كشف الرسائل النصية غير المرغوب فيها باستخدام تعلم الآلة
تفاصيل العمل
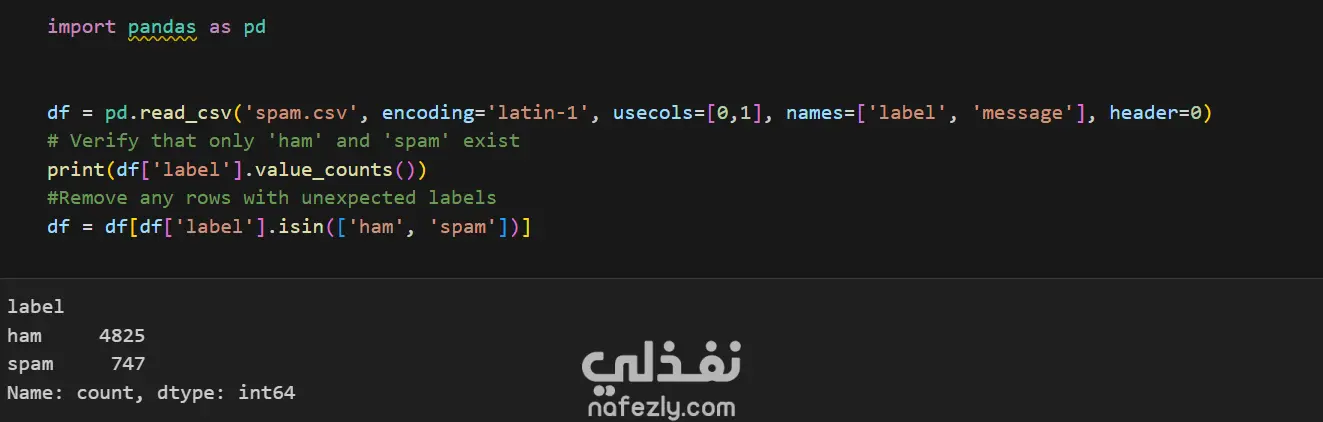
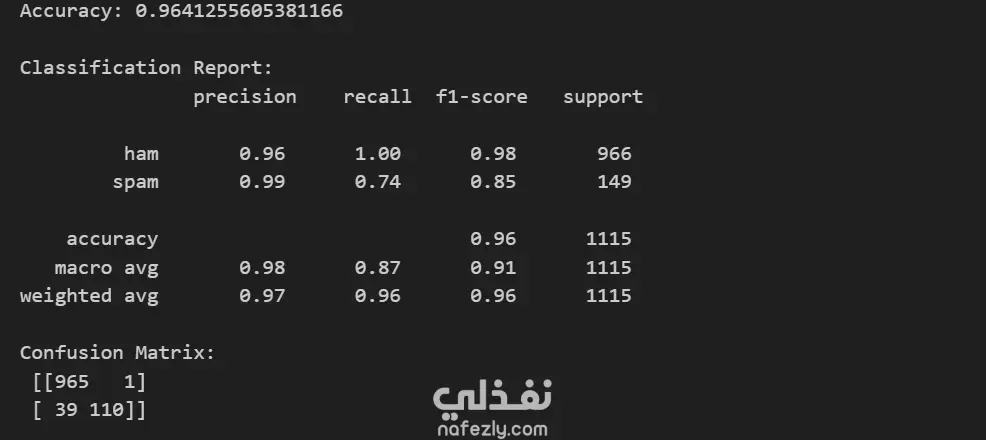
بناء نظام آلي لتصنيف الرسائل النصية القصيرة (SMS) إلى رسائل عادية (ham) أو رسائل مزعجة (spam) باستخدام تقنيات معالجة اللغة الطبيعية وخوارزميات التعلم الآلي. مجموعة البيانات: تم استخدام مجموعة البيانات الشهيرة SMS Spam Collection (spam.csv)، والتي تحتوي على 5,572 رسالة نصية مصنفة يدويًا. تعكس البيانات الواقع العملي حيث أن حوالي 87% من الرسائل عادية و13% فقط غير مرغوب فيها. المنهجية: تحميل البيانات وتنظيفها: تم تحميل البيانات باستخدام مكتبة pandas والاحتفاظ بالعمودين الأساسيين (التصنيف والنص). تمت إزالة أي صفوف تحتوي على تصنيفات غير متوقعة. المعالجة المسبقة للنصوص: تم تطبيق دالة معالجة مخصصة على كل رسالة: تحويل النص إلى أحرف صغيرة. إزالة جميع الأحرف غير الأبجدية (الأرقام، علامات الترقيم، الرموز الخاصة). تقسيم النص إلى كلمات منفردة (tokenization). إزالة كلمات التوقف الشائعة في اللغة الإنجليزية بالاعتماد على قائمة NLTK. تطبيق الـ stemming (اختزال الكلمات إلى جذورها) باستخدام PorterStemmer والـ lemmatization باستخدام WordNetLemmatizer. ترميز التصنيفات: تم تحويل التصنيفات النصية إلى قيم رقمية ثنائية: ham ← 0، spam ← 1. تقسيم البيانات: تم تقسيم البيانات إلى مجموعة تدريب (80%) ومجموعة اختبار (20%) مع الحفاظ على توزيع الفئات الأصلي باستخدام stratified sampling. استخراج الميزات – TF-IDF: تم تحويل النصوص إلى متجهات رقمية باستخدام تقنية TF-IDF (تردد المصطلح – معكوس تردد المستند). تم تحديد عدد الميزات بـ 5000 كلمة الأكثر شيوعًا لتقليل الأبعاد. تدريب النموذج: تم تدريب مصنف Multinomial Naive Bayes على بيانات التدريب المحولة. تُعد هذه الخوارزمية فعالة بشكل خاص في مهام تصنيف النصوص. التقييم: تم تقييم أداء النموذج على بيانات الاختبار باستخدام: الدقة (Accuracy) – النسبة المئوية للتنبؤات الصحيحة. الدقة (Precision)، الاستدعاء (Recall)، مقياس F1 – لكل فئة لتقييم الأداء مع البيانات غير المتوازنة. مصفوفة الارتباك (Confusion Matrix) – لتوضيح عدد التنبؤات الصحيحة والخاطئة. النتائج: حقّق النموذج دقة إجمالية بلغت 96.4% تقريبًا. يُظهر تقرير التصنيف دقة عالية جدًا للفئة العادية، بينما تتميز الفئة غير المرغوب فيها بدقة ممتازة (99%) ولكن استدعاء أقل قليلاً (74%)، مما يعني أن بعض الرسائل المزعجة لم يتم اكتشافها. توضح مصفوفة الارتباك أن رسالة عادية واحدة فقط تم تصنيفها خطأ على أنها مزعجة، بينما تم تصنيف 39 رسالة مزعجة خطأ على أنها عادية. التقنيات المستخدمة: Python (مكتبات pandas, numpy) NLTK (معالجة النصوص) Scikit-learn (استخراج الميزات، التدريب، التقييم) Jupyter Notebook (بيئة التطوير) أثر المشروع: يُظهر هذا المشروع خط أنابيب متكامل لمعالجة النصوص وتصنيفها في سياق واقعي، بدءًا من البيانات الخام وصولاً إلى نموذج قابل للنشر. يمكن أن يكون أساسًا لأنظمة أكثر تقدمًا مثل تصفيف البريد الإلكتروني أو مراقبة محتوى الدردشات أو تحليل ملاحظات العملاء.
مهارات العمل
بطاقة العمل

طلب عمل مماثل











