Real-Time Hospital Operations & Analytics Pipeline (End-to-End)
تفاصيل العمل
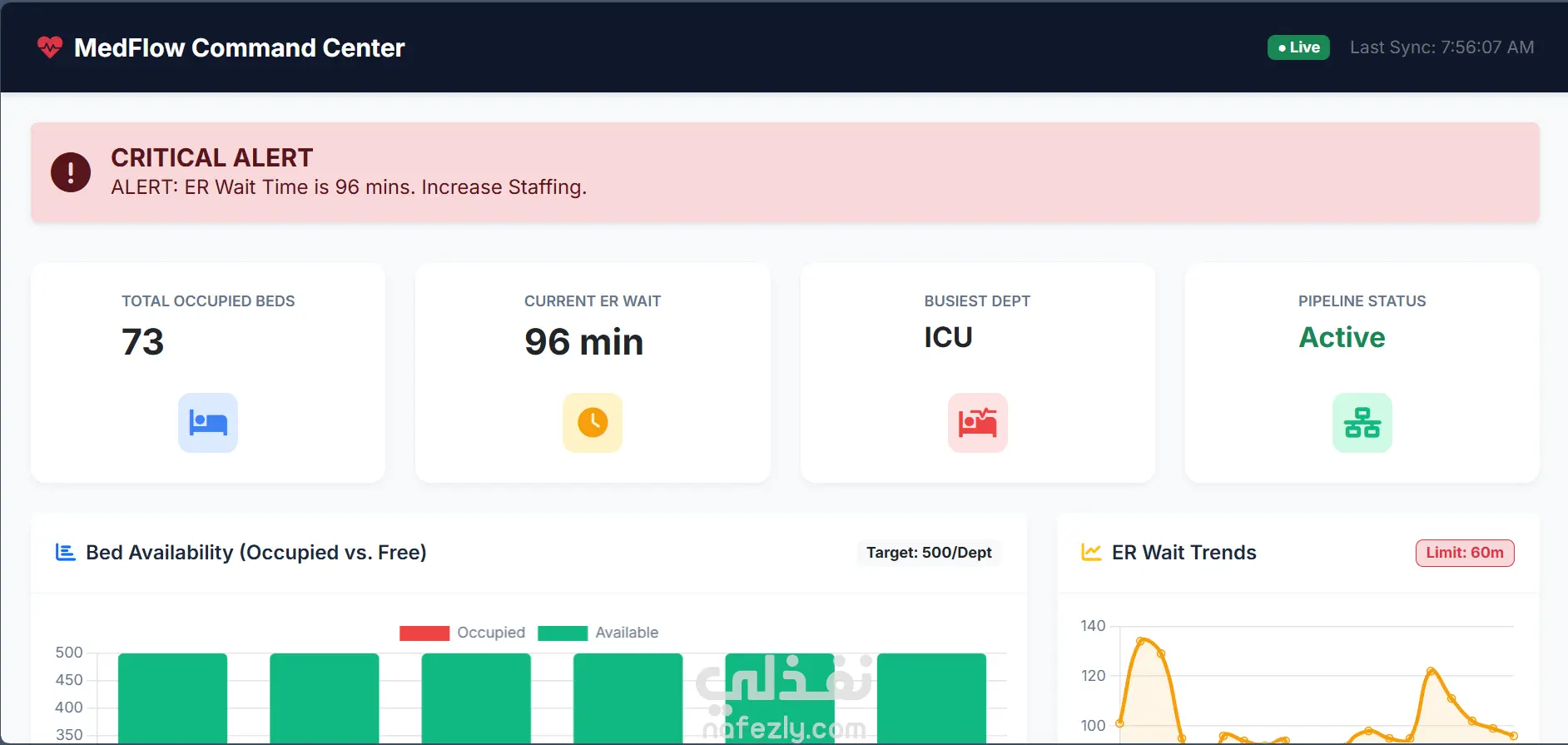
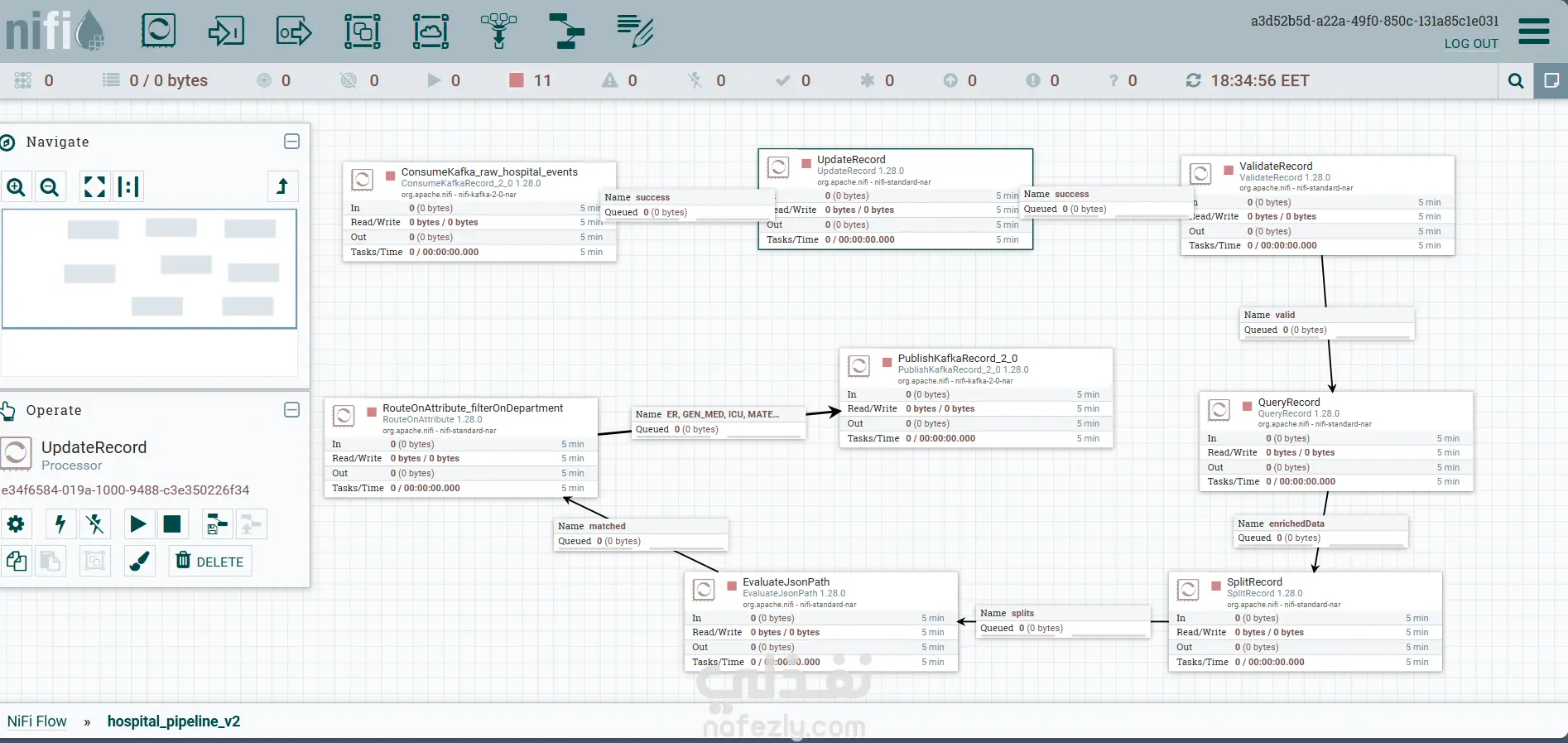
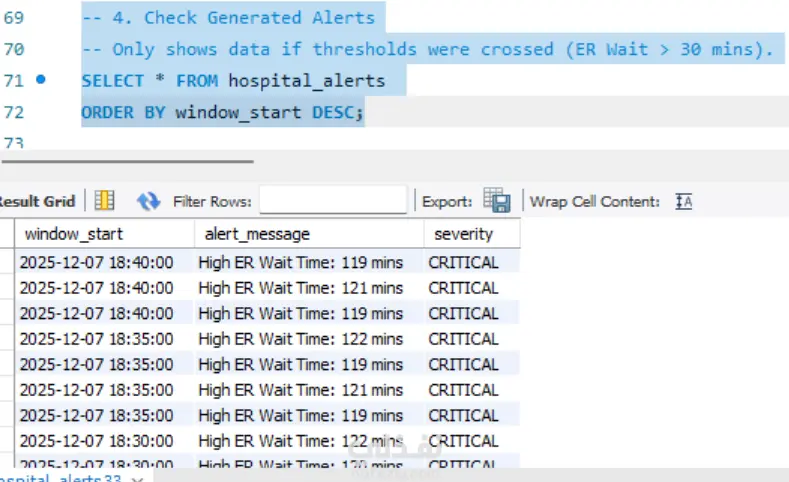
نظرة عامة على المشروع: قمت ببناء نظام متكامل (Data Pipeline) لمعالجة وتحليل بيانات المستشفيات في الوقت الفعلي. الهدف من المشروع هو تحويل تدفقات البيانات الضخمة والمعقدة إلى تقارير لحظية تساعد إدارة المستشفيات في اتخاذ قرارات سريعة بشأن إشغال الأسرة، وأوقات الانتظار في الطوارئ، وتوزيع الموظفين. أبرز المميزات التقنية: توليد البيانات (Python): تطوير محاكٍ لبيانات المستشفيات (Admission/Discharge) باستخدام Python. نقل البيانات (Kafka): استخدام Apache Kafka كمنصة لتبادل الرسائل لضمان سرعة نقل البيانات وعدم فقدانها. تنقية البيانات (Apache NiFi): تصميم تدفق عمل (Flow) لتنقية البيانات "المتسخة" والتعامل مع القيم المفقودة (Null Handling) لضمان دقة التقارير. التحليل اللحظي (PySpark): استخدام Apache Spark (Structured Streaming) لإجراء عمليات حسابية معقدة في الوقت الفعلي، مثل: حساب عدد الأسرة المشغولة لحظياً لكل قسم (Stateful Processing). حساب متوسط وقت الانتظار في الطوارئ خلال نوافذ زمنية (30-min Sliding Windows). تخزين البيانات (MySQL): ربط مخرجات التحليل بقاعدة بيانات MySQL لتوفير لوحة بيانات (Dashboard) للمستخدم النهائي. الأدوات المستخدمة: Apache Spark 4.0.1 (PySpark) Apache Kafka & Zookeeper Apache NiFi 1.28 Python MySQL 8.0
مهارات العمل
بطاقة العمل

طلب عمل مماثل













