قمت بتطوير سكريبت متكامل باستخدام لغة Python لسحب البيانات من موقع وكالة الأنباء العالمية (AP News). المشروع يهدف إلى تحويل المحتوى غير المنظم في صفحات الويب إلى قاعدة بيانات هيكلية يمكن الاعتماد عليها في التحليل أو الأرشفة.
المهام:
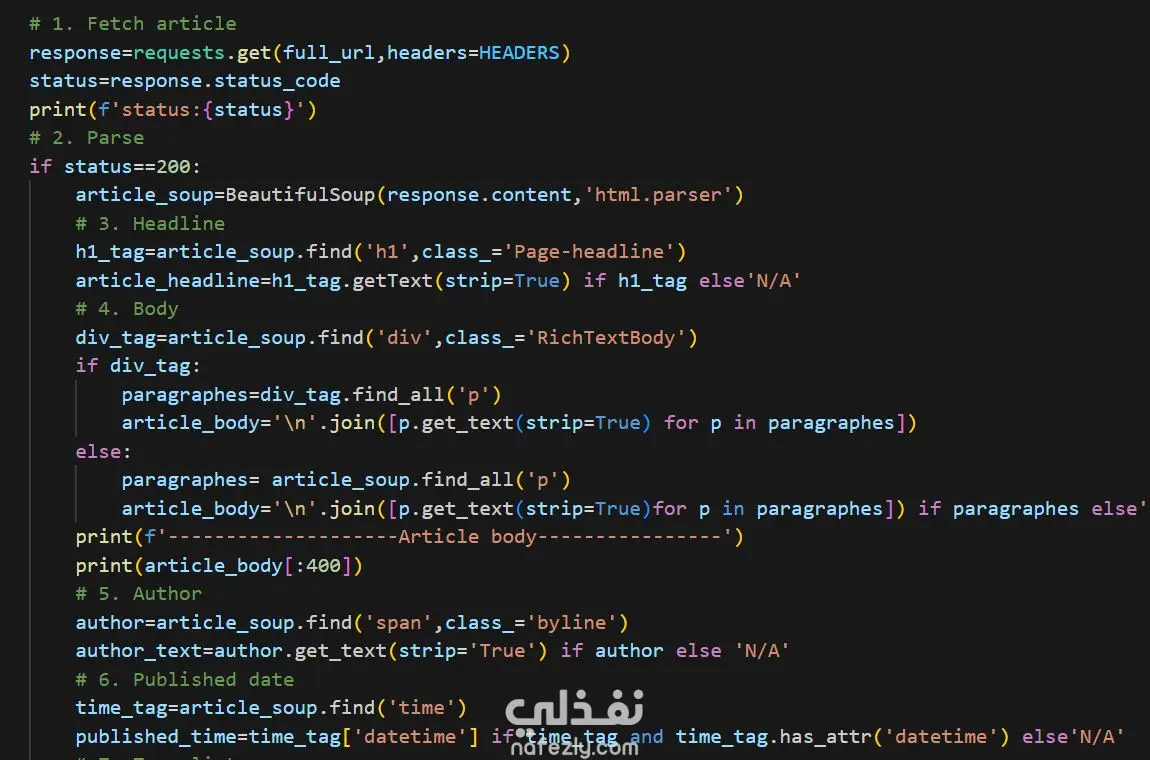
التعامل مع الطلبات (Requests): برمجة السكريبت لإرسال طلبات HTTP مع استخدام (Headers) لمحاكاة المتصفح وتجنب الحظر.
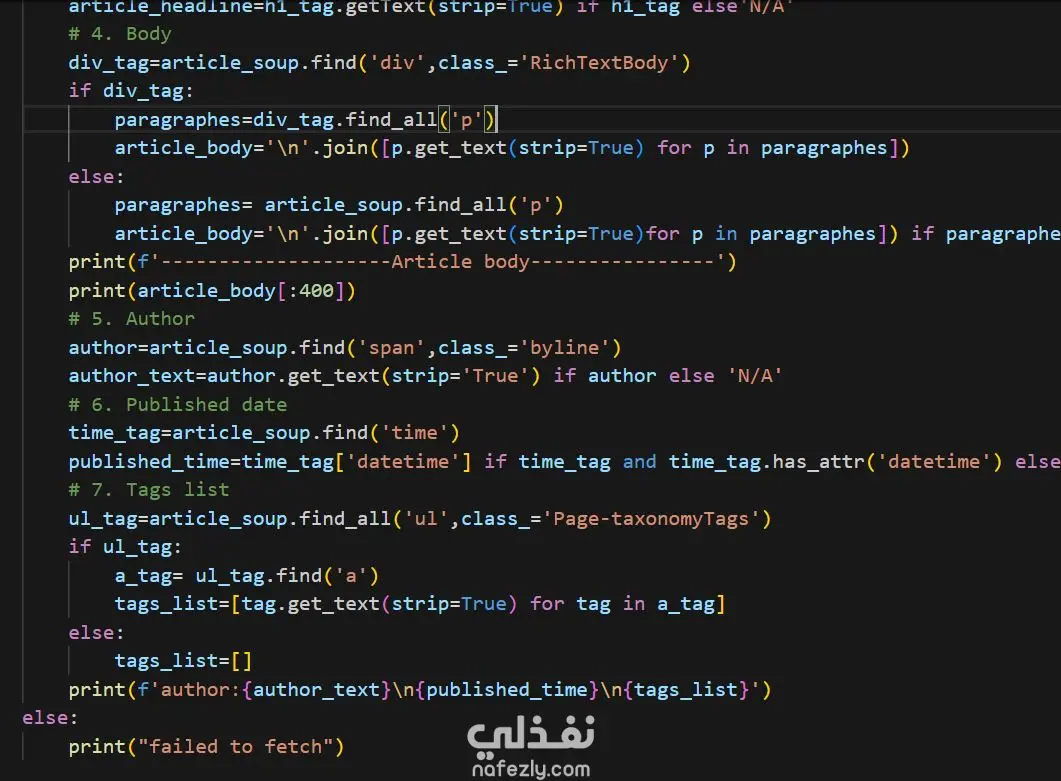
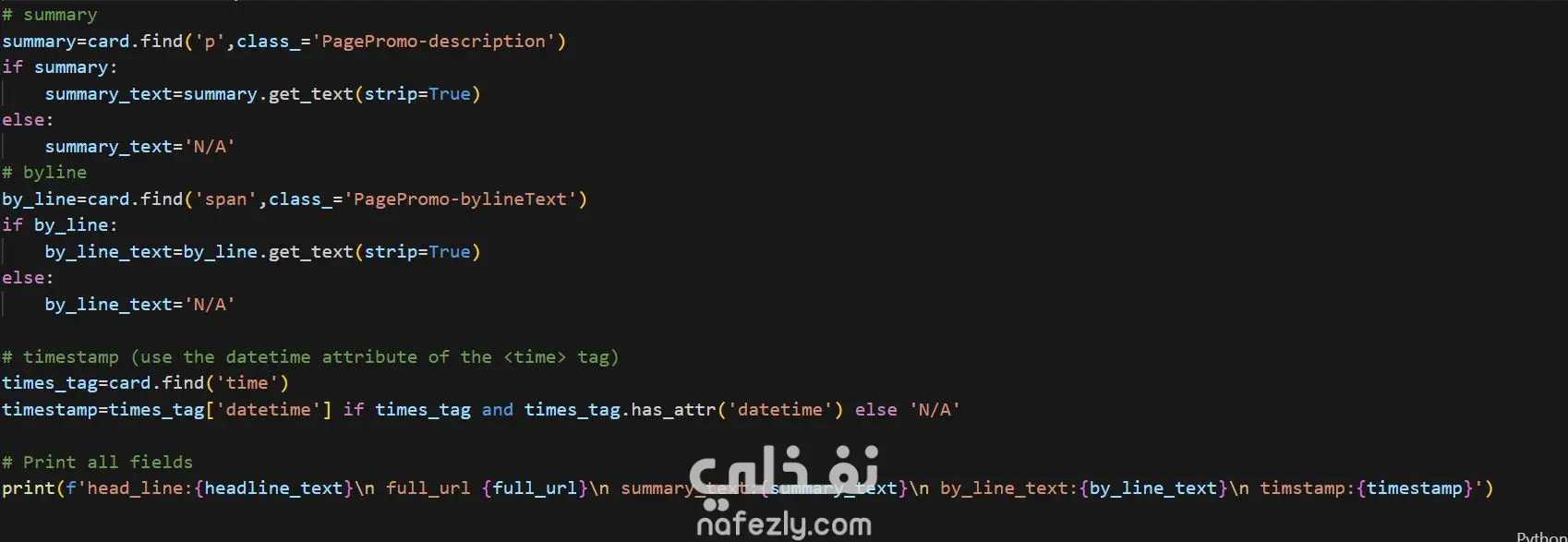
تحليل المحتوى (Parsing): استخدام مكتبة BeautifulSoup لاستخراج عناصر دقيقة (العناوين، نص المقال الكامل، الكلمات المفتاحية).
معالجة النصوص (Text Processing): تنظيف النصوص المستخرجة باستخدام strip=True ودمج الفقرات (join) لضمان الحصول على نص نقي.
استخراج الميتا داتا: سحب التواريخ بدقة من خاصية datetime واسم الكاتب (Byline) والوسوم (Tags).
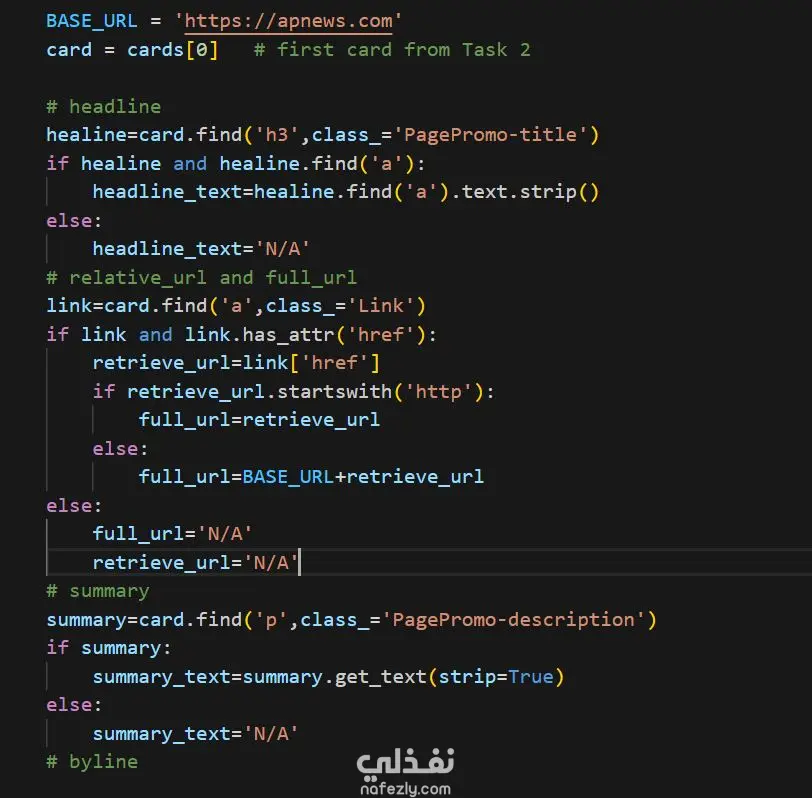
التعامل مع الروابط: برمجة منطق ذكي لتحويل الروابط النسبية (Relative URLs) إلى روابط كاملة (Full URLs) تلقائياً.
النتائج اللى حققتها:
استخراج آلاف المقالات وتصنيفها في ثوانٍ معدودة.
توفير ملفات (CSV/Excel) منظمة جاهزة للتحليل المباشر.
كود برمجي مرن يمكن تعديله ليعمل على مواقع إخبارية أخرى بسهول