Three experiment stages
Step 1 - Train a FastText model from scratch on Yelp tips
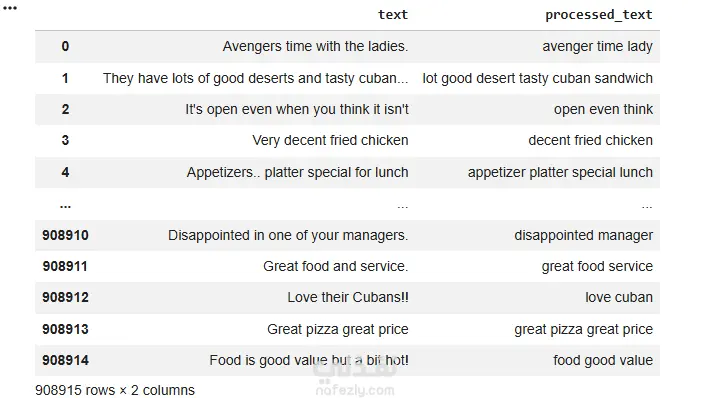
A new FastText model is trained directly on the processed Yelp sentences. Because the corpus is domain
specific and relatively short in style, this model tends to capture Yelp-specific associations well, but it
also shows noise for less frequent or more abstract words.
Step 2 - Use a pretrained English FastText model
The notebook downloads and loads a generic English FastText model (cc.en.100.bin). This model gives
semantically cleaner neighbours for many general words because it was trained on a much broader
corpus.
Step 3 - Fine-tune the pretrained model on Yelp tips
The pretrained FastText model is updated with the Yelp sentences. This keeps some general-language
knowledge, but after fine-tuning the nearest neighbours often become dominated by very similar surface
forms or domain-specific spelling variants.