تنظيف ومعالجة البيانات (Missing values – Encoding – Scaling)
تحليل البيانات (EDA) مع رسومات توضيحية
تقليل الأبعاد باستخدام PCA
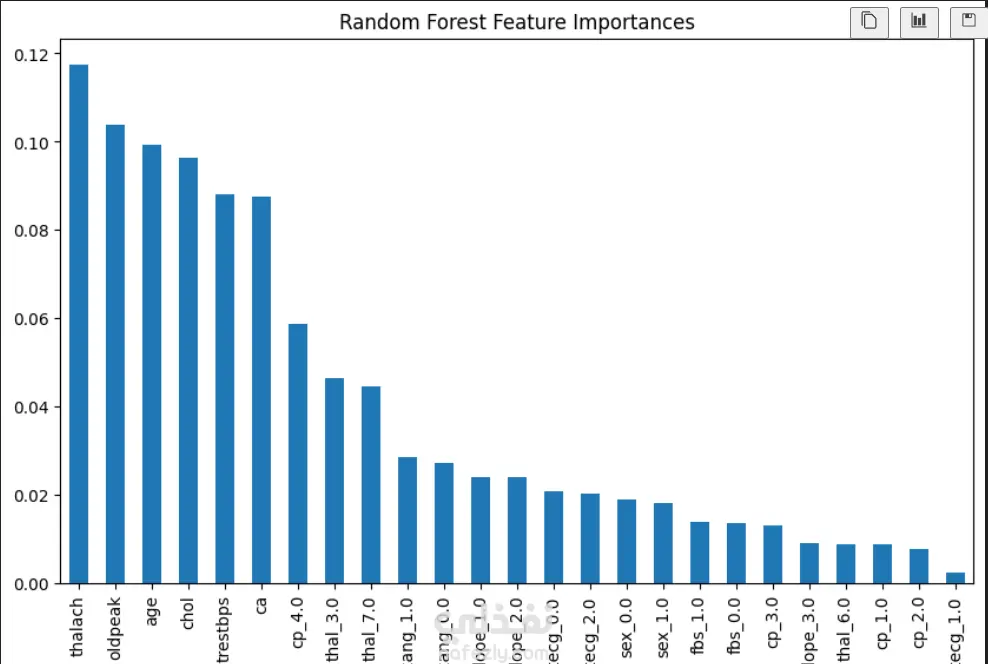
اختيار أهم الخصائص (Feature Selection)
تدريب نماذج تصنيف: Logistic Regression, Decision Tree, Random Forest, SVM
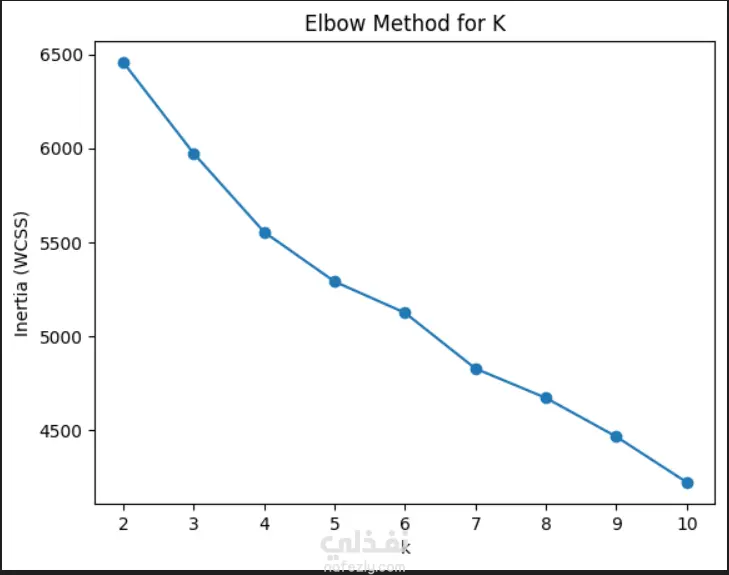
تطبيق Clustering (K-Means, Hierarchical)
تحسين الأداء باستخدام GridSearch و RandomizedSearch
تقييم النماذج (Accuracy, F1-score, ROC)
حفظ النموذج النهائي بصيغة .pkl