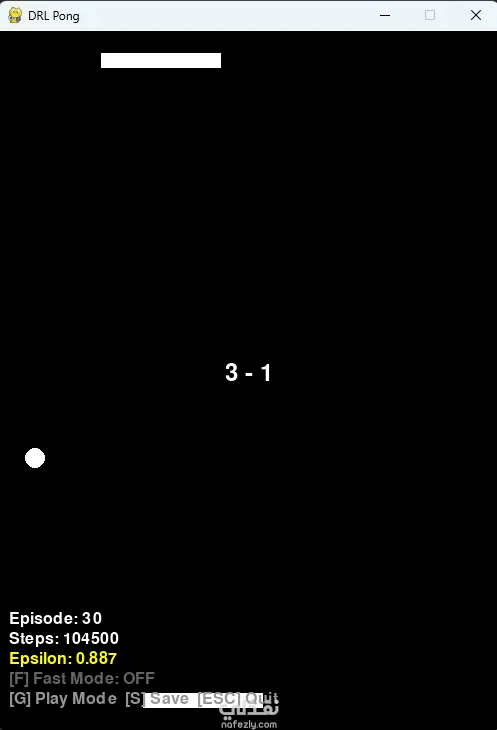
يهدف هذا المشروع إلى بناء بيئة تفاعلية مخصصة للعبة Pong الكلاسيكية من الصفر، وتدريب وكلاء أذكياء (AI Agents) للعب وتطوير استراتيجياتهم بشكل مستقل باستخدام خوارزميات التعلم المعزز العميق (مثل Deep Q-Networks). تم تصميم النظام ليدعم تدريب النماذج وتقييمها ومراقبة أدائها في الوقت الفعلي.
أبرز الجوانب التقنية والخصائص:
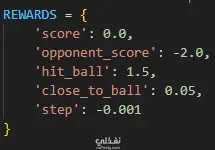
هندسة المكافآت المتقدمة (Reward Shaping): تصميم نظام مكافآت دقيق يوجه سلوك الوكيل بكفاءة، حيث يتلقى مكافآت إيجابية عند صد الكرة أو التمركز الصحيح بالقرب منها، ويتعرض لعقوبات (Penalties) عند تسجيل الخصم لهدف أو عند اتخاذ خطوات غير فعالة لتجنب إطالة اللعب بلا هدف.
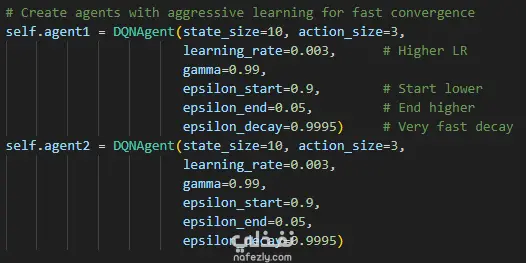
إدارة التدريب والاستكشاف: تتبع مستمر لمتغيرات التدريب الأساسية مثل عدد الجولات (Episodes)، وإجمالي الخطوات (Steps)، وتطبيق استراتيجية الاستكشاف والاستغلال (Epsilon-Greedy Exploration) مع تقليل قيمة Epsilon تدريجياً لضمان استقرار تعلم الوكيل.
حفظ وتقييم النماذج: يدعم المشروع حفظ أوزان الشبكات العصبية (بصيغة .pth الخاصة بـ PyTorch) للوكلاء المختلفين (agent1, agent2)، بالإضافة إلى حفظ إحصائيات ومقاييس التدريب في ملفات JSON لتحليل الأداء لاحقاً ورسم منحنيات التعلم.
بيئة محاكاة مرنة: توفير واجهة مستخدم (UI) تتيح التبديل بين وضع اللعب (Play Mode) لاختبار النماذج المدربة، ووضع التدريع السريع (Fast Mode) لتسريع عملية المحاكاة والتدريب.
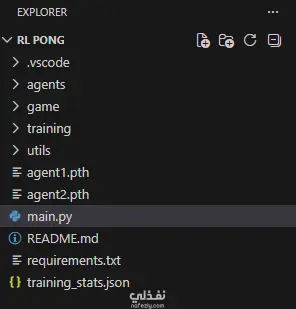
هيكلة برمجية نظيفة: تقسيم معماري للمشروع إلى وحدات برمجية منفصلة لإدارة اللعبة (game)، والوكلاء (agents)، والتدريب (training)، والأدوات المساعدة (utils)، مما يضمن سهولة الصيانة وقابلية التوسع.