*ملخص مشروع تحليل البيانات (High-Performance Local Analytics)*
فكرة المشروع:
بناء نظام معالجة وتحليل بيانات (Data Pipeline) فائق السرعة يعمل بالكامل على الجهاز المحلي. المشروع يركز على استخدام أدوات حديثة مثل DuckDB و Parquet لتحليل ملايين السجلات من بيانات تاكسي نيويورك الحقيقية (NYC Taxi Data) بكفاءة تتخطى الطرق التقليدية بمرات مضاعفة.
*الأدوات والتقنيات (Tech Stack):*
* لغة البرمجة: Python (لربط أجزاء المشروع).
* محرك التحليل: DuckDB (أداة سريعة جداً لمعالجة البيانات الضخمة باستخدام SQL).
* صيغة التخزين: Apache Parquet (لتخزين البيانات بشكل مضغوط وذكي).
* واجهة العرض: Streamlit (لعمل لوحة بيانات/Dashboard تفاعلية).
*مراحل تنفيذ المشروع (4 مراحل):*
*1. مرحلة الإعداد وجلب البيانات (Setup & Ingestion):*
* تجهيز بيئة العمل بلغة بايثون وتثبيت المكتبات اللازمة.
* سحب بيانات رحلات التاكسي الحقيقية (ملفات CSV) من مصادرها الرسمية.
*2. مرحلة هندسة البيانات (ETL & Transformation):*
* تحويل البيانات من صيغة CSV البطيلة إلى صيغة Parquet السريعة.
* تنظيف البيانات باستخدام استعلامات SQL لاستبعاد السجلات غير الصحيحة.
*3. مرحلة التحليل وقياس الأداء (Analytics & Benchmarking):*
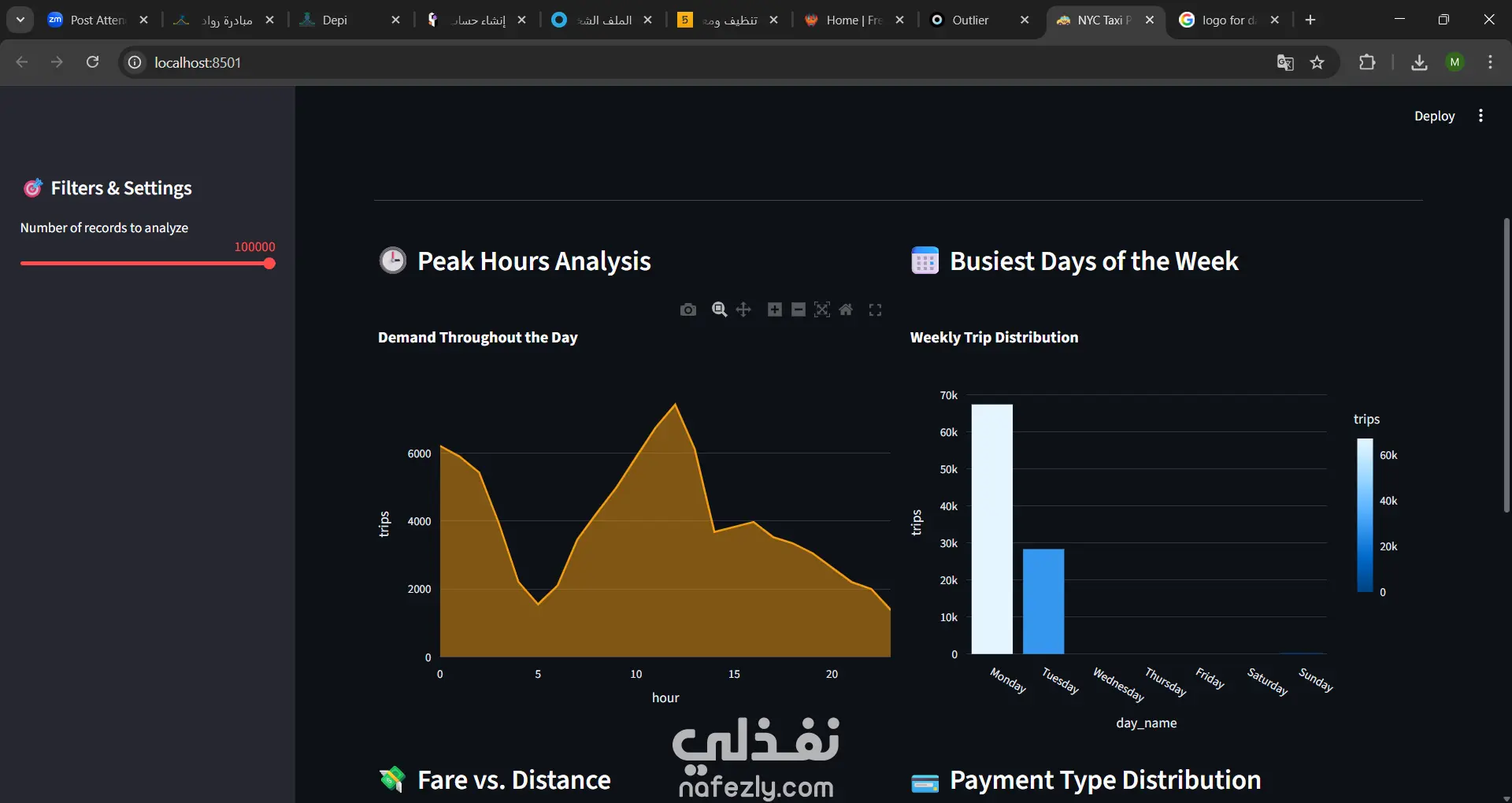
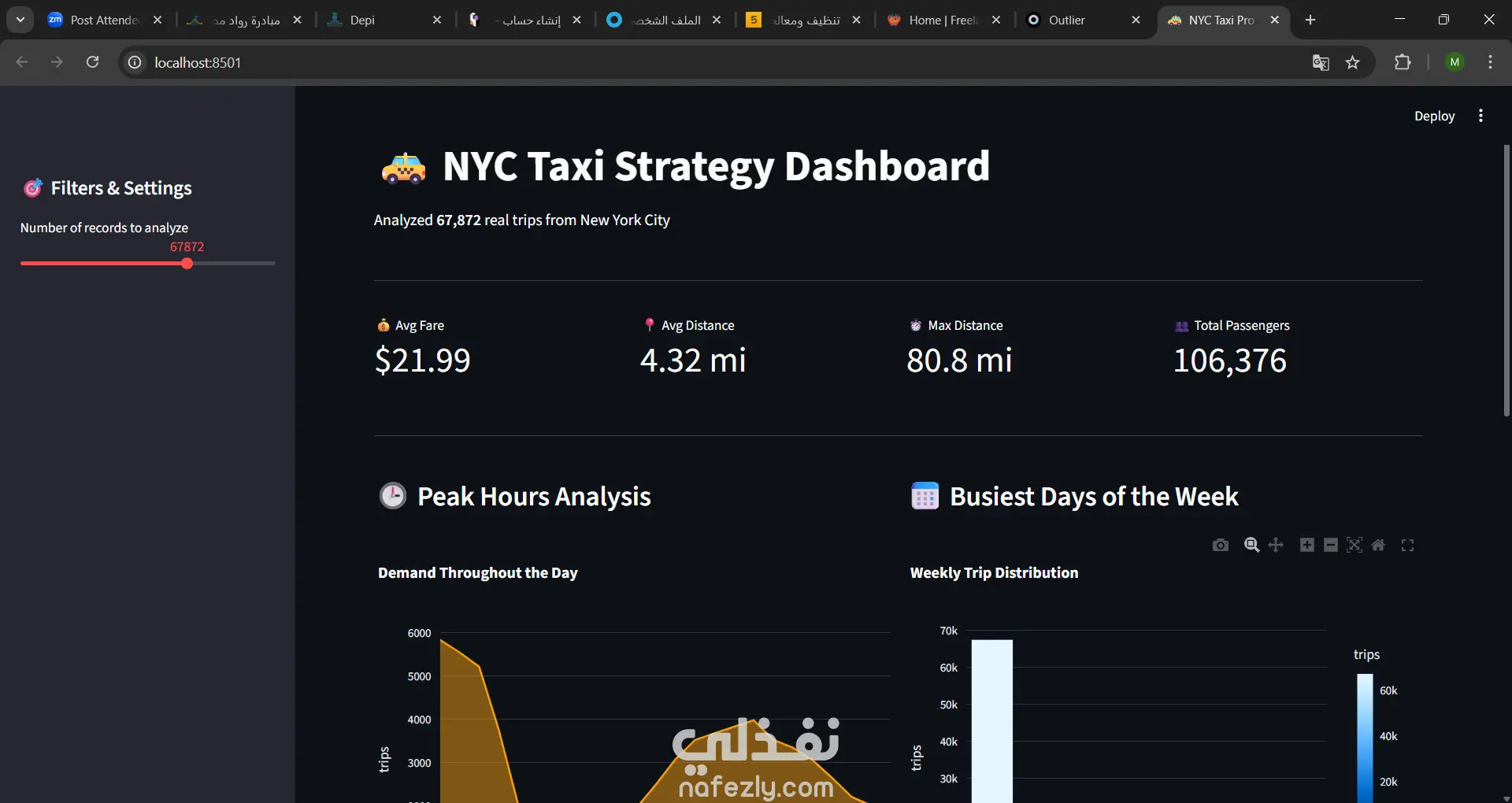
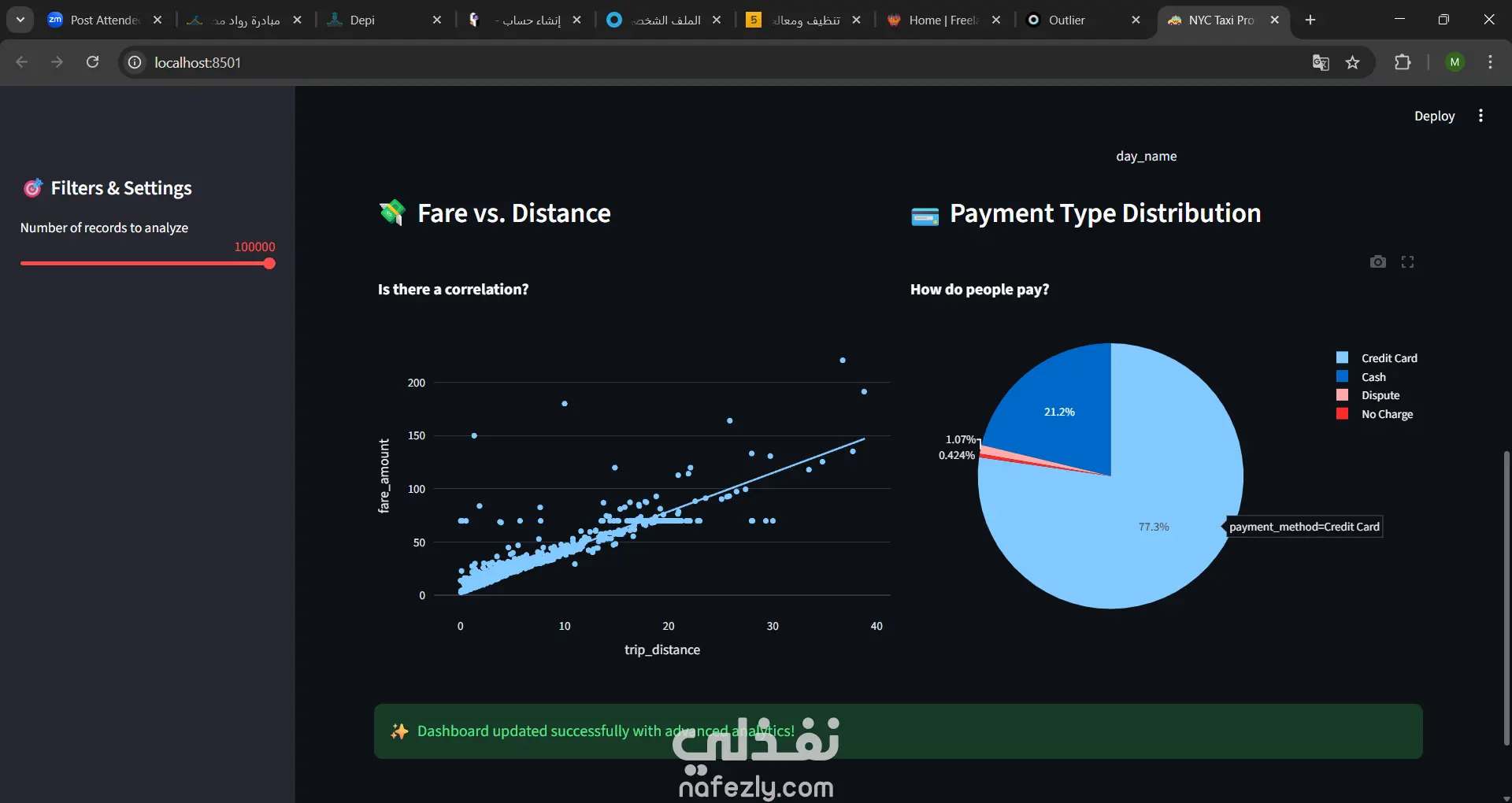
* كتابة استعلامات SQL لاستخراج نتائج (أوقات الذروة، الإيرادات، أشهر المناطق).
* عمل اختبار مقارنة (Benchmark) بين سرعة DuckDB وسرعة مكتبة Pandas التقليدية لتوثيق فرق الأداء.
*4. مرحلة العرض النهائي (Visualization):*
* تصميم لوحة بيانات تفاعلية تعرض النتائج في شكل رسوم بيانية جذابة.
* إضافة ميزة المقارنة الحية أمام المستخدم لإثبات سرعة النظام.
القيمة المضافة للمشروع:
المشروع لا يكتفي بعرض البيانات فقط، بل يقدم حلاً هندسياً لمشكلة "بطء معالجة البيانات الكبيرة على الأجهزة العادية"، ويستبدل الأدوات التقليدية بأدوات الجيل القادم في هندسة البيانات.