تطوير نظام ذكاء اصطناعي (OCR) لاستخراج النصوص من الصور بدقة عالية



تفاصيل العمل
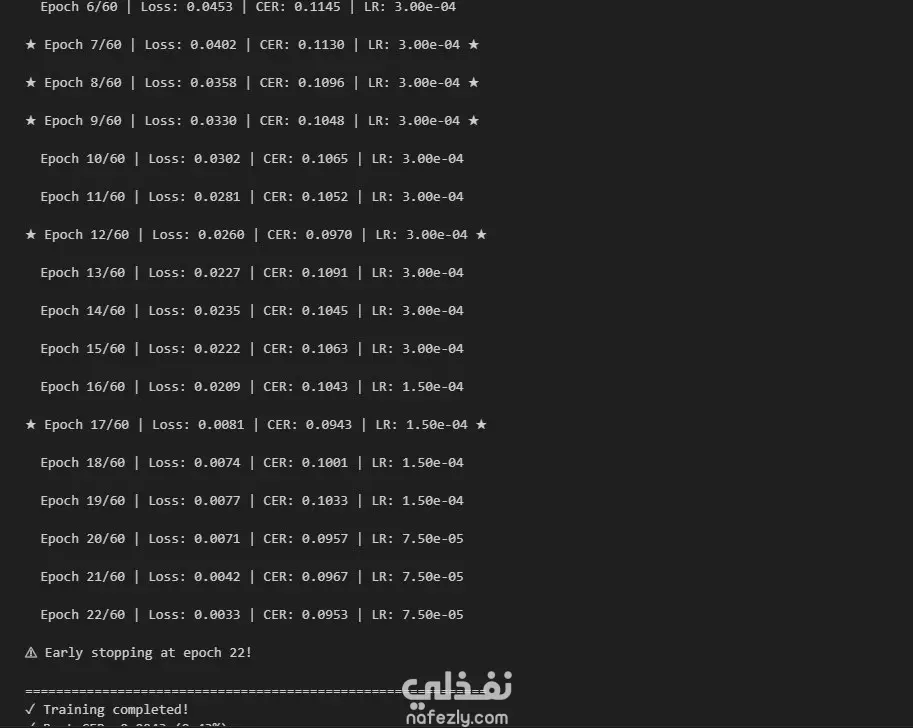
تطوير نظام متقدم يعتمد على تقنيات الرؤية الحاسوبية (Computer Vision) والتعلم العميق (Deep Learning) لاستخراج النصوص والبيانات الدقيقة (مثل تواريخ الصلاحية وأرقام التشغيلة) من ملصقات الأدوية المعقدة (Vignettes). 🏆 إنجاز استثنائي: بفضل دقة وكفاءة الخوارزميات المستخدمة، حصد هذا الحل البرمجي المركز الثالث في مسابقة عالمية لعلوم البيانات على منصة الكاغل (Kaggle). أبرز التقنيات والخصائص: • التعرف الضوئي على الحروف (OCR): بناء نموذج متقدم (ResNet34-Transformer) قادر على قراءة النصوص بأطوال متغيرة بدقة فائقة، مع تحقيق معدل خطأ منخفض جداً (CER < 0.10). • تعديل اتجاه الصور: تطوير مصنف (Classifier) لتصحيح اتجاه الصور تلقائياً بدقة تتجاوز 99% لضمان استخراج النص بشكل صحيح. • معالجة البيانات الضخمة: تطبيق تقنيات تحسين الصور (Data Augmentation) وتوليد أكثر من 30,000 صورة صناعية لرفع كفاءة النموذج وجعله قادراً على العمل في بيئات حقيقية وظروف إضاءة سيئة. القيمة العملية للشركات: هذا النظام ليس مجرد كود برمجي، بل هو حل عملي قابل للدمج (Integration) في تطبيقات الهواتف أو أنظمة نقاط البيع (POS) لأتمتة إدخال البيانات، تقليل الأخطاء البشرية، وتسريع سير العمل بشكل جذري.
مهارات العمل














