمة الآن
مهارات البائع
بطاقة الخدمة

شراء الخدمة الآن














