This project explores efficient fine-tuning techniques for large language models with the goal of adapting pretrained models to new instruction-following tasks while minimizing computational cost and memory usage.
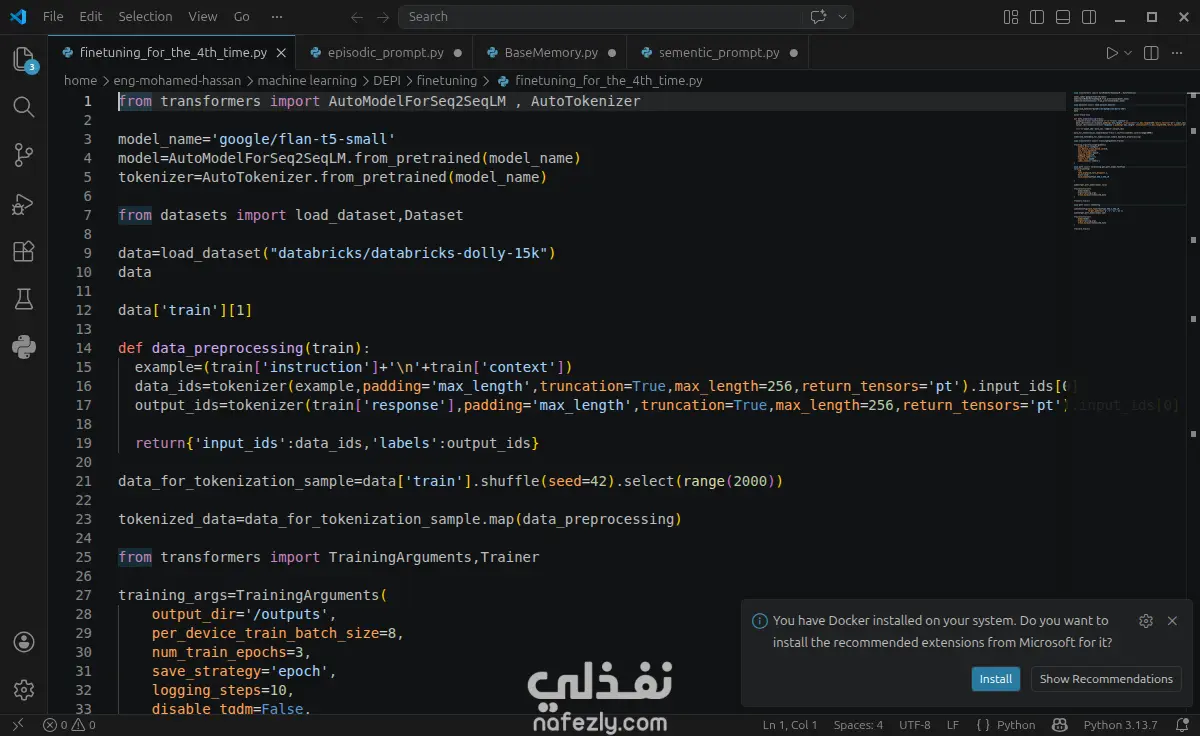
Using the FLAN-T5-small model as the base architecture, the project fine-tunes the model on the Databricks Dolly 15K instruction dataset, which contains high-quality instruction–response pairs designed to train conversational and task-oriented AI systems.
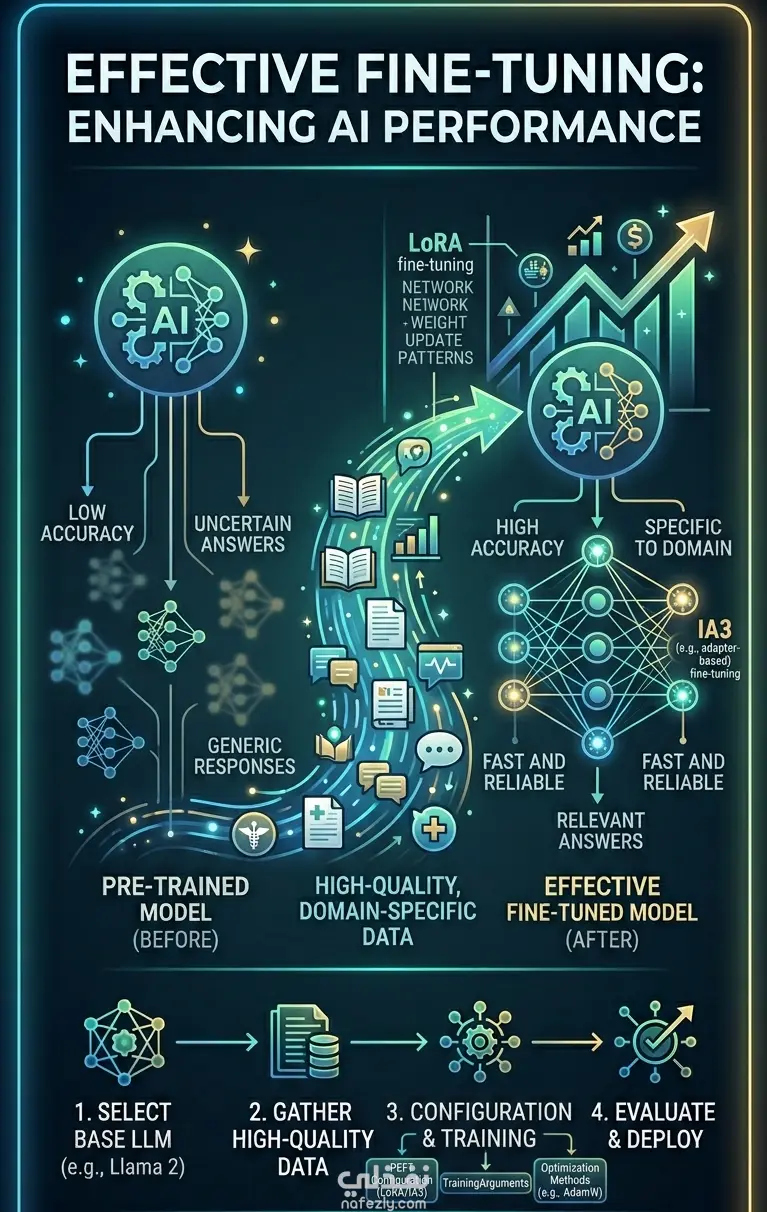
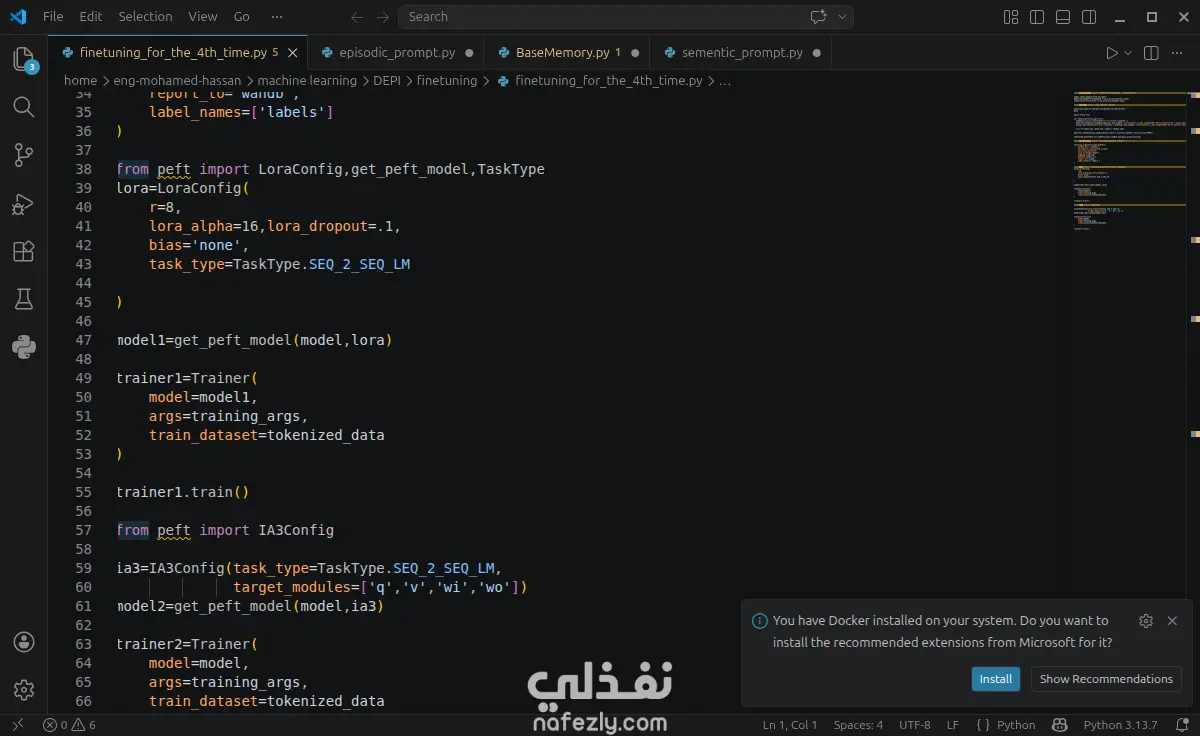
Instead of relying on full model fine-tuning, this project focuses on Parameter-Efficient Fine-Tuning (PEFT) approaches, specifically:
LoRA (Low-Rank Adaptation)
IA³ (Infused Adapter by Inhibiting and Amplifying Inner Activations)
These techniques enable training only a small subset of additional parameters while keeping the majority of the pretrained model weights frozen. This significantly reduces:
GPU memory requirements
Training time
Storage costs for model checkpoints
The pipeline includes:
Dataset loading and preprocessing
Tokenization and sequence formatting for instruction tuning
Implementation of PEFT methods using the Hugging Face Transformers and PEFT libraries
Model training with the Trainer API
Experiment tracking during training
The main objective of this project is to compare and demonstrate efficient strategies for adapting large language models to new tasks without the need for expensive full-scale retraining, making fine-tuning more accessible and scalable.