جمع البيانات (Web Scraping) واستخراجها إلى ملفات Excel احترافية
تفاصيل العمل
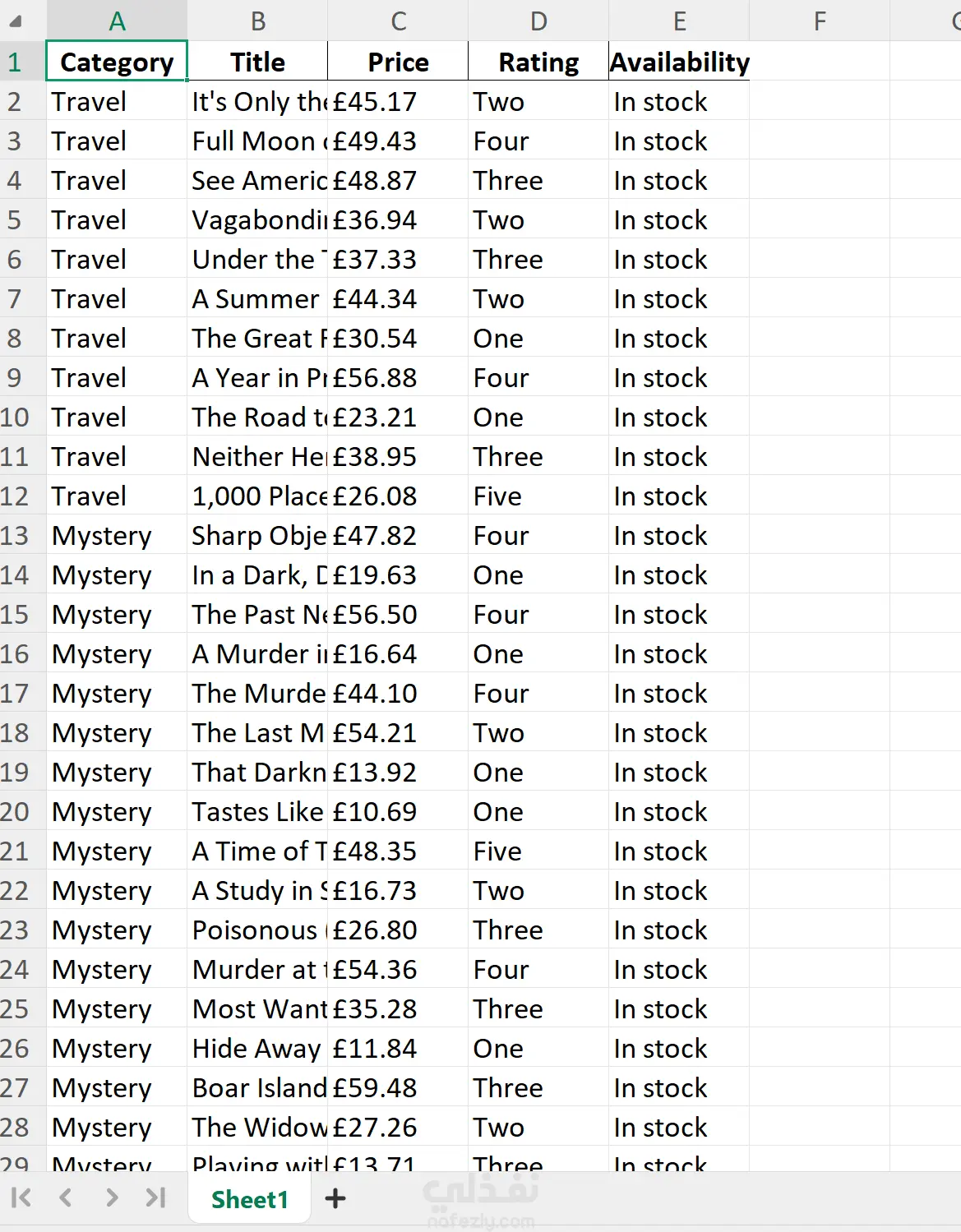
هيكلة البيانات: استخراج تصنيفات الكتب (Categories) ديناميكياً والتنقل داخل كل قسم على حدة. التعامل مع الصفحات (Pagination): برمجة منطق ذكي للانتقال بين الصفحات (Next Button) لضمان سحب كافة البيانات مهما كان عددها. استخراج تفاصيل دقيقة: سحب (عنوان الكتاب، السعر، التقييم، حالة التوفر، والقسم التابع له). تنظيم البيانات: تحويل البيانات الخام من HTML إلى هيكل بيانات منظم باستخدام مكتبة Pandas. المخرجات: تصدير البيانات النهائية إلى ملف Excel (.xlsx) احترافي جاهز للتحليل. الأدوات المستخدمة (Tech Stack): BeautifulSoup & Requests: للتعامل مع طلبات الويب وتحليل محتوى الصفحات. LXML: كمحلل (Parser) سريع وعالي الأداء. Pandas: لإدارة الجداول وتصدير الملفات.
مهارات العمل











