جمع البيانات (Data Collection)
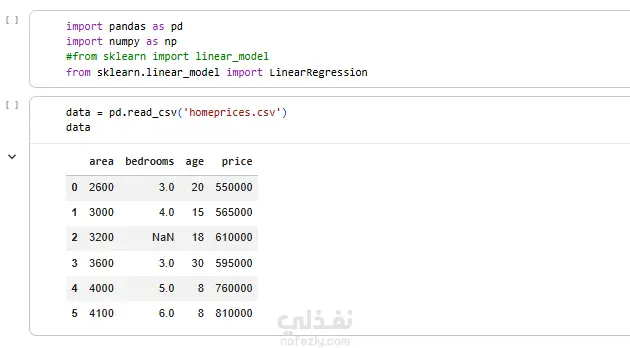
في البداية يتم الحصول على مجموعة بيانات تحتوي على معلومات عن المنازل وأسعارها.
غالبًا تتضمن البيانات الخصائص التالية:
• مساحة المنزل (Square Footage)
• عدد الغرف (Bedrooms)
• عدد الحمامات (Bathrooms)
• عمر المنزل (House Age)
• الموقع الجغرافي (Location)
• المسافة إلى الخدمات أو المدارس
• سعر المنزل (Price) ← وهو المتغير المستهدف
يمكن الحصول على البيانات من:
• مواقع العقارات
• قواعد بيانات عامة مثل Kaggle
• أو قواعد بيانات حكومية
تنظيف البيانات (Data Cleaning)
البيانات في الواقع غالبًا تحتوي على مشاكل مثل:
• قيم مفقودة
• قيم غير منطقية
• بيانات مكررة
يتم معالجة هذه المشاكل عن طريق:
• حذف القيم المفقودة
• تعويض القيم المفقودة بالمتوسط أو الوسيط
• إزالة القيم الشاذة (Outliers)
تجهيز البيانات (Data Preprocessing)
قبل إدخال البيانات إلى نموذج التعلم الآلي يجب تجهيزها.
تشمل هذه الخطوة:
تحويل البيانات النصية إلى أرقام
مثل تحويل الموقع الجغرافي باستخدام:
• One Hot Encoding
تطبيع البيانات (Normalization / Scaling)
بعض الخوارزميات تحتاج أن تكون البيانات في نفس النطاق مثل:
• MinMaxScaler
• StandardScaler
تقسيم البيانات (Data Splitting)
يتم تقسيم البيانات إلى ثلاث مجموعات رئيسية:
Training Set
70% من البيانات
Validation Set
15% من البيانات
Test Set
15% من البيانات
بناء نماذج التعلم الآلي (Machine Learning Models)
يتم تدريب عدة نماذج مختلفة ومقارنة أدائها لاختيار الأفضل.
من النماذج المستخدمة:
Linear Regression
أبسط نموذج للتنبؤ بالقيم المستمرة.
يعتمد على العلاقة الخطية بين المتغيرات.
Decision Tree Regression
يبني شجرة قرارات تعتمد على تقسيم البيانات.
مميزاته:
• سهل الفهم
• يتعامل مع العلاقات غير الخطية
Random Forest Regression
عبارة عن مجموعة من أشجار القرار.
مميزاته:
• دقة أعلى
• تقليل مشكلة overfitting
Gradient Boosting / XGBoost
من أقوى النماذج المستخدمة في التنبؤ.
يعتمد على تحسين النموذج تدريجيًا عن طريق تصحيح الأخطاء السابقة.
تدريب النماذج (Model Training)
يتم تدريب كل نموذج باستخدام بيانات التدريب.
مثال:
model.fit(X_train, y_train)
تقييم النماذج (Model Evaluation)
بعد التدريب يتم تقييم النماذج باستخدام بيانات الاختبار.
يتم استخدام عدة مقاييس مثل:
MAE
متوسط الخطأ المطلق.
MSE
متوسط مربع الخطأ.
RMSE
الجذر التربيعي لمتوسط مربع الخطأ.
R² Score
يقيس مدى قدرة النموذج على تفسير التباين في البيانات.
اختيار أفضل نموذج (Model Selection)
بعد مقارنة النتائج يتم اختيار النموذج الذي يحقق:
• أقل خطأ
• أعلى R²
ويتم اعتماده كنموذج نهائي للتنبؤ بأسعار المنازل.
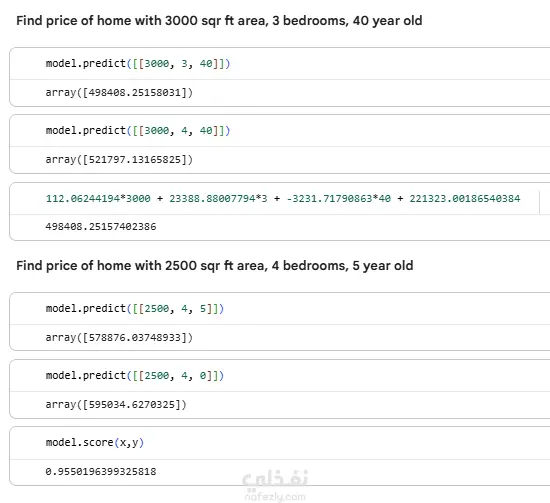
استخدام النموذج للتنبؤ (Prediction)
بعد اختيار النموذج يمكن استخدامه للتنبؤ بأسعار منازل جديدة.
مثال:
predicted_price = model.predict(new_house_data)
نشر النموذج (Deployment) – اختياري
يمكن تحويل النموذج إلى تطبيق عملي مثل:
• Web Application باستخدام Flask
• API للتنبؤ بالأسعار
• لوحة تحكم Dashboard
النتيجة النهائية:
يتم بناء نظام قادر على تقدير سعر المنزل اعتمادًا على مجموعة من الخصائص باستخدام خوارزميات تعلم الآلة المختلفة واختيار النموذج الأكثر دقة.