تصنيف درجة الائتمان باستخدام Decision Tree
تفاصيل العمل
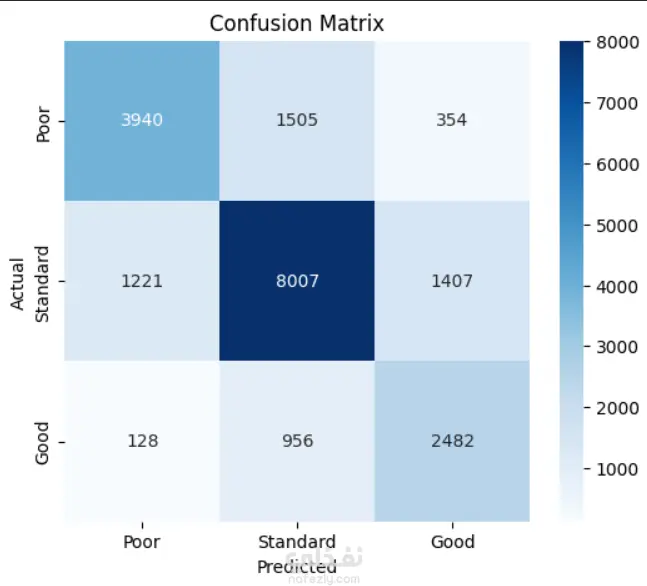
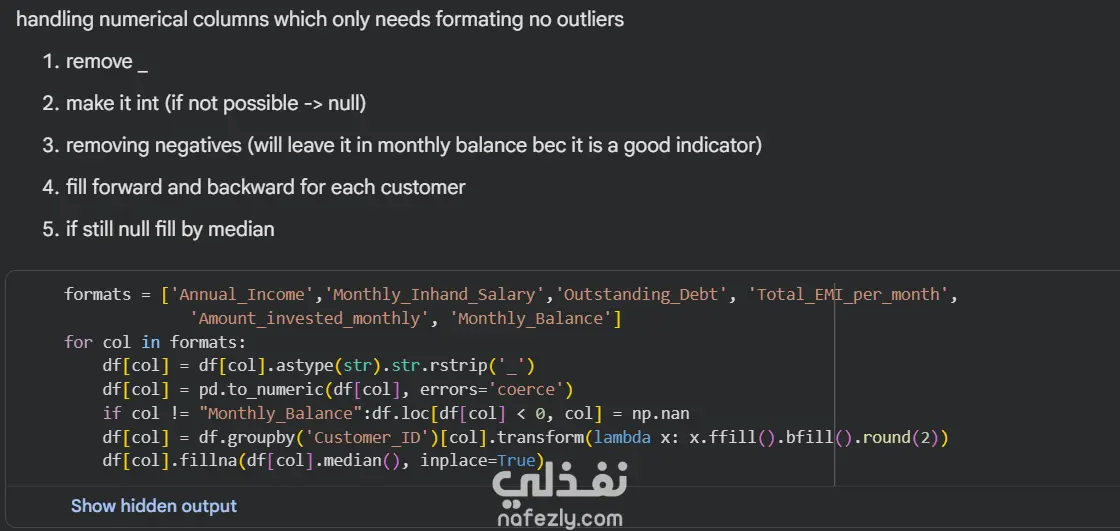
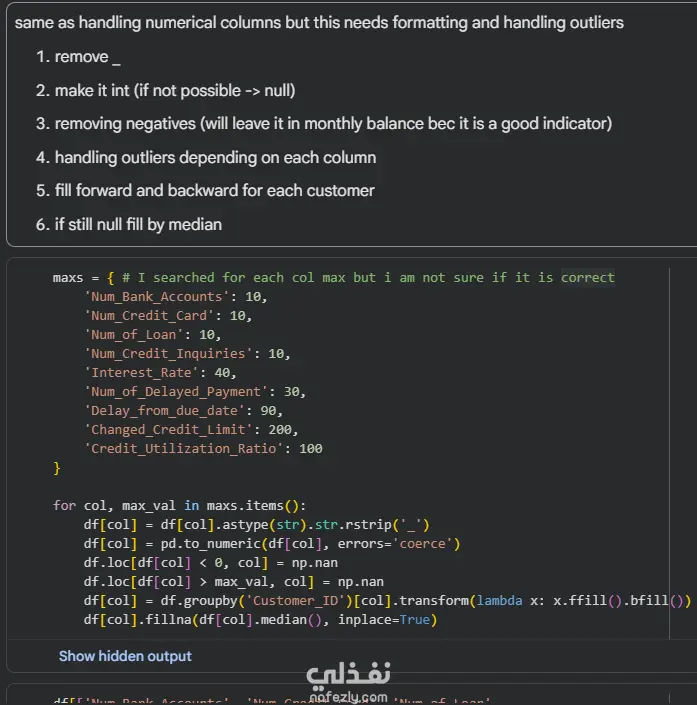
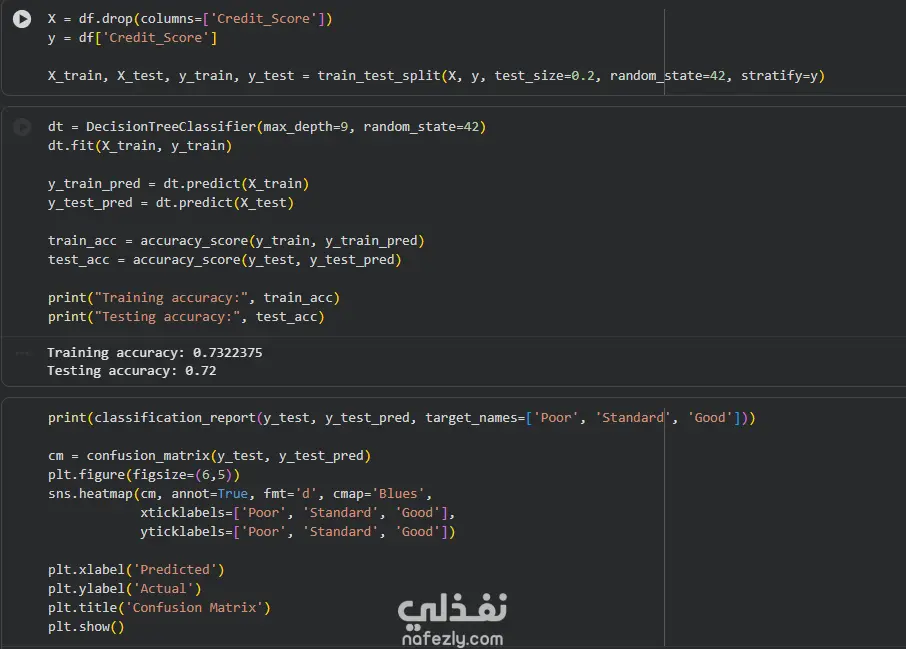
نظرة عامة في هذا المشروع، قمت ببناء نموذج شجرة قرار (Decision Tree) لتصنيف العملاء إلى ثلاث فئات ائتمانية: Poor, Standard, Good. التحدي الأكبر كان في معالجة البيانات المتسخة التي تحتوي على قيم مفقودة، قيم شاذة، وتنسيقات غير متسقة. 1.البيانات مجموعة بيانات تحتوي على 100,000 عميل و28 عمودًا، تشمل: معلومات شخصية: العمر، المهنة، الدخل السنوي. معلومات مصرفية: عدد الحسابات، عدد بطاقات الائتمان، الديون المستحقة. تاريخ ائتماني: مدة التاريخ الائتماني، التأخير في السداد، سلوك الدفع. 2.خطوات المعالجة (Data Cleaning) إزالة الأعمدة غير المفيدة (ID, Name, SSN). تشفير الشهور يدويًا. معالجة العمر: إزالة القيم السالبة وملء المفقود بالوسيط لكل عميل. تجميع المهن إلى فئات (Professional, Education, Media, Business) وتطبيق one-hot encoding. تنظيف الأعمدة الرقمية: إزالة الشرطة السفلية "_"، تحويل إلى numeric، إزالة القيم السالبة، ملء المفقود باستخدام forward/backward fill لكل عميل ثم الوسيط. تحديد القيم القصوى المعقولة لكل عمود وإزالة القيم الشاذة. معالجة Credit_Mix: استبدال "_" بـ NaN، ملء بالـ mode. تحويل Credit_History_Age من نص إلى عدد أشهر. معالجة Payment_Behaviour: استبدال القيم غير الصالحة، ملء المفقود، ثم ترميزها. تشفير الهدف (Credit_Score) إلى أرقام. 3.النموذج والنتائج النموذج: DecisionTreeClassifier (max_depth=9) دقة التدريب: 73.2% دقة الاختبار: 72.0%
مهارات العمل
بطاقة العمل

طلب عمل مماثل












