تحليل سلوك العملاء والتنبؤ بالتسرب باستخدام خوارزميات تعلم الآلة

تفاصيل العمل
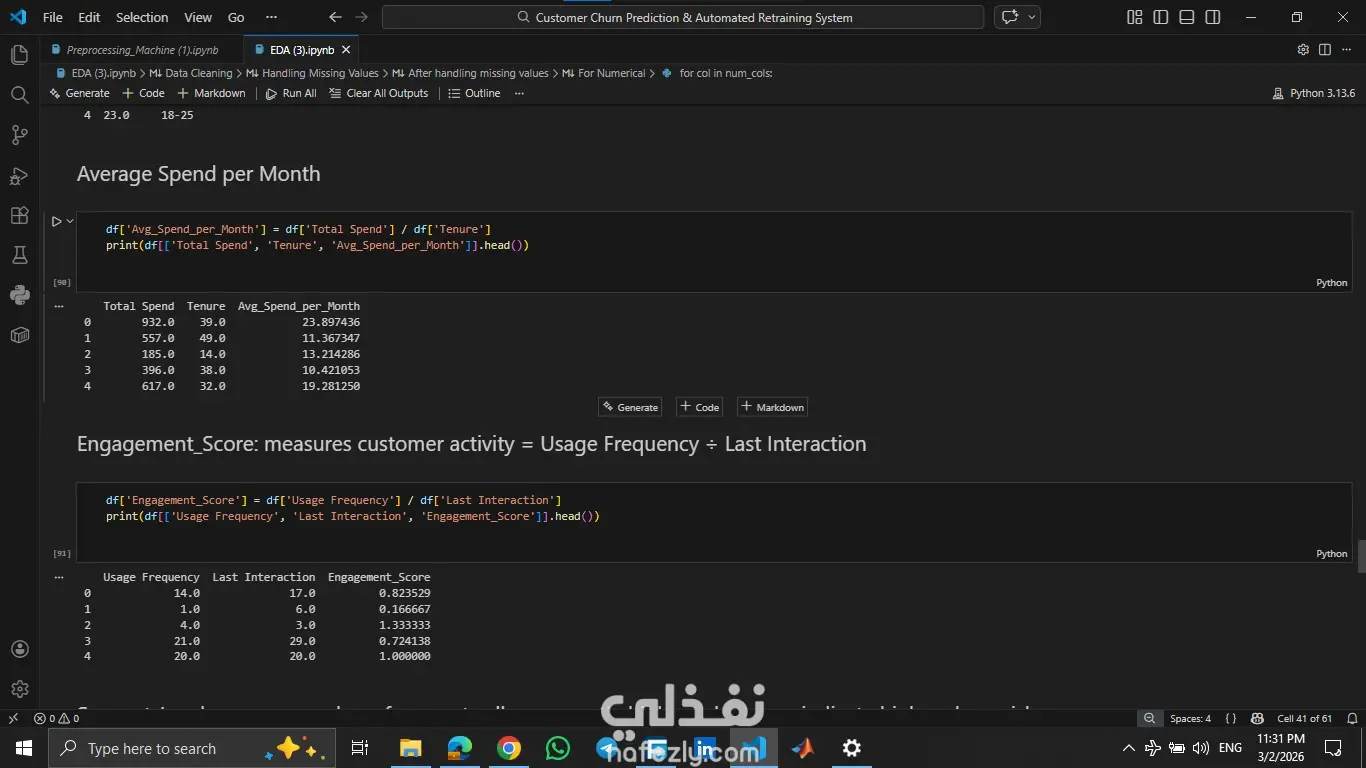
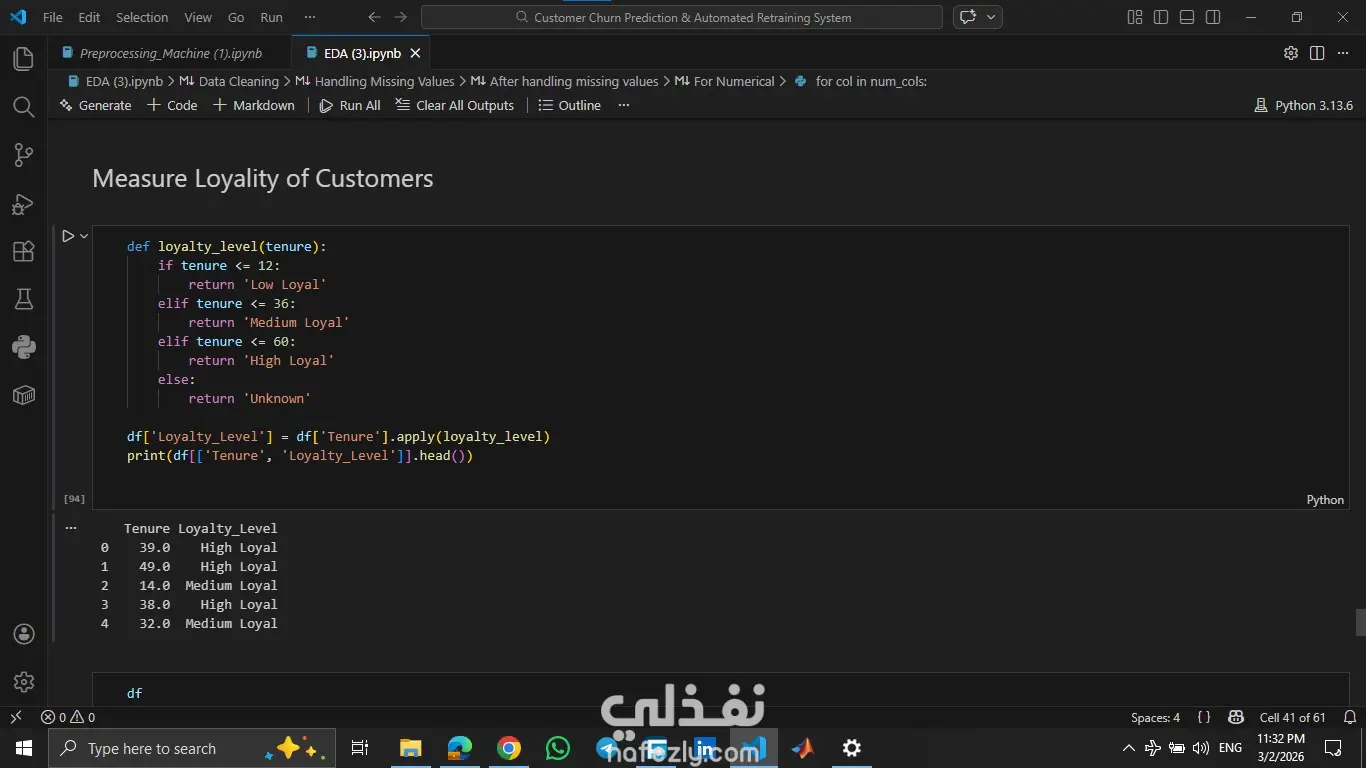
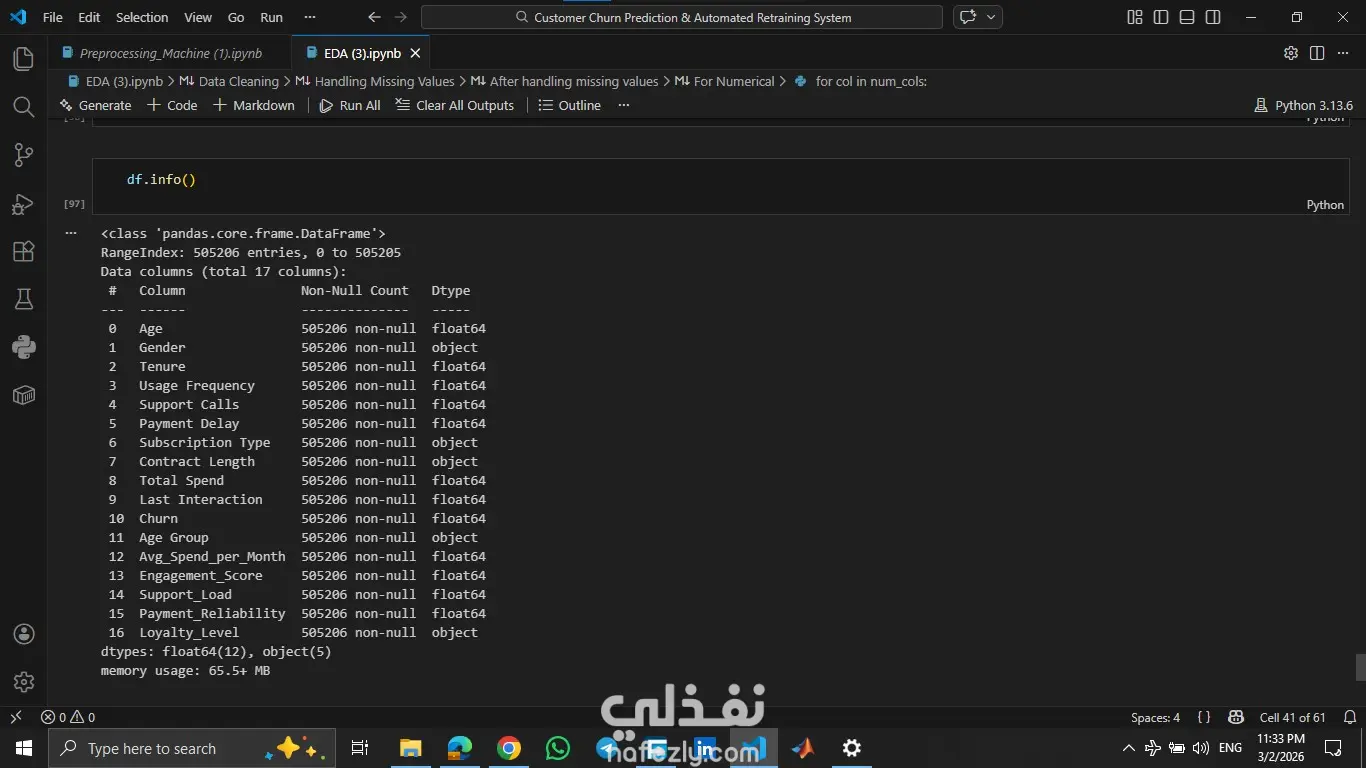
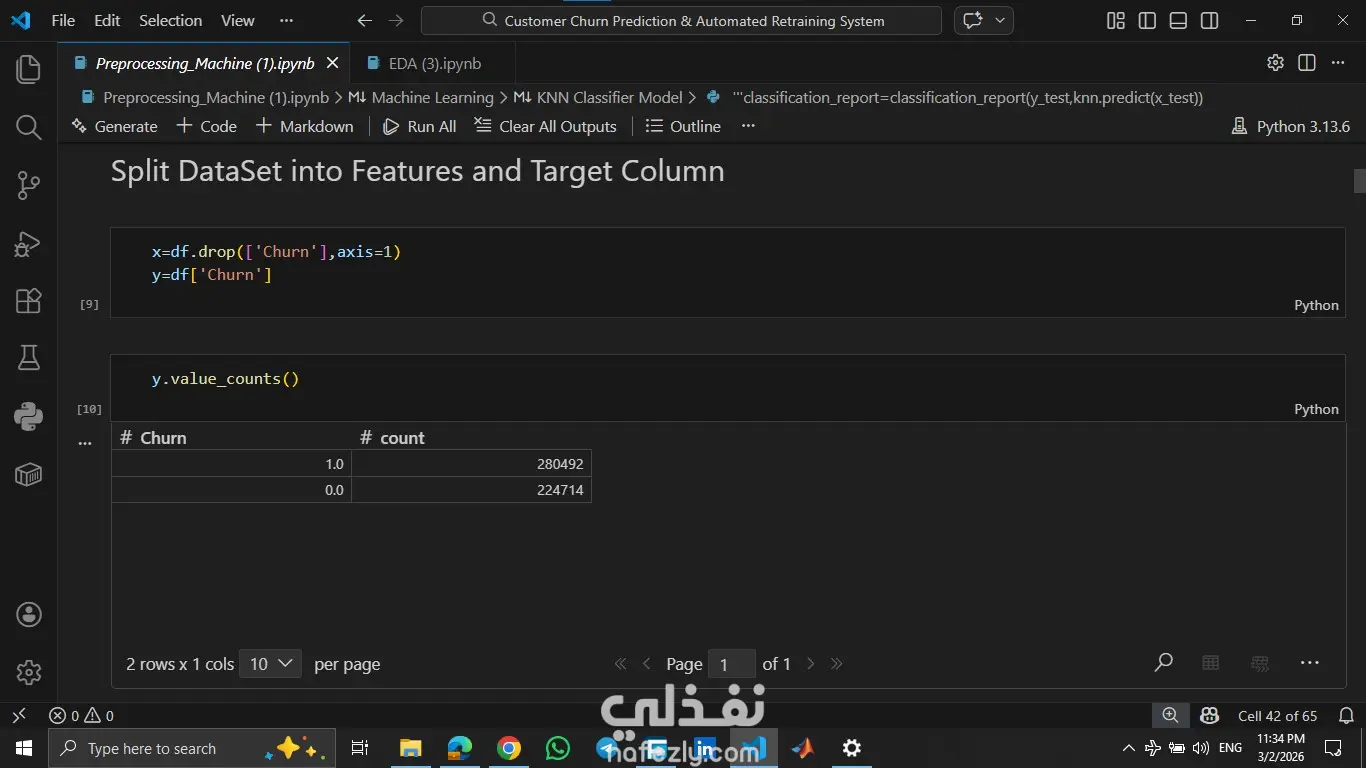
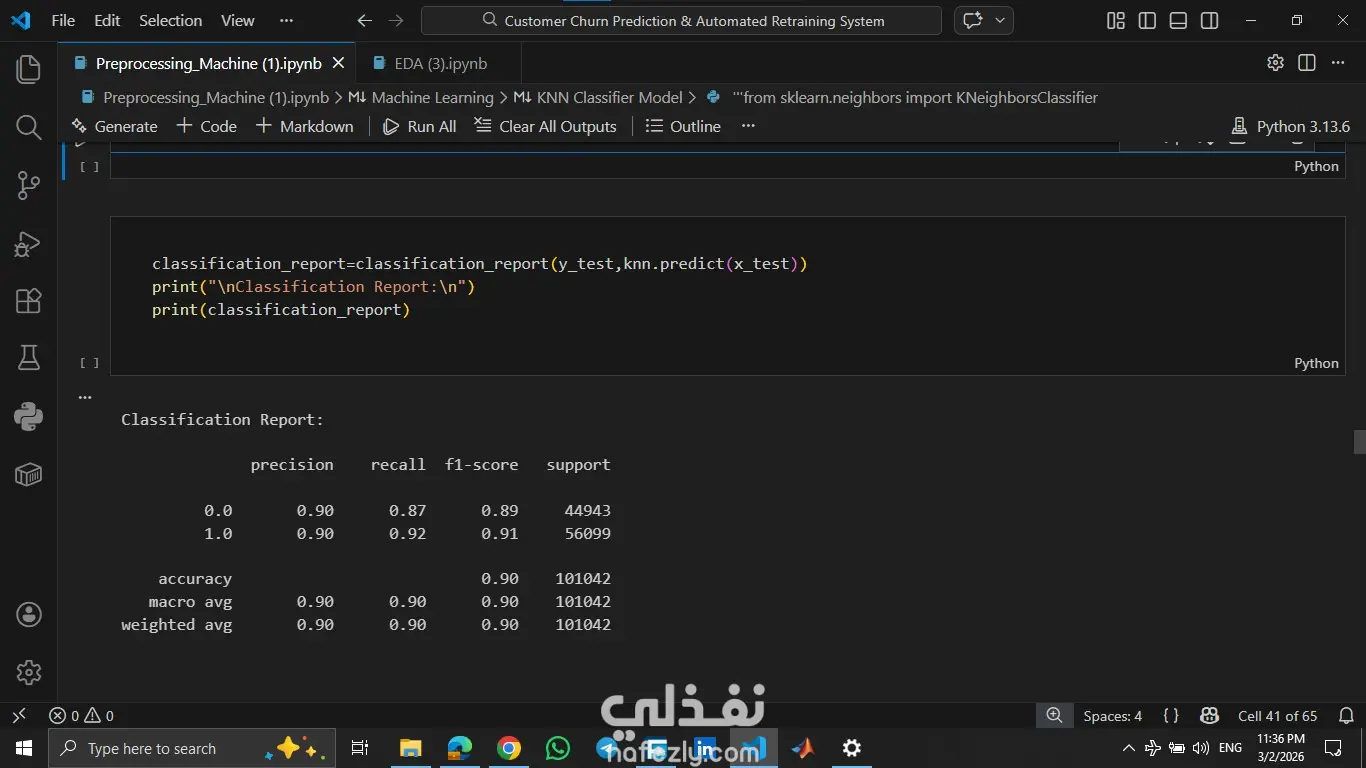
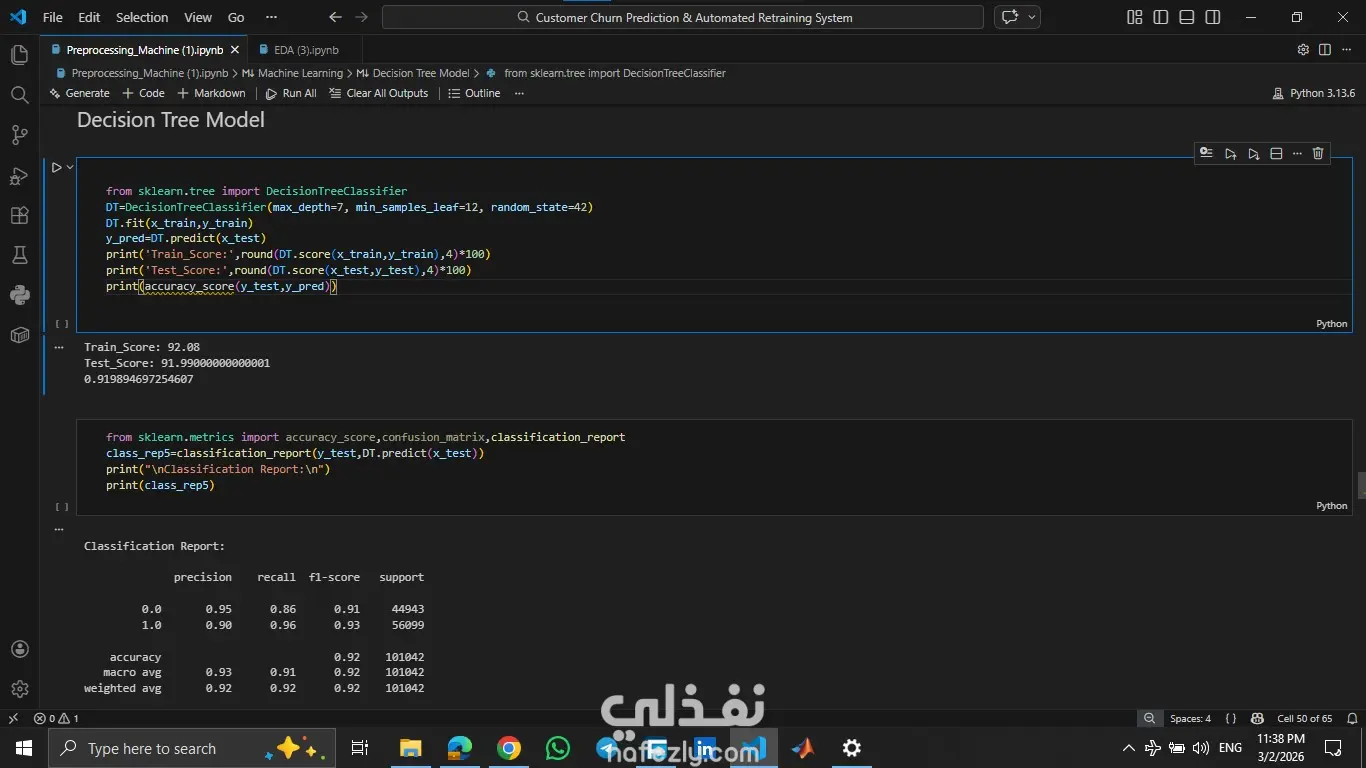
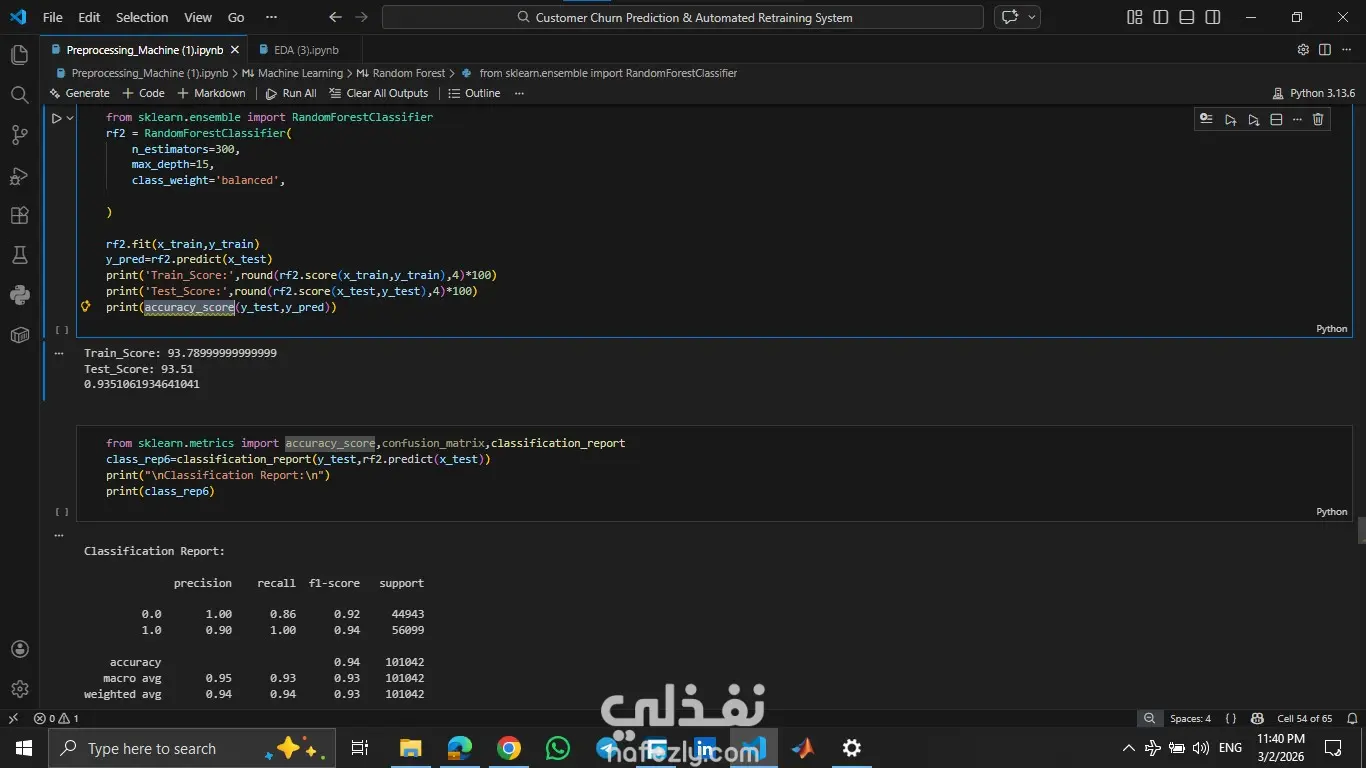
المشروع ده هدفه مساعدة الشركات إنها تزود نسبة الاحتفاظ بالعملاء (Customer Retention) عن طريق التنبؤ باحتمالية إن العميل يسيب الخدمة أو يلغي اشتراكه، بناءً على سلوكه وتفاعلاته السابقة. اشتغلت على تحليل داتا كبيرة جدًا فيها أكتر من نص مليون سجل باستخدام Python وPandas، علشان أستخرج insights مهمة تساعد في بناء نموذج تنبؤي قوي يدعم قرارات الشركة بشكل استباقي بدل ما تستنى العميل يمشي. المهام اللي اتنفذت: 1- تحليل البيانات (EDA): تحليل عوامل مهمة زي: العمر – مدة الاشتراك – تأخير الدفع – عدد مكالمات الدعم – إجمالي الإنفاق. استخدام الرسوم البيانية لفهم العلاقات بين المتغيرات. تحديد أكتر العوامل اللي بتأثر على قرار العميل إنه يكمل أو يسيب الخدمة. 2- تجهيز البيانات (Data Preprocessing): تقسيم البيانات لـ Training & Testing,تحويل البيانات النصية لأرقام باستخدام Label Encoder (زي الجنس، نوع الاشتراك، مدة العقد) وعمل Scaling للبيانات الرقمية باستخدام StandardScaler. وده ساعد في تحسين استقرار وسرعة تدريب الموديلات. 3- تطوير وتجربة النماذج (Model Development): بنيت وقارنت بين مجموعة كبيرة من خوارزميات تعلم الآلة لتصنيف العملاء، منهم:Logistic Regression, KNN, Decision Tree, Random Forest, SVM و Naive Bayes. وتم اختيار الأفضل بناءً على الدقة والأداء. النتائج والإنجازات: نموذج Random Forest حقق أفضل أداء بدقة وصلت لحوالي 94% نموذج Decision Tree وصل لدقة حوالي 92% نموذج KNN حقق حوالي 90% النظام ده بيوفر أساس قوي مبني على البيانات (Data-Driven) يساعد فرق التسويق في تحديد العملاء المعرضين للمغادرة بدري، وبالتالي يقدروا يقدموا لهم عروض مخصصة تحافظ عليهم وتقلل نسبة الخسارة.
مهارات العمل
بطاقة العمل

طلب عمل مماثل











