Exploring-Data-Science-Tools
تفاصيل العمل
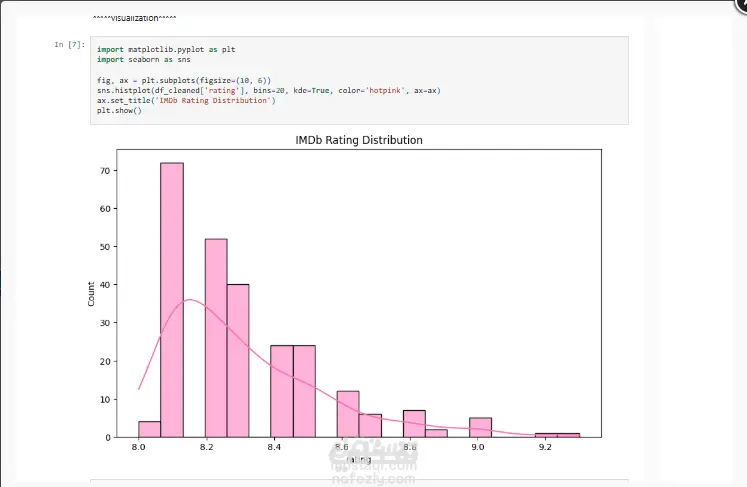
قمت بتطوير مشروع كامل لاستخراج وتحليل بيانات IMDb Top 250 Movies باستخدام بايثون مع تطبيق مراحل الـ Data Lifecycle بشكل متكامل: 1- Data Extraction (Web Scraping): الاعتماد على مكتبة Selenium لاستخراج بيانات الأفلام (العنوان – سنة الإصدار – التقييم) من موقع IMDb. حفظ البيانات في ملف CSV منظم. 2- Data Cleaning & Preprocessing: تنظيف البيانات باستخدام Pandas. تطبيق Regex لمعالجة العناوين (إزالة الرموز – تحديد أجزاء الأفلام/الأجزاء المكملة – التعامل مع الأرقام). كشف البيانات المكررة أو الناقصة. 3- Data Analysis: تحليل التوزيع العام للتقييمات. تحديد أكثر السنوات إنتاجًا لأفلام التوب 250. استخراج أقدم وأحدث الأفلام. إظهار أعلى وأقل الأفلام تقييمًا. تحليل الكلمات الأكثر تكرارًا في العناوين. حساب متوسط التقييم لكل سنة. 4- Data Visualization: رسوم بيانية باستخدام Matplotlib & Seaborn (Distribution, Barplots, Scatterplots). WordCloud يوضح أكثر الكلمات تكرارًا في العناوين. Pie chart لعرض نسبة الأفلام التي تحتوي على كلمة "Part". 5- Database Integration: تخزين البيانات النهائية في MongoDB لتسهيل الوصول إليها والتعامل معها في أي وقت. النتيجة: مشروع شامل بيجمع بين Web Scraping – Data Cleaning – Exploratory Data Analysis – Visualization – Database Management، وده يوضح خبرة قوية في التعامل مع البيانات من المصدر لحد تخزينها بشكل منظم.
مهارات العمل















