A supervised machine learning project focused on early detection of diabetes using real-world clinical data.
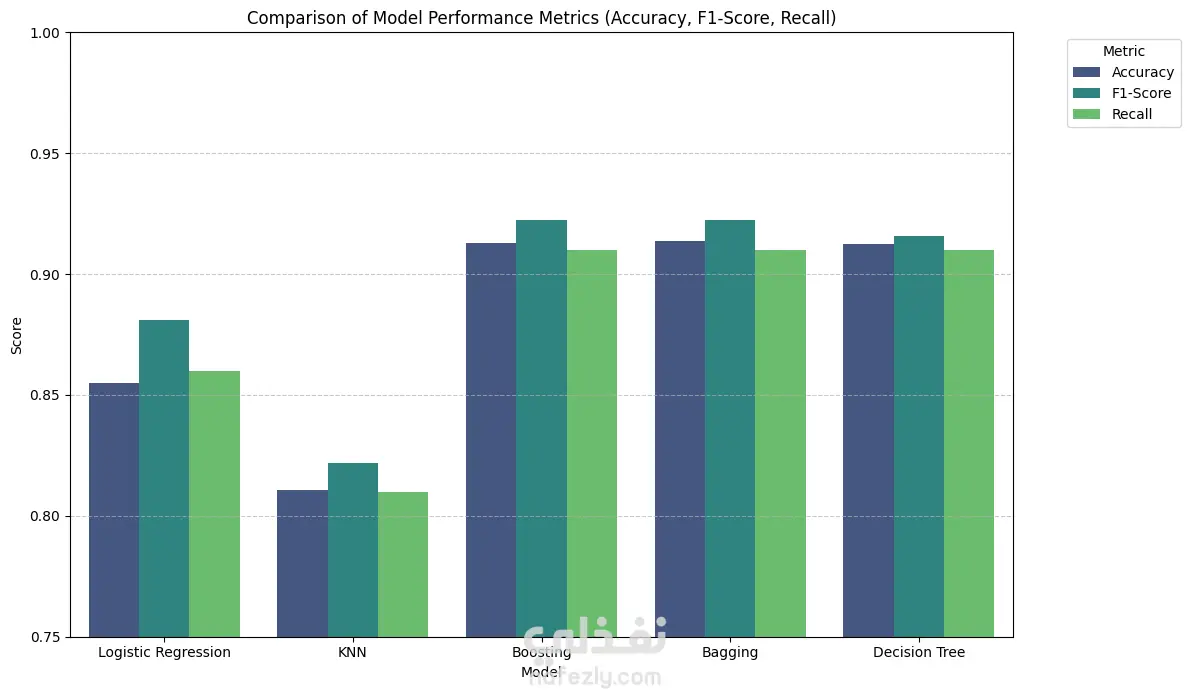
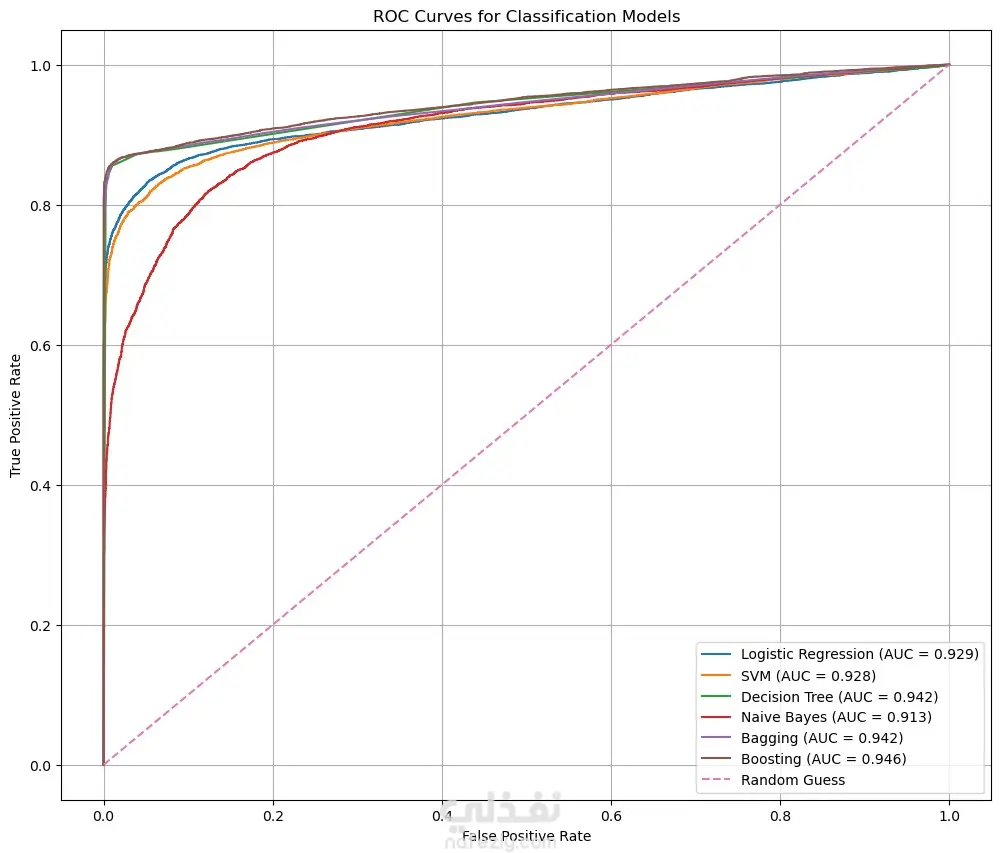
This project compares 5 classification models to identify the most accurate and reliable approach for medical diagnosis.
:Preprocessing
Removed duplicate records
Dropped irrelevant & leakage-prone features
Handled missing values
Numerical → Median Imputation
Categorical → Most Frequent (Mode)
Cleaned categorical text
One-Hot Encoding for categorical variables
Standard Scaling for numerical features
Converted boolean features to integers
:Machine Learning models used
Logistic Regression
K-Nearest Neighbors (KNN)
Decision Tree
Random Forest (Bagging)
Gradient Boosting