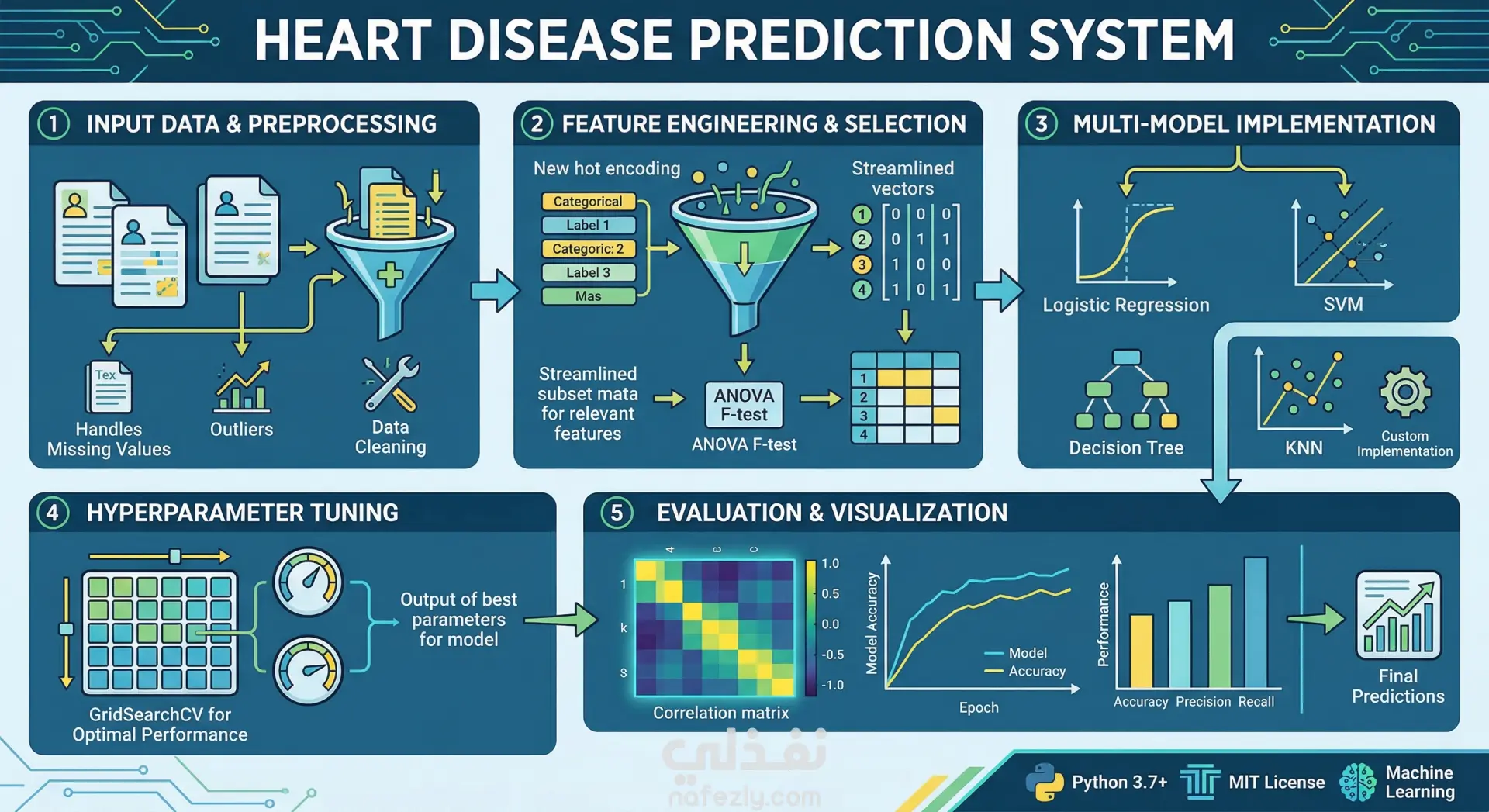
Data Preprocessing: Robust handling of clinical data, including missing value imputation, outlier detection, and data cleaning.
Feature Engineering: Implementation of one-hot encoding for categorical variables and derived feature creation to improve model signal.
Feature Selection: Statistical selection using ANOVA F-test to identify the most predictive clinical markers.
Multi-Model Framework: Comparative implementation of Logistic Regression, Support Vector Machines (SVM), Decision Trees, and K-Nearest Neighbors (KNN).
Custom KNN: Includes a bespoke K-Nearest Neighbors implementation built from the ground up using NumPy.
Hyperparameter Tuning: Systematic optimization via GridSearchCV to ensure maximum model performance.
Data Visualization: Automated generation of correlation matrices, feature importance plots, and model performance charts.