كشف الأخبار الزائفة باستخدام خوارزميات التعلم الآلي التقليدية
تفاصيل العمل
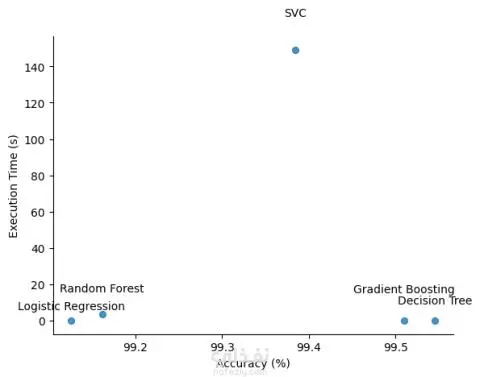
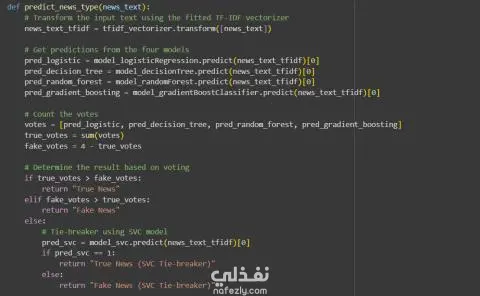
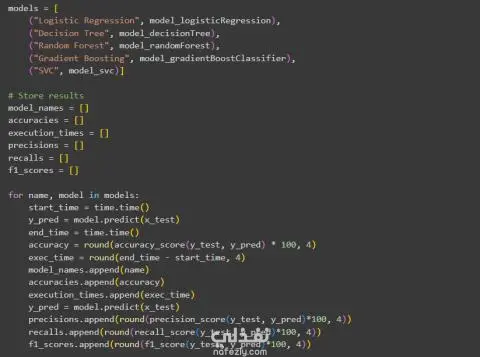
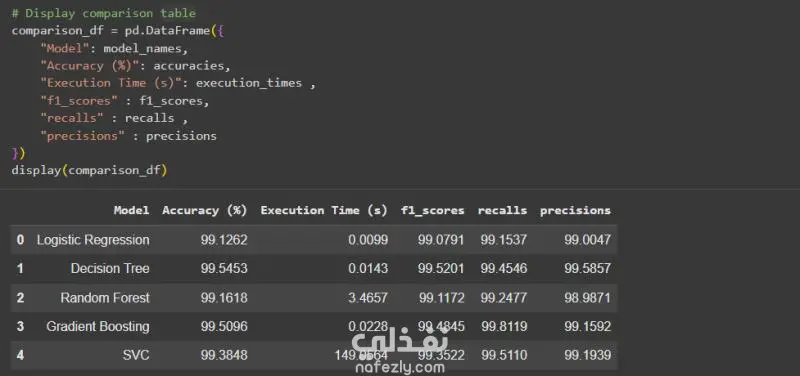
🔹 في هذا المشروع قمت باستخدام مجموعة بيانات قوية تضم حوالي 44,000 مقال إخباري مصنّف إلى أخبار صحيحة وأخبار زائفة، بهدف تدريب واختبار عدة نماذج من خوارزميات التعلم الآلي. 🔹 بدأت بمرحلة معالجة البيانات النصية (Text Preprocessing) ثم تحويل النصوص إلى تمثيل رقمي باستخدام تقنية TF-IDF (Term Frequency–Inverse Document Frequency) لتحويل النص الخام إلى خصائص رقمية يمكن لنماذج التعلم الآلي التعامل معها. 🔹 تم تقييم خمسة نماذج تصنيف على بيانات الاختبار وكانت النتائج كالتالي: Logistic Regression: دقة 99.28% Decision Tree Classifier: دقة 99.54% Random Forest Classifier: دقة 99.16% Gradient Boosting Classifier: دقة 99.51% Support Vector Classifier (SVC): دقة 99.38% 🔹 قمت بمقارنة النماذج من حيث: الدقة (Accuracy)، زمن التنفيذ (Execution Time)، F1-Score، Recall، و Precision. 🔹 الاستنتاجات: نموذج Decision Tree يُعد الخيار الأكثر عملية بفضل دقته العالية وسرعة تنفيذه. نموذج Gradient Boosting يتفوق عندما تكون قيمة الـ Recall (القدرة على اكتشاف جميع الحالات الصحيحة) ذات أولوية. نموذج Logistic Regression يتميز بالبساطة والسرعة والاعتمادية في التطبيقات السريعة. نموذج Random Forest يحقق دقة جيدة لكنه أبطأ نسبيًا، لذلك يُفضّل استخدامه في المعالجة غير الفورية (Batch Processing). نموذج SVC يحقق دقة جيدة لكنه يتطلب تكلفة حسابية مرتفعة، مما يجعله أقل ملاءمة للتطبيقات واسعة النطاق أو الزمن الحقيقي. 🎯 في المرحلة النهائية قمت بتطبيق نموذج تجميعي (Ensemble) باستخدام طريقة Hard Voting اعتمادًا على أربعة من أسرع النماذج وهي: (Logistic Regression، Decision Tree، Random Forest، Gradient Boosting). وفي حالة تعادل الأصوات يتم استخدام نموذج SVC كعامل حسم (Tie-Breaker) نظرًا لدقته، مع استخدامه بشكل محدود بسبب زمن التنبؤ الأطول. يسلط هذا المشروع الضوء على قدرة طرق التجميع (Ensemble Methods) على رفع مستوى الدقة وتحقيق توازن بين الأداء والكفاءة الحسابية.
مهارات العمل
بطاقة العمل

طلب عمل مماثل











