جمع البيانات (Data Acquisition): يقوم الكود بسحب بيانات حية من بوابة البيانات المفتوحة لمدينة نيويورك باستخدام "API"، ويركز على مؤشرات مثل الجسيمات الدقيقة (PM 2.5) وثاني أكسيد النيتروجين (NO2).
معالجة وتنظيف البيانات (Data Preprocessing & Cleaning):
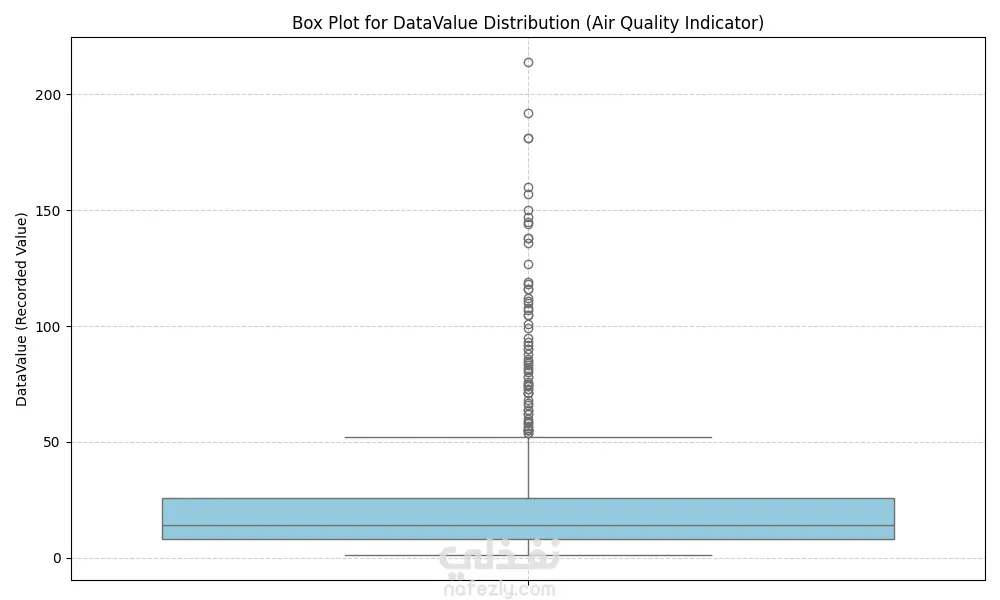
يحدد المشروع القيم المفقودة والمتطرفة (Outliers) ويتعامل معها لضمان دقة التحليل.
يوحد وحدات القياس (مثل تحويل "ppb" إلى قيم مكافئة) ويزيل الصفوف المكررة.
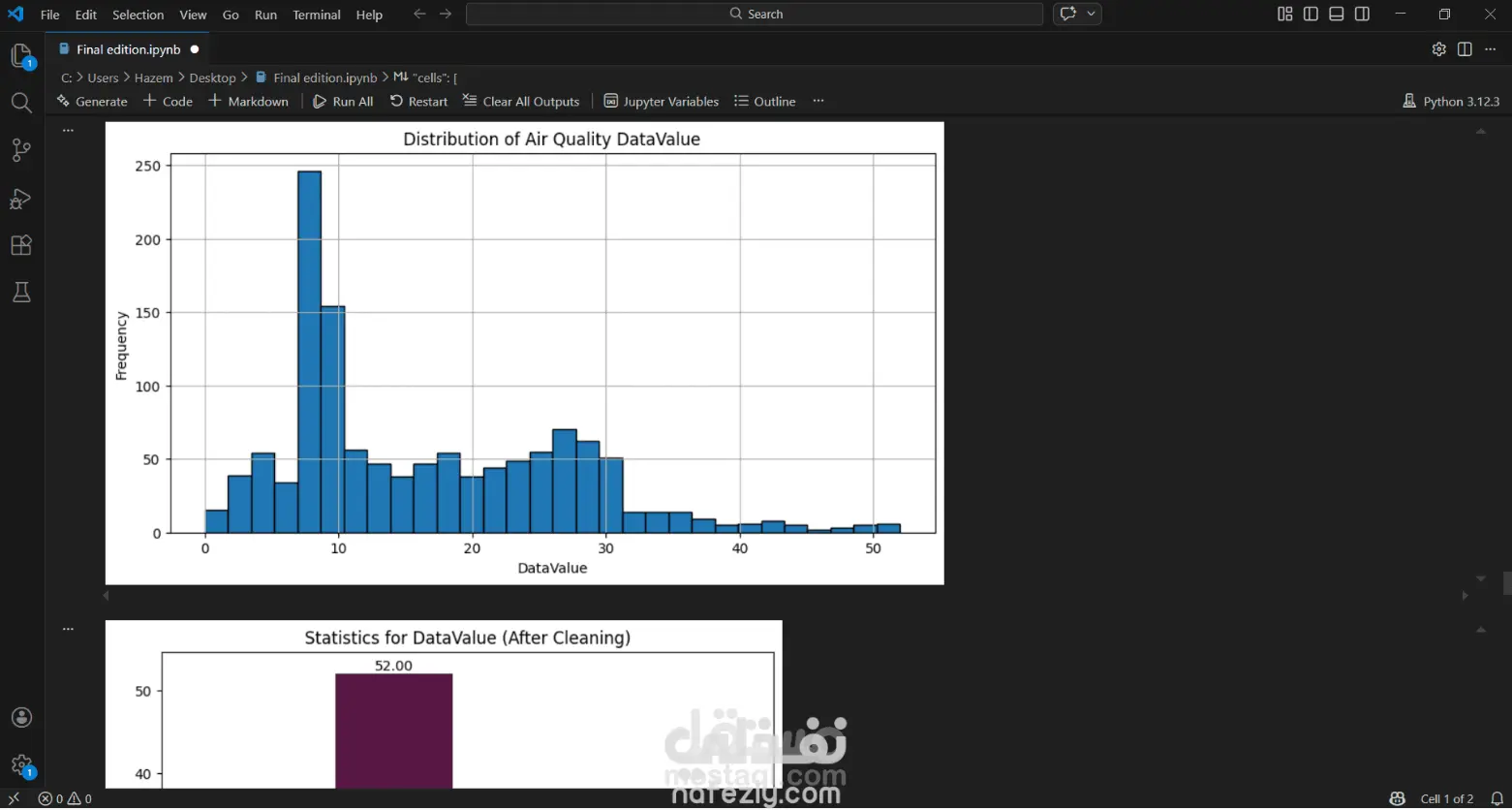
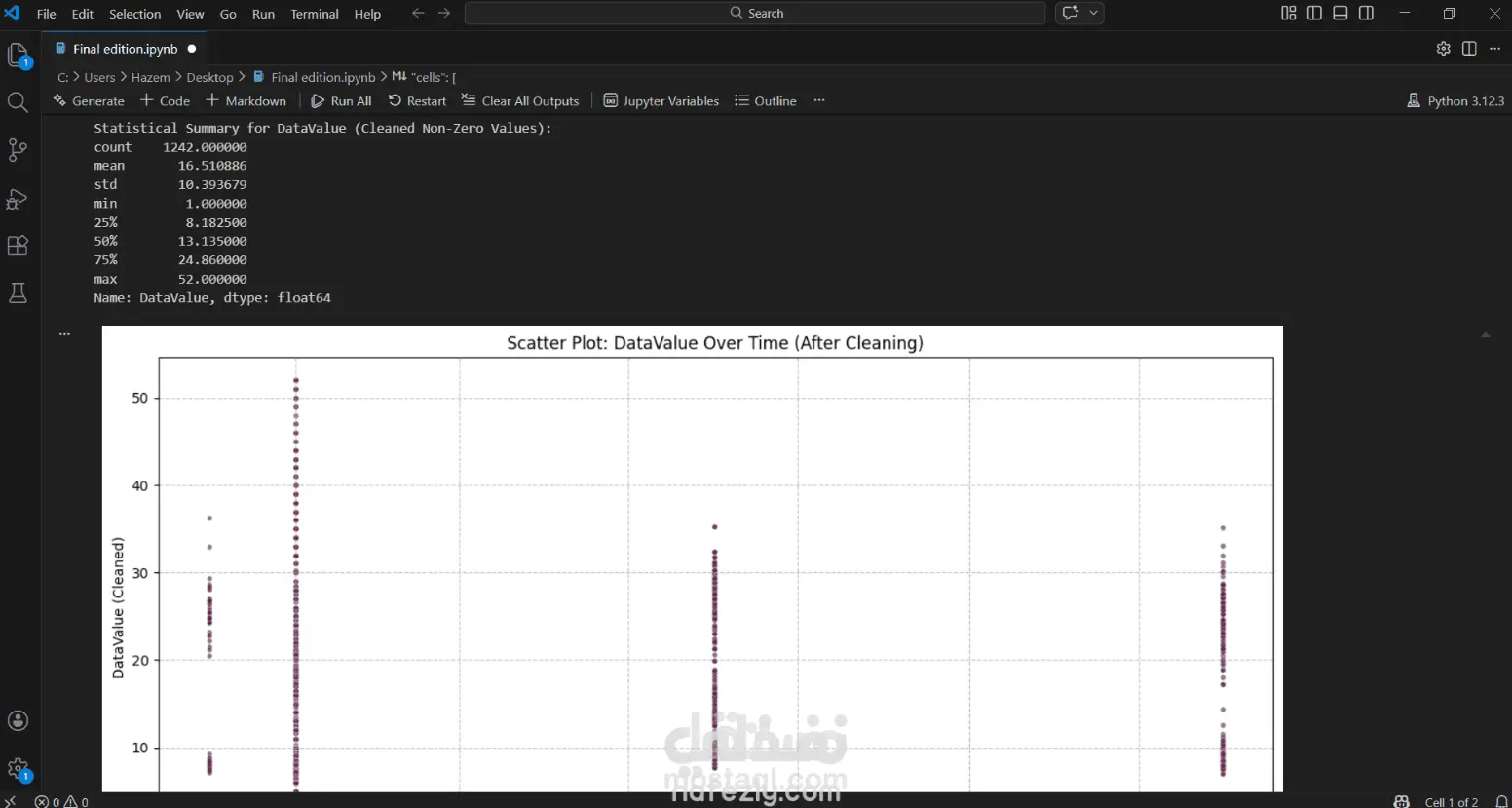
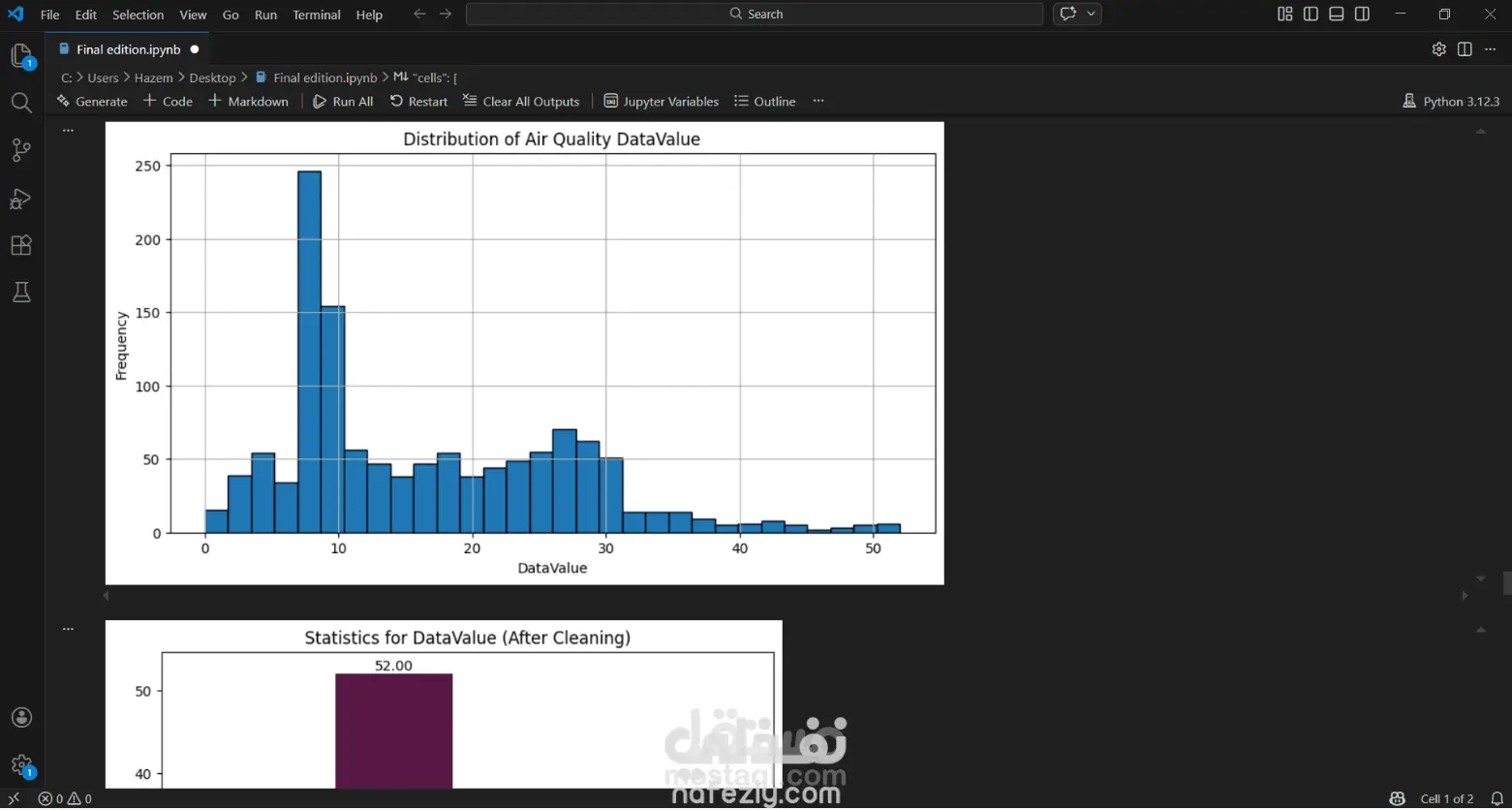
التحليل الإحصائي: يقدم ملخصات إحصائية للبيانات مثل المتوسط (Mean)، والوسيط (Median)، والقيم العظمى والصغرى لمستويات التلوث المسجلة.
التصور البياني (Visualization): يستخدم المكتبات البرمجية (مثل Matplotlib و Seaborn) لإنشاء رسوم بيانية توضح:
توزيع ملوثات الهواء ومقارنتها عبر الزمن.
المناطق الـ 10 الأكثر تلوثاً في المدينة.
خريطة حرارية (Heatmap) توضح العلاقة بين المناطق المختلفة وأنواع الملوثات