مشروع متكامل (End-to-End) يحاكي الأنظمة التي تستخدمها البنوك لتقييم الحالة المالية للعملاء. يقوم النظام بتحليل السلوك المالي والبيانات الديموغرافية لتصنيف العملاء إلى ثلاث فئات: (ضعيف، متوسط، جيد)، مما يساعد المؤسسات المالية على اتخاذ قرارات مدروسة بشأن القروض والخدمات الائتمانية.
المميزات التقنية والقيمة المضافة:
هندسة البيانات المالية: معالجة بيانات ضخمة (100 ألف سجل) وتصفية أكثر من 28 متغير مالي وسلوكي لاختيار الأكثر تأثيراً على درجة الائتمان.
بناء خط إنتاج البيانات (Data Pipeline):
تحويل البيانات النصية المالية المعقدة إلى قيم رقمية.
استخدام StandardScaler لتوحيد مقاييس البيانات المالية (مثل الدخل والديون).
تطبيق الترميز (One-Hot Encoding) للمتغيرات الفئوية مثل "المهنة" و"نوع القرض".
النماذج الذكية وتطويرها:
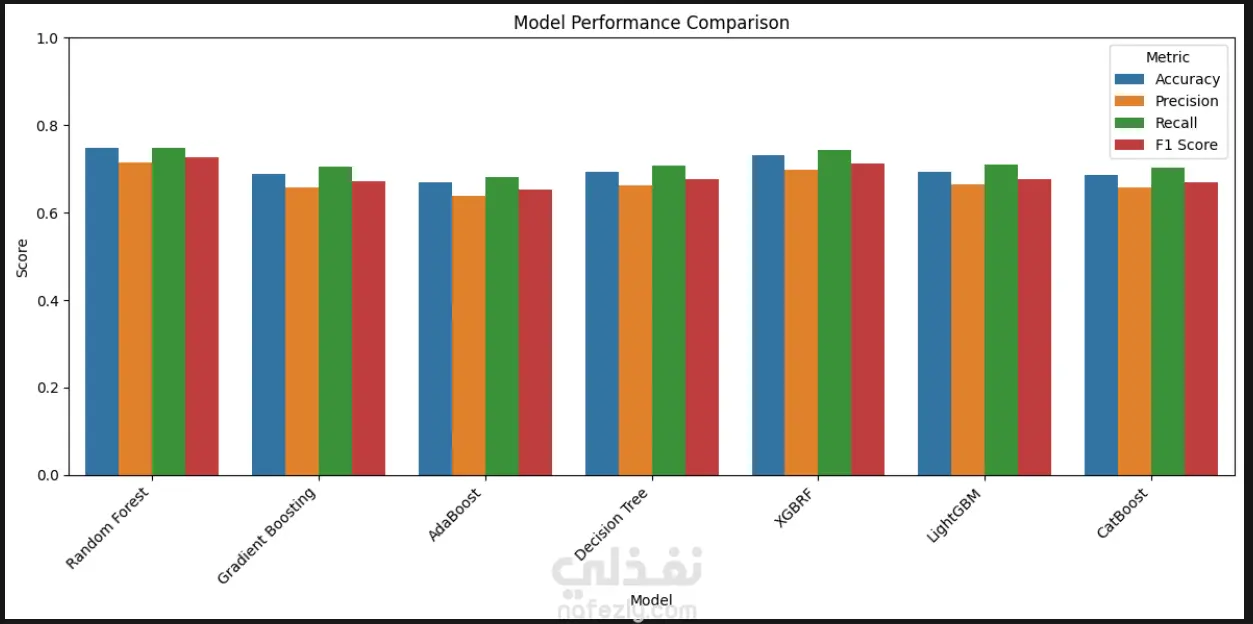
تجربة أقوى مصنفات تعلم الآلة: Random Forest, XGBoost, CatBoost, LightGBM.
استخدام GridSearchCV مع 3-fold Cross-Validation لضمان استقرار النموذج وتجنب الـ Overfitting.
اختيار نموذج Random Forest كأفضل نموذج بعد تحقيق أعلى معدل F1-Score.
تحليل الميزات (Feature Importance): دراسة العوامل الأكثر تأثيراً في تحديد درجة الائتمان، مما يوفر شفافية في فهم قرارات الموديل (Interpretability).
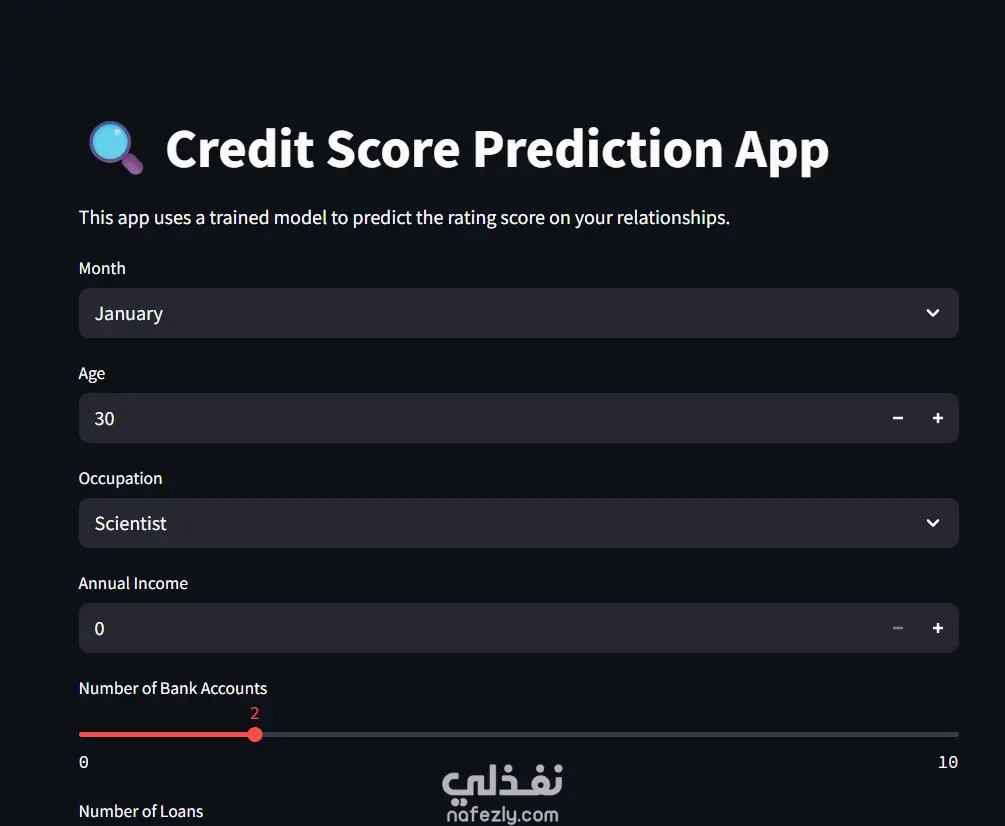
التطبيق التفاعلي (Live Demo):
لم يقتصر المشروع على الجانب البرمجي فقط، بل تم بناء واجهة مستخدم تفاعلية باستخدام Streamlit تتيح للمستخدمين:
إدخال البيانات المالية (الدخل، عدد القروض، الديون القائمة).
الحصول على توقع فوري لدرجة الائتمان بضغطة زر.
واجهة سهلة الاستخدام تعتمد على الـ Sliders والـ Dropdown menus.
الأدوات المستخدمة:
لغة البرمجة: Python.
المكتبات: Pandas, NumPy, Scikit-learn, XGBoost.
الواجهة البرمجية: Streamlit.
إدارة النماذج: Pickle لدمج الموديل مع الـ Scalers في ملفات جاهزة للتشغيل.



![تصميم موقع [front end]](https://nafezly-production.fra1.cdn.digitaloceanspaces.com/uploads/services/small/6475_60a41cb8bf119-1621367992.jpg)









