وصف المشروع :
قمت بتطوير نظام متكامل للتنبؤ باحتمالية الإصابة بأمراض القلب بناءً على البيانات الطبية التاريخية (UCI Dataset). المشروع ليس مجرد نموذج ذكاء اصطناعي، بل هو خط إنتاج بيانات (Pipeline) كامل يبدأ من معالجة البيانات الخام وينتهي بواجهة مستخدم تفاعلية قادرة على تقديم تنبؤات فورية.
هذا المشروع كان جزءاً من متطلبات تخرجي من شهادة Sprints Machine Learning المعتمدة، وحقق نتائج دقيقة في تصنيف الحالات الطبية.
التفاصيل التقنية:
في هذا العمل، قمت بتنفيذ الخطوات التالية لضمان أعلى دقة:
معالجة البيانات (Data Preprocessing): التعامل مع البيانات المفقودة، وتنسيق البيانات لضمان جاهزيتها للنماذج.
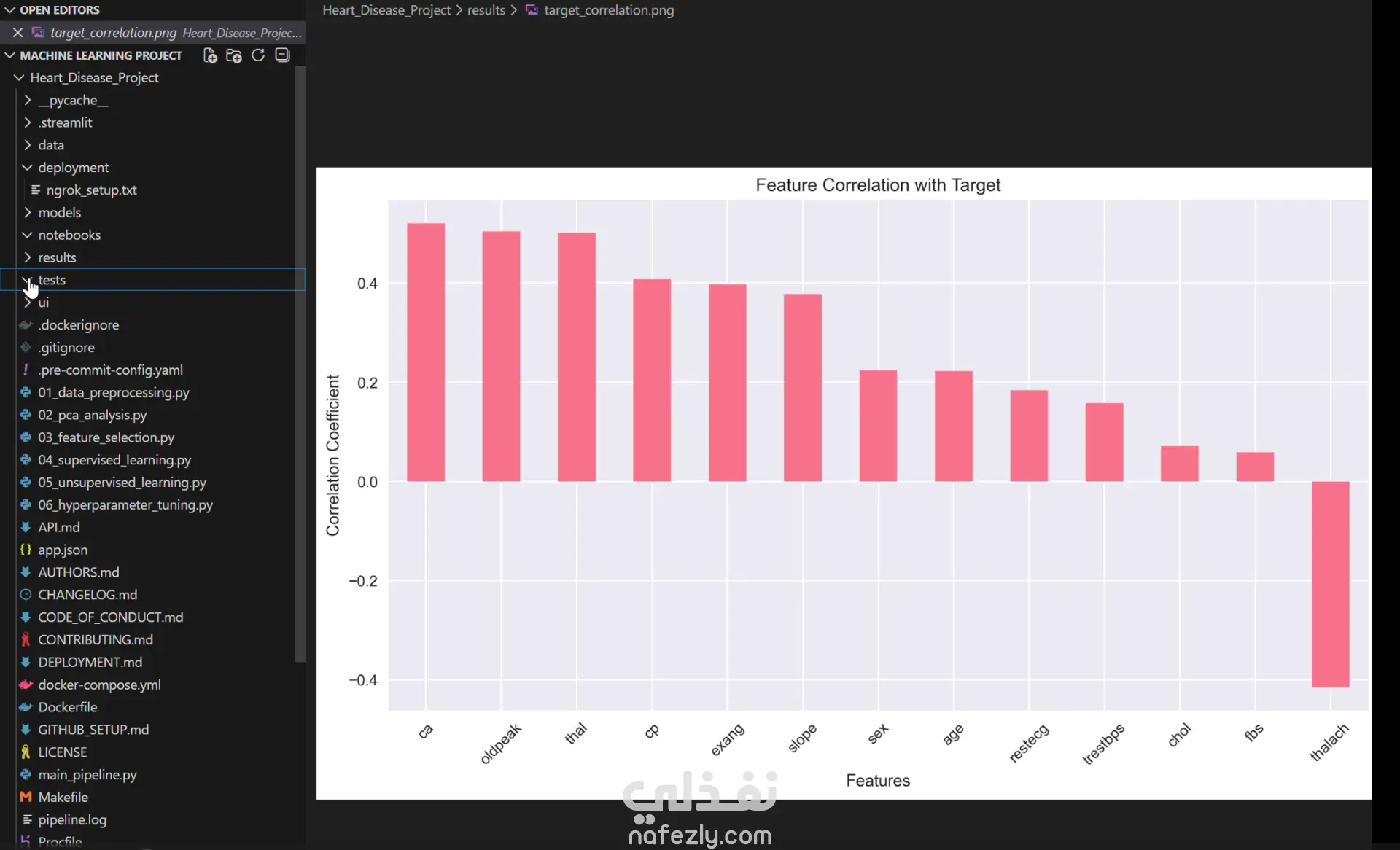
هندسة الميزات (Feature Engineering & PCA): استخدام تقنية التحليل المكون الأساسي (PCA) لتقليل الأبعاد واختيار أهم العوامل المؤثرة في الإصابة، مما ساعد في تسريع النموذج وتقليل الـ Overfitting.
تطوير النماذج (Model Development): قارنت بين عدة نماذج لضمان أفضل نتيجة:
Supervised Learning: (Logistic Regression, Random Forest, SVM).
Unsupervised Learning: لتحليل تجمعات البيانات واكتشاف الأنماط الخفية.
تحسين الأداء (Optimization): استخدام الـ Hyperparameter Tuning للوصول لأفضل دقة ممكنة لكل نموذج.
واجهة المستخدم (Web UI): تطوير واجهة تفاعلية باستخدام Streamlit تسمح للأطباء أو المستخدمين بإدخال البيانات والحصول على النتيجة وتحليل بصري للبيانات فوراً.
الأدوات والتقنيات المستخدمة :
اللغة: Python.
المكتبات: Pandas, NumPy, Scikit-learn.
النماذج: Random Forest, SVM, Logistic Regression.
تقليل الأبعاد: PCA.
الواجهة: Streamlit.
النتائج المحققة (Impact):
توفير أداة قادرة على مساعدة الكادر الطبي في التنبؤ المبكر.
عرض مرئي (Visualization) يوضح توزيع البيانات وعوامل الخطورة.
نظام مرن يمكن تحديثه ببيانات جديدة بسهولة.