Adaptive Synthetic Data Augmentation Toolkit
تفاصيل العمل
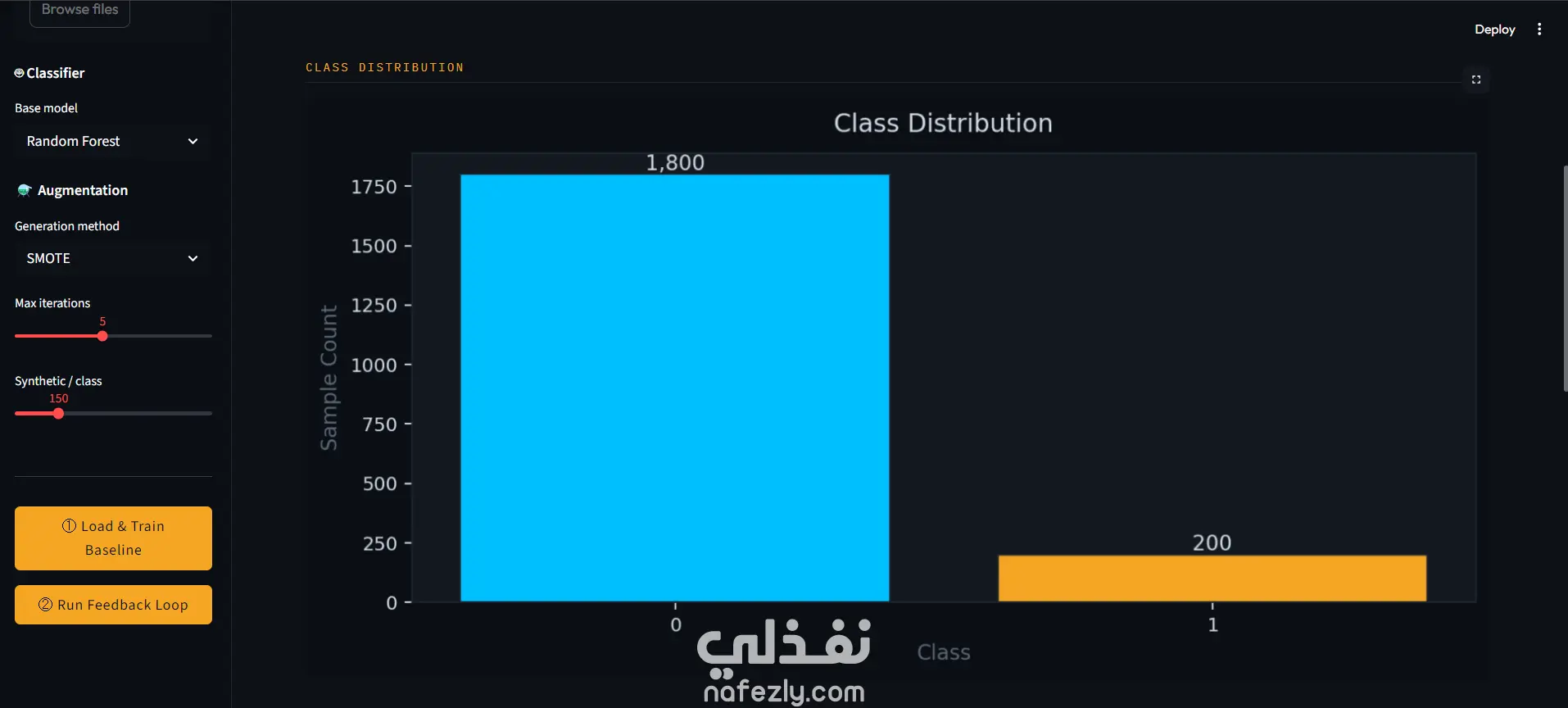
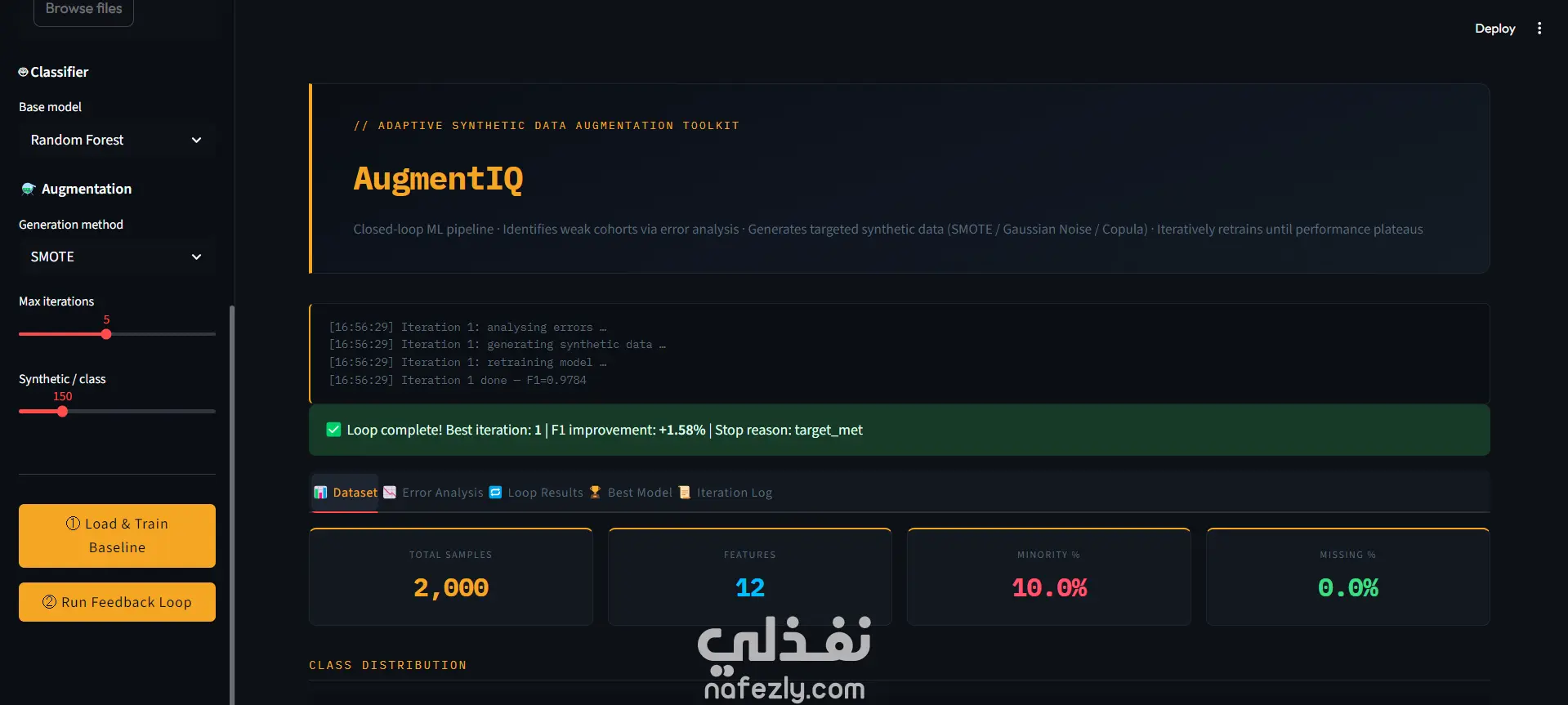
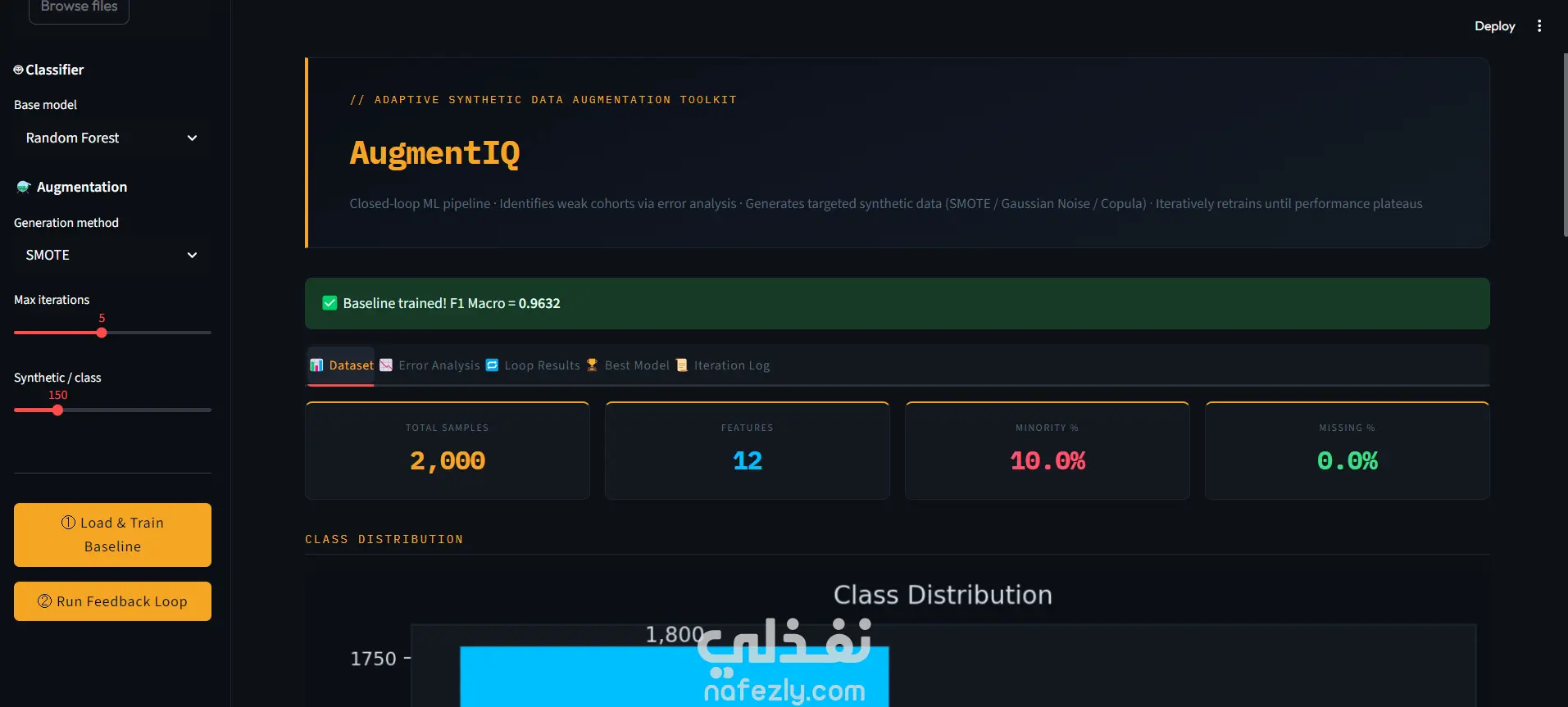
تُعدّ AugmentIQ مجموعة أدوات متقدمة لمعالجة واحدة من أهم مشكلات التعلم الآلي: شُح البيانات واختلال توازن الفئات في البيانات الجدولية. تظهر هذه المشكلة بوضوح في مجالات مثل الرعاية الصحية (حيث الأمراض النادرة قليلة)، كشف الاحتيال (نسبة ضئيلة جداً من العمليات)، والصيانة التنبؤية (أعطال نادرة). في هذه الحالات، تميل النماذج التقليدية إلى تجاهل الفئة النادرة لأنها تحقق دقة ظاهرية أعلى، رغم أن ذلك يؤدي إلى نتائج خطيرة عملياً. على عكس الأساليب التقليدية مثل SMOTE أو ضبط الأوزان، التي تعالج المشكلة بشكل ثابت، يعتمد AugmentIQ على زيادة تكيفية مدفوعة بالتغذية الراجعة. أي أنه لا يضيف بيانات عشوائياً، بل يحدد أولاً أين يفشل النموذج، ثم يولّد بيانات تستهدف هذه الأخطاء تحديداً. يتكوّن النظام من عدة وحدات مترابطة: معالجة البيانات: توليد بيانات شبيهة بالواقع، تنظيفها، وترميزها وتقسيمها مع الحفاظ على التوازن. النموذج الأساسي: تدريب مصنّف وحساب مقاييس مثل الدقة وF1 وROC-AUC. تحليل الأخطاء: تحديد الفئات ذات الأداء الضعيف (مثلاً إذا تجاوز الخطأ 30%) وتحليل أسباب الفشل. التوليد الاصطناعي: باستخدام SMOTE، أو الضوضاء الغاوسية، أو نماذج كوبولا لإنتاج بيانات واقعية. حلقة التغذية الراجعة: تعيد تدريب النموذج بشكل تكراري مع بيانات محسّنة، وتطبّق التوقف المبكر عند استقرار الأداء. أهم مساهمة في AugmentIQ هي الاستهداف الذكي للزيادة بدلاً من التوليد العشوائي، مما يحسّن أداء النموذج بشكل فعلي وليس شكلي. كما يضمن النظام تجنب الإفراط في التعلم من البيانات الاصطناعية عبر آلية توقف مبكر. معيار النجاح هو تحقيق تحسن لا يقل عن 10% في F1 على بيانات الاختبار، إضافة إلى تحسين استرجاع الفئة النادرة — وهو الأهم في التطبيقات الحساسة. كما يوفر النظام شفافية كاملة عبر تسجيل كل خطوة، مما يجعله أداة قوية وقابلة لإعادة الاستخدام في أي مشكلة تصنيف غير متوازن.
مهارات العمل
بطاقة العمل

طلب عمل مماثل












