تحليل ومقارنة أداء خوارزميات التعلم الآلي (ML Model Comparison)
تفاصيل العمل
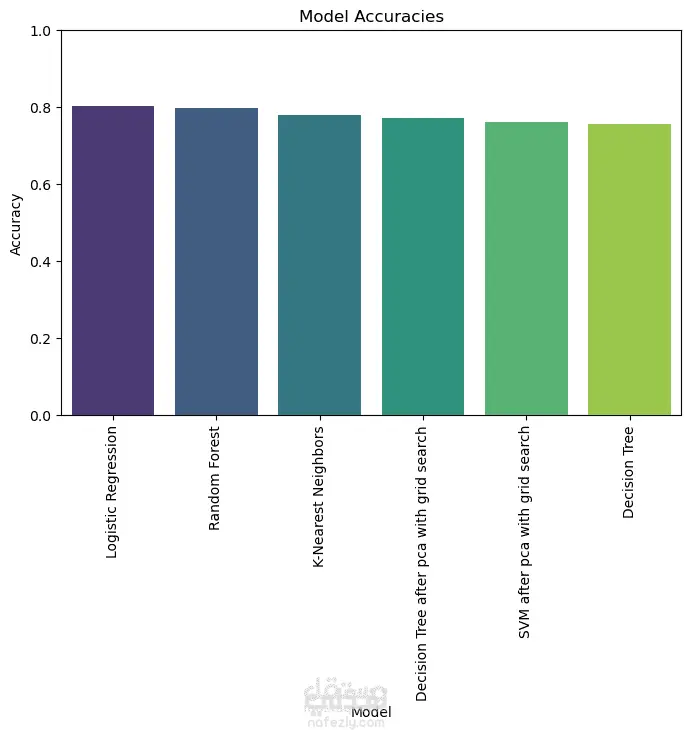
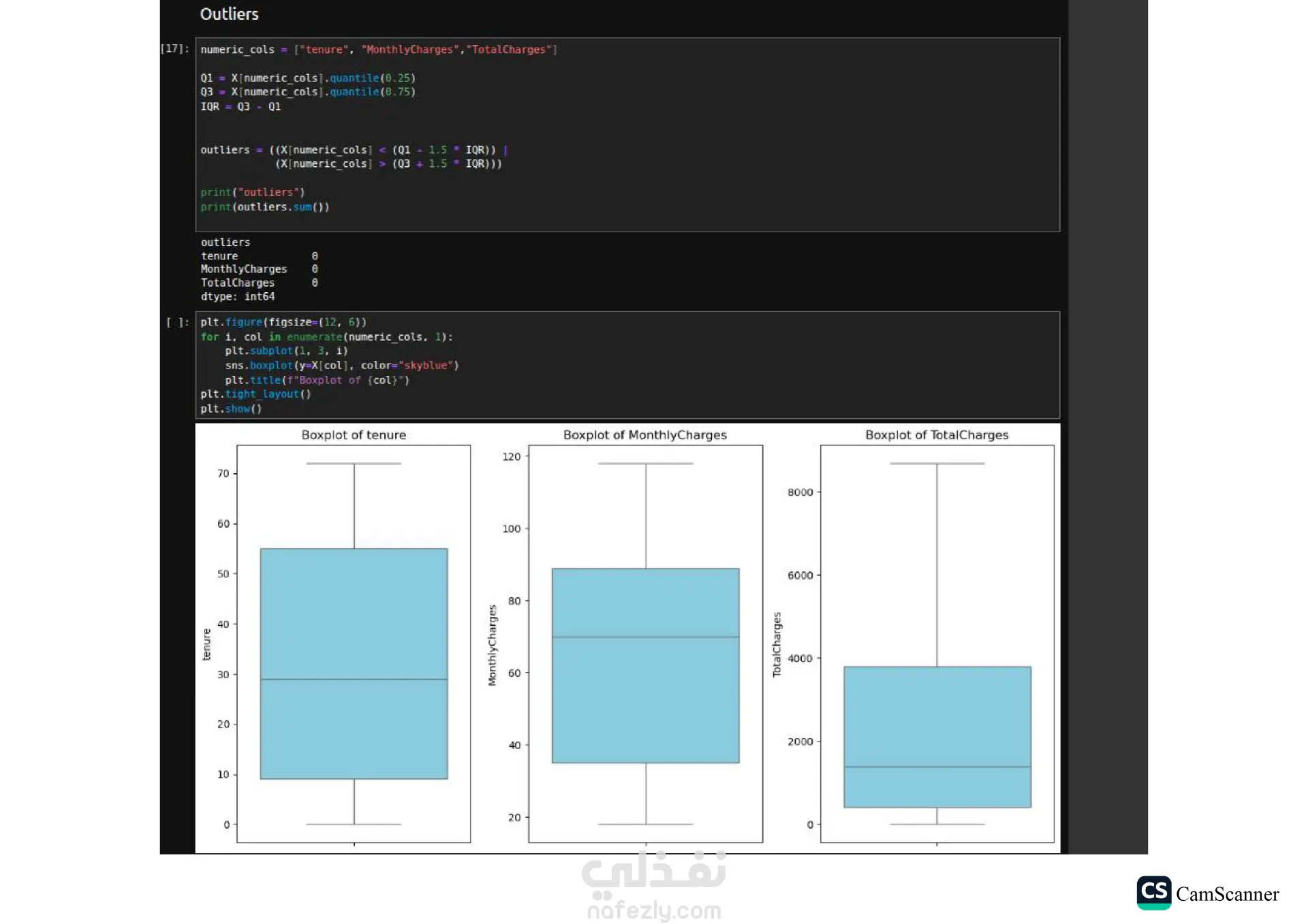
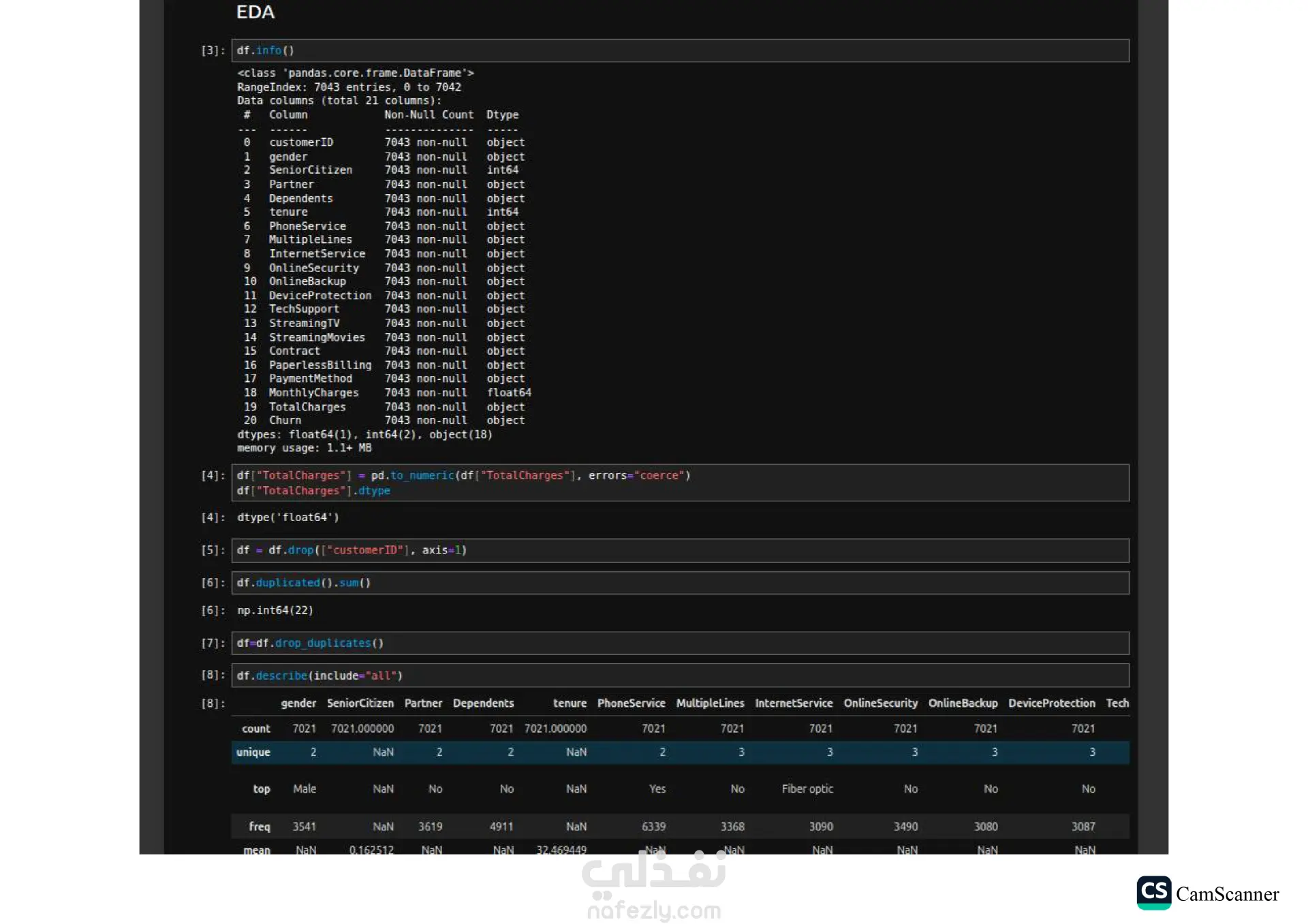
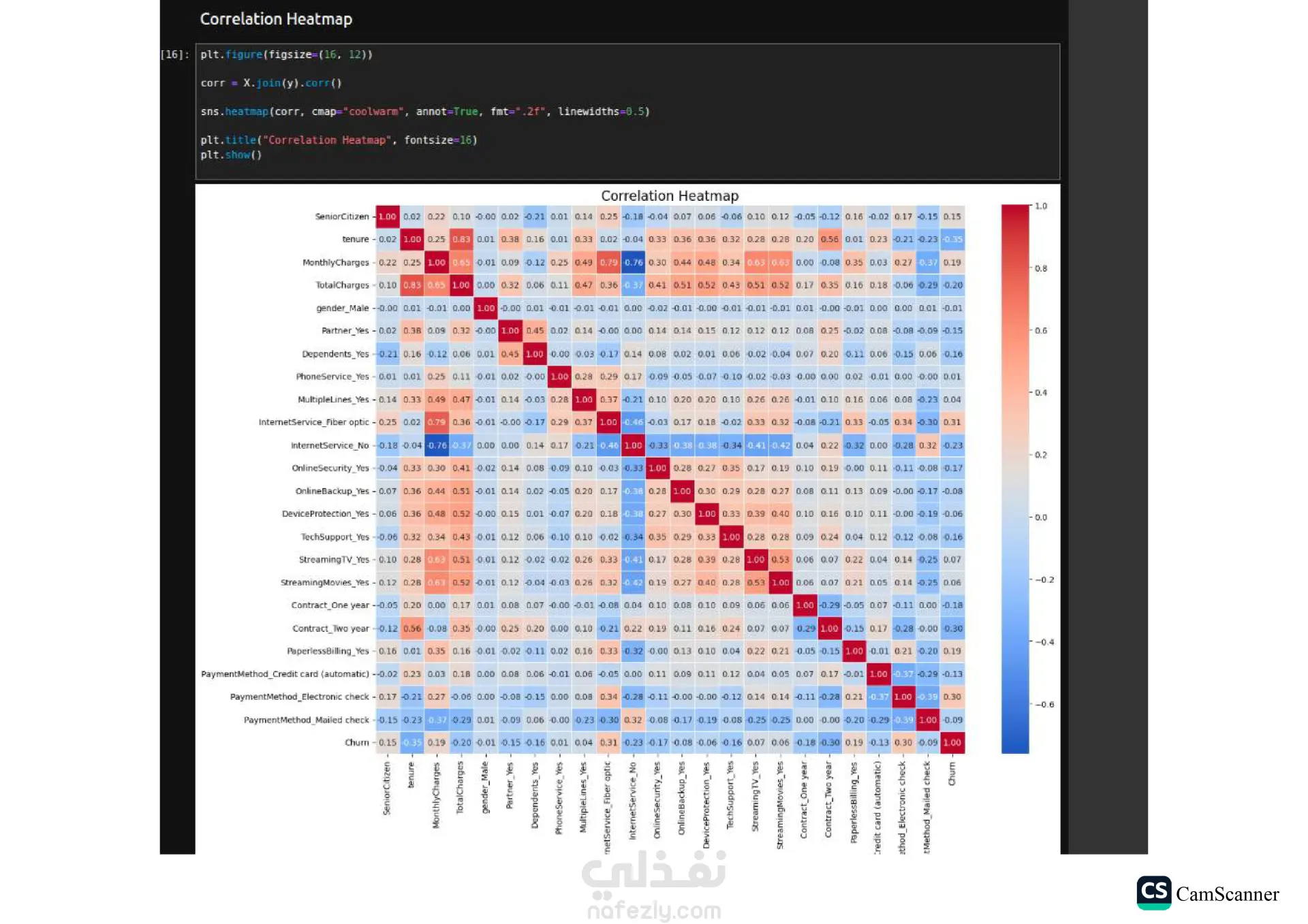
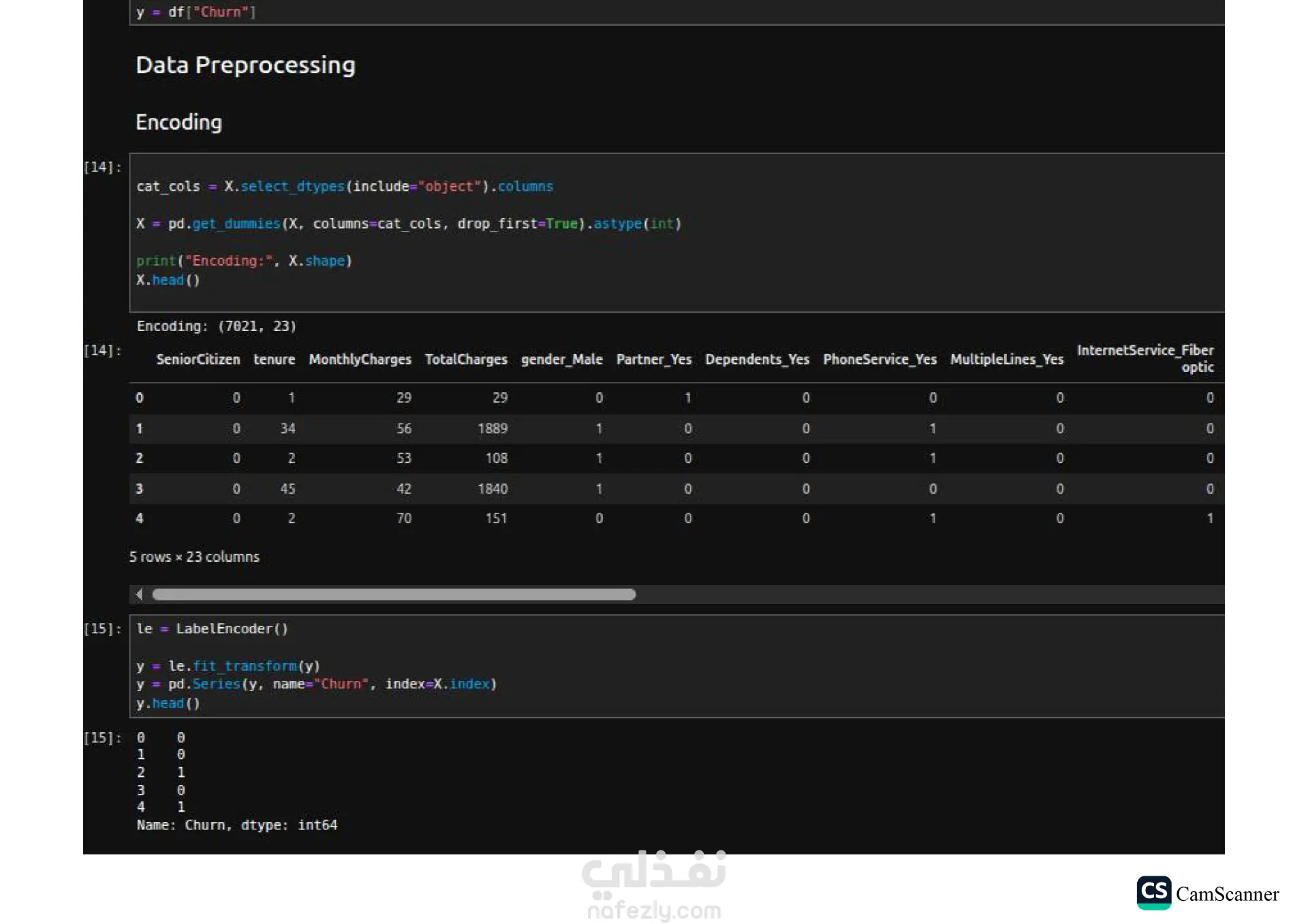
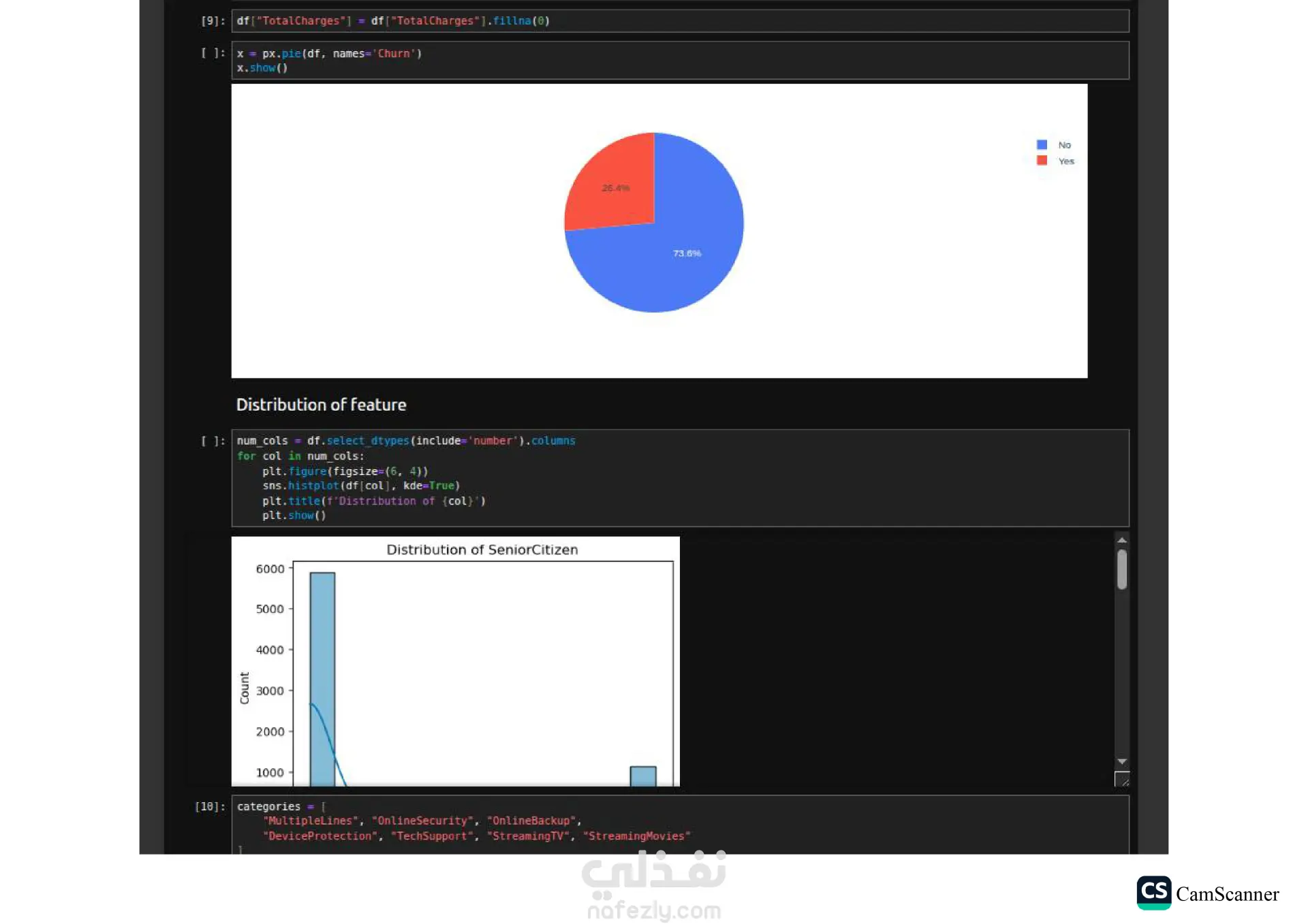
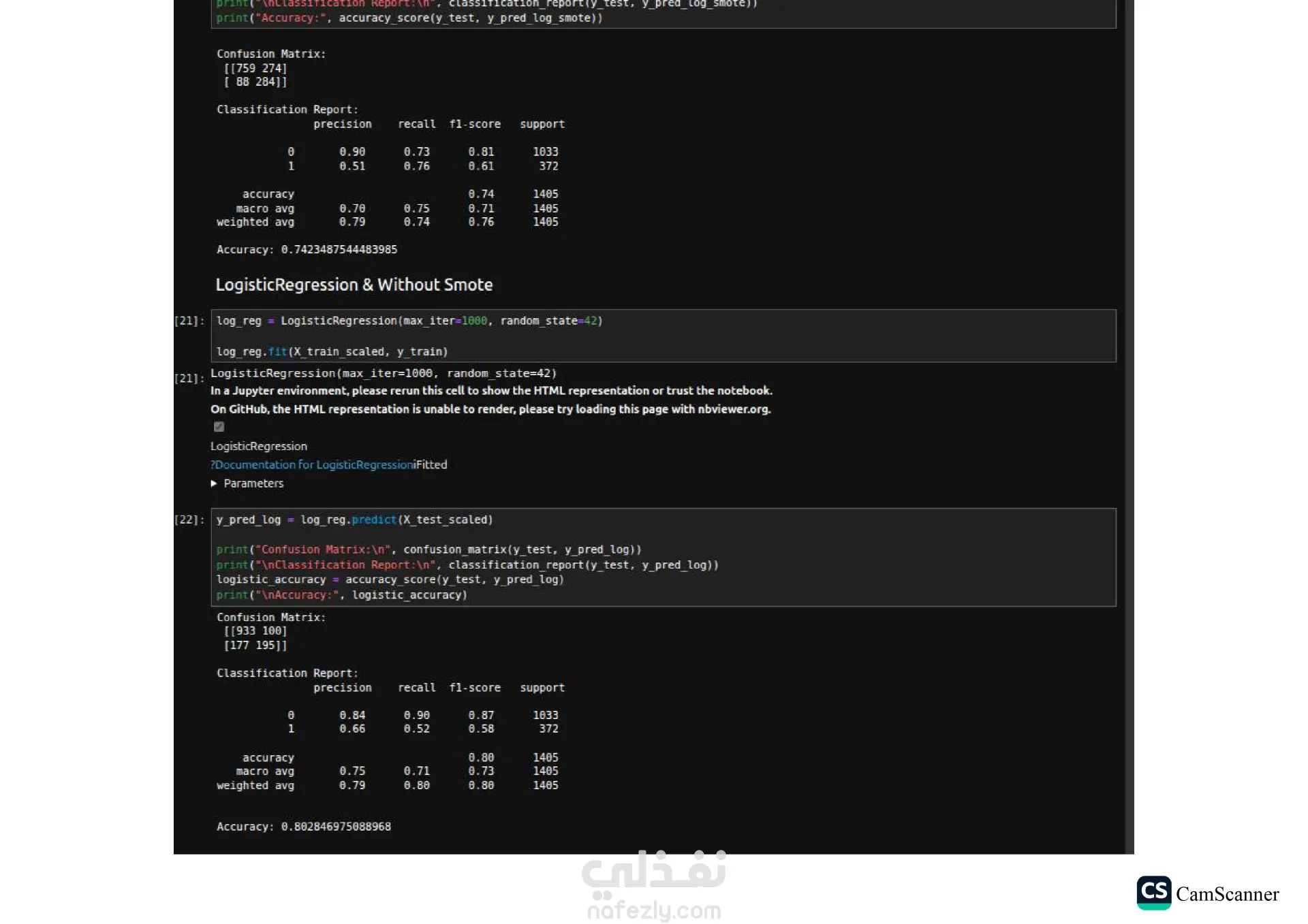
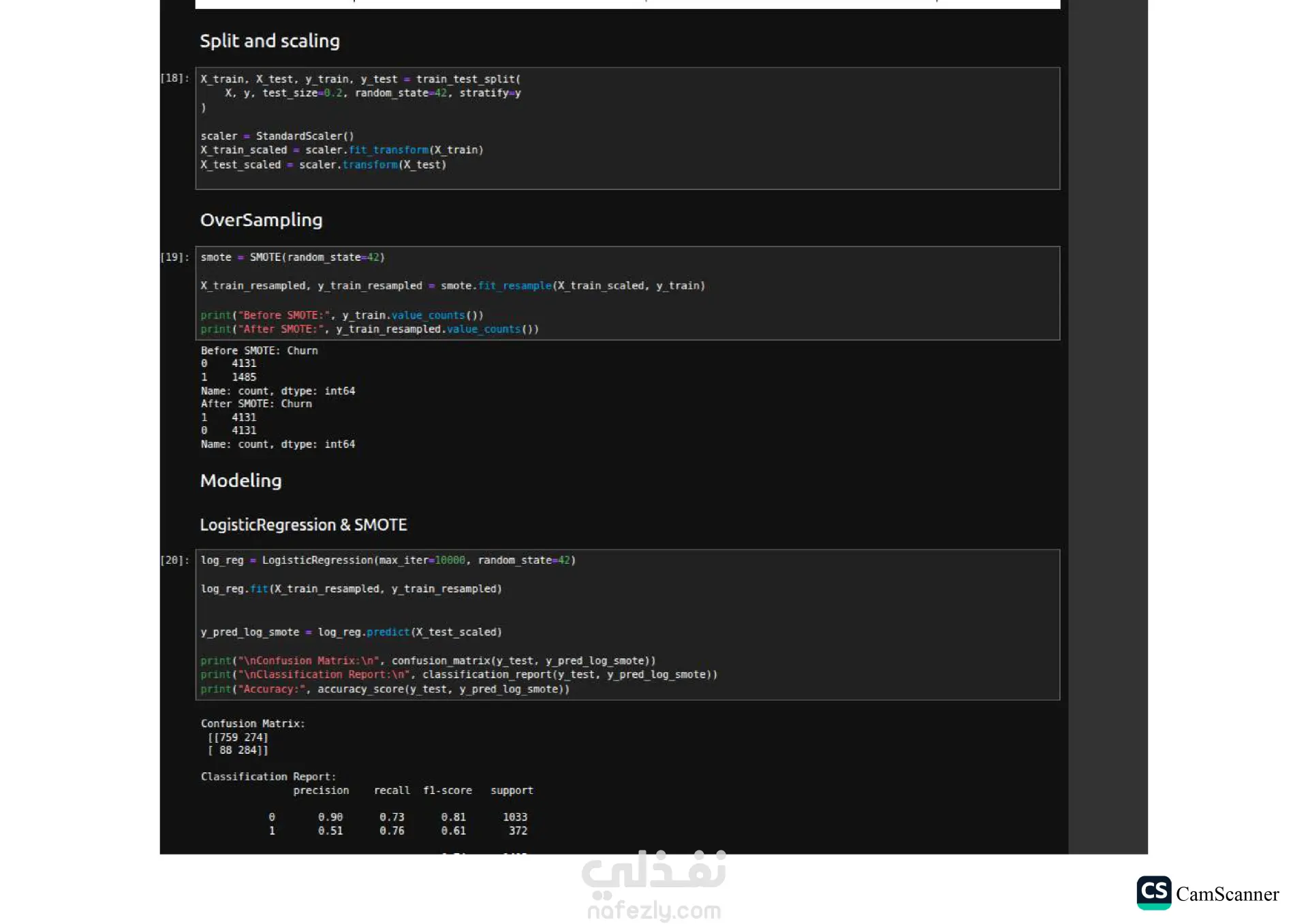
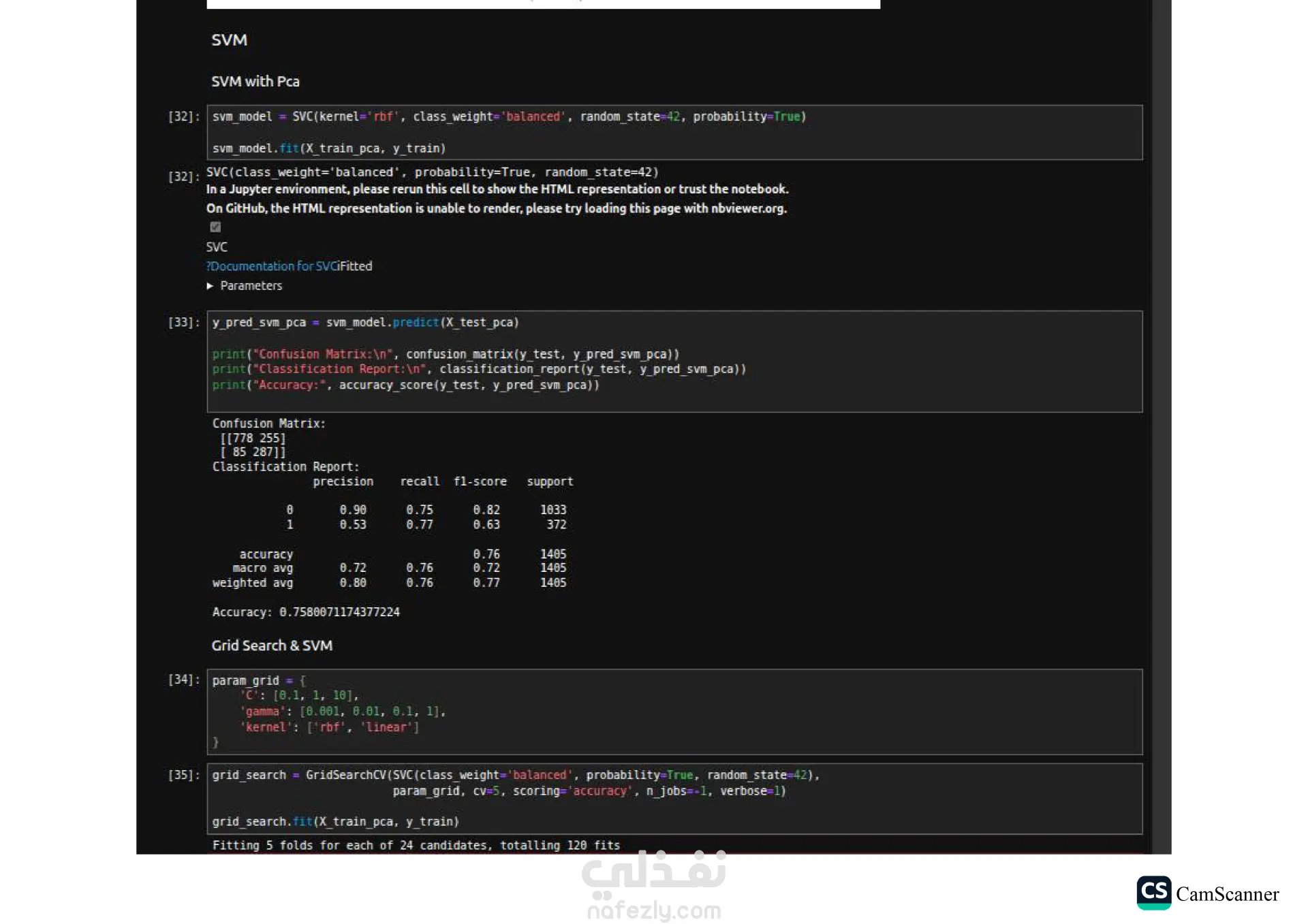
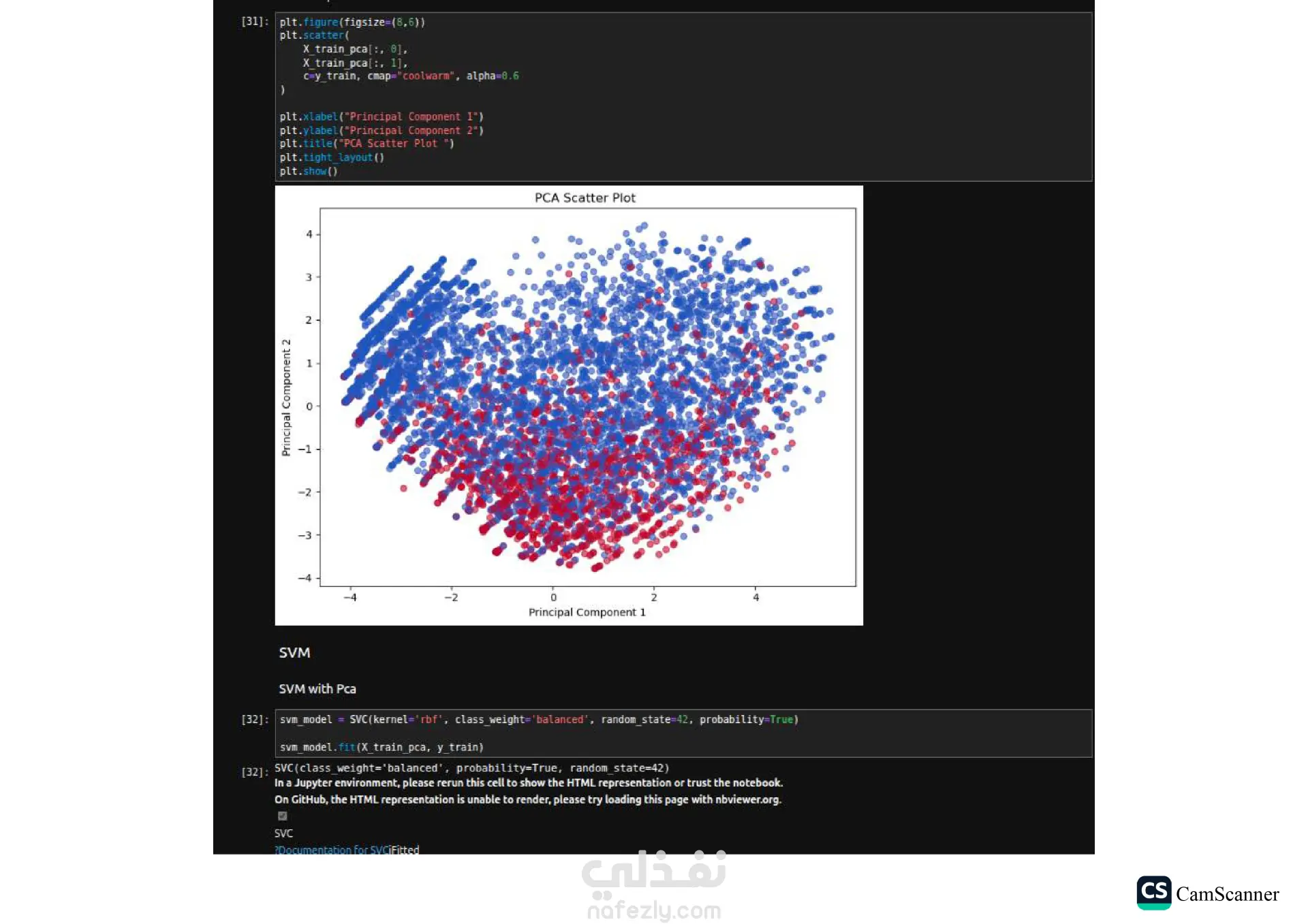
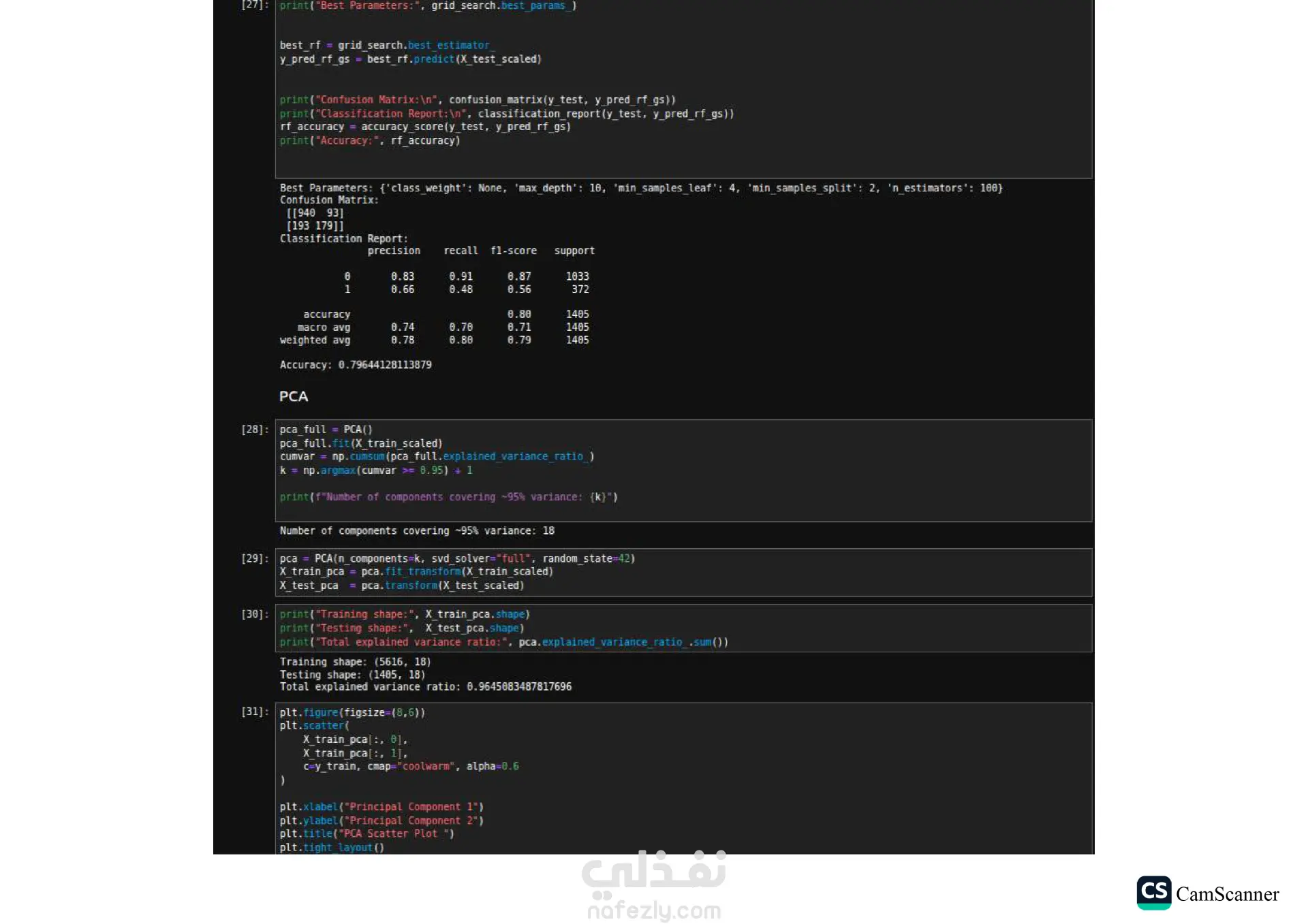
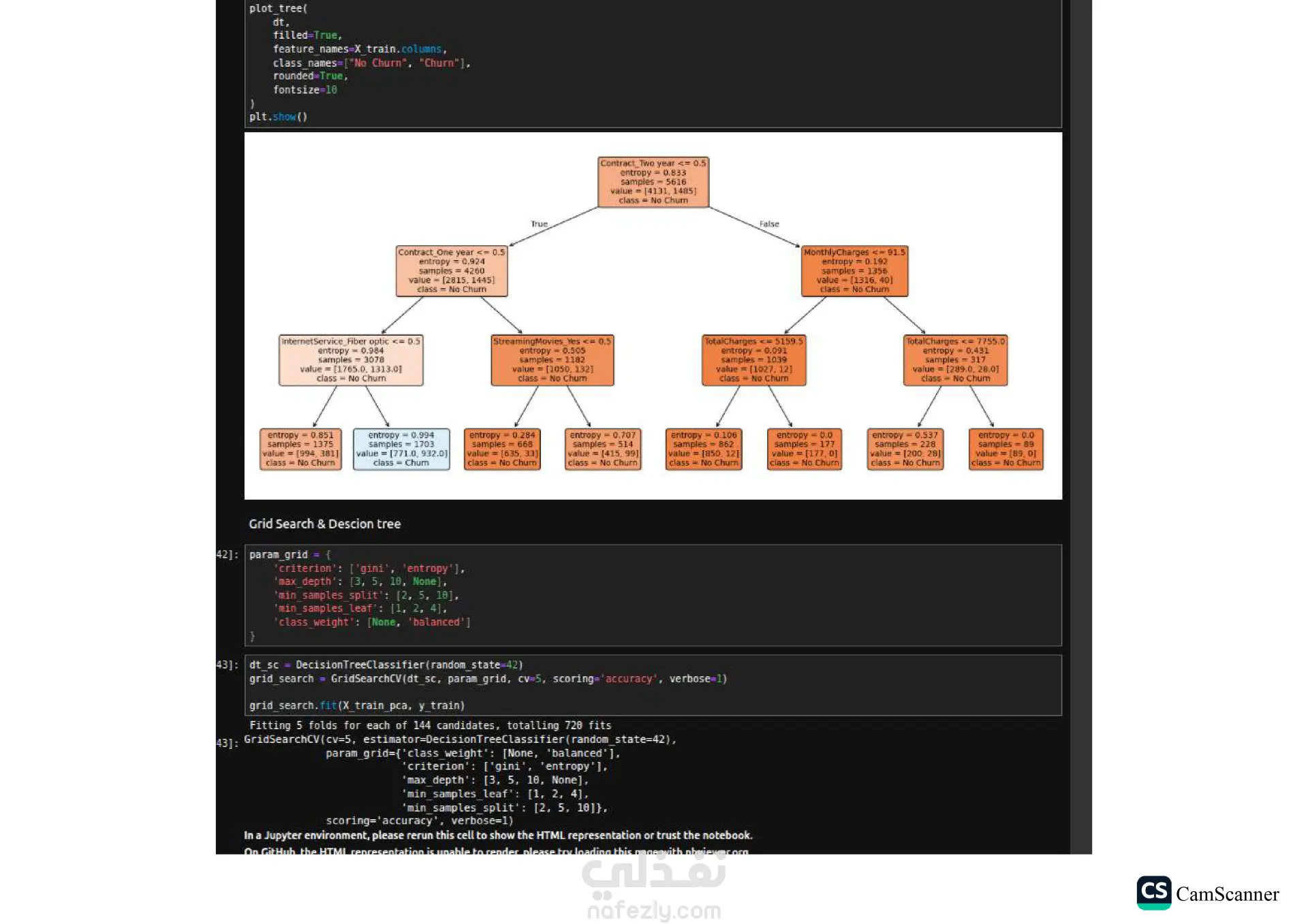
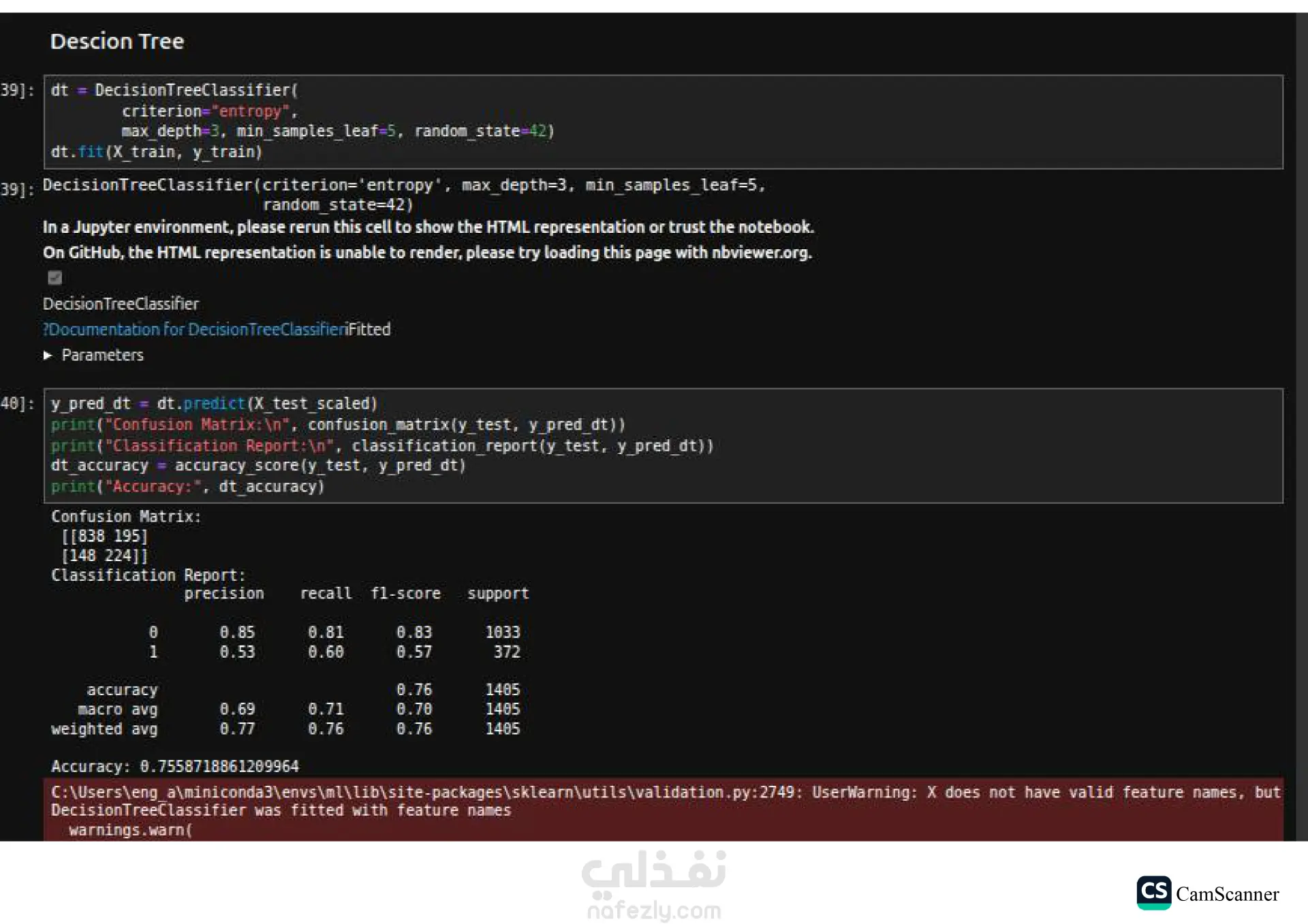
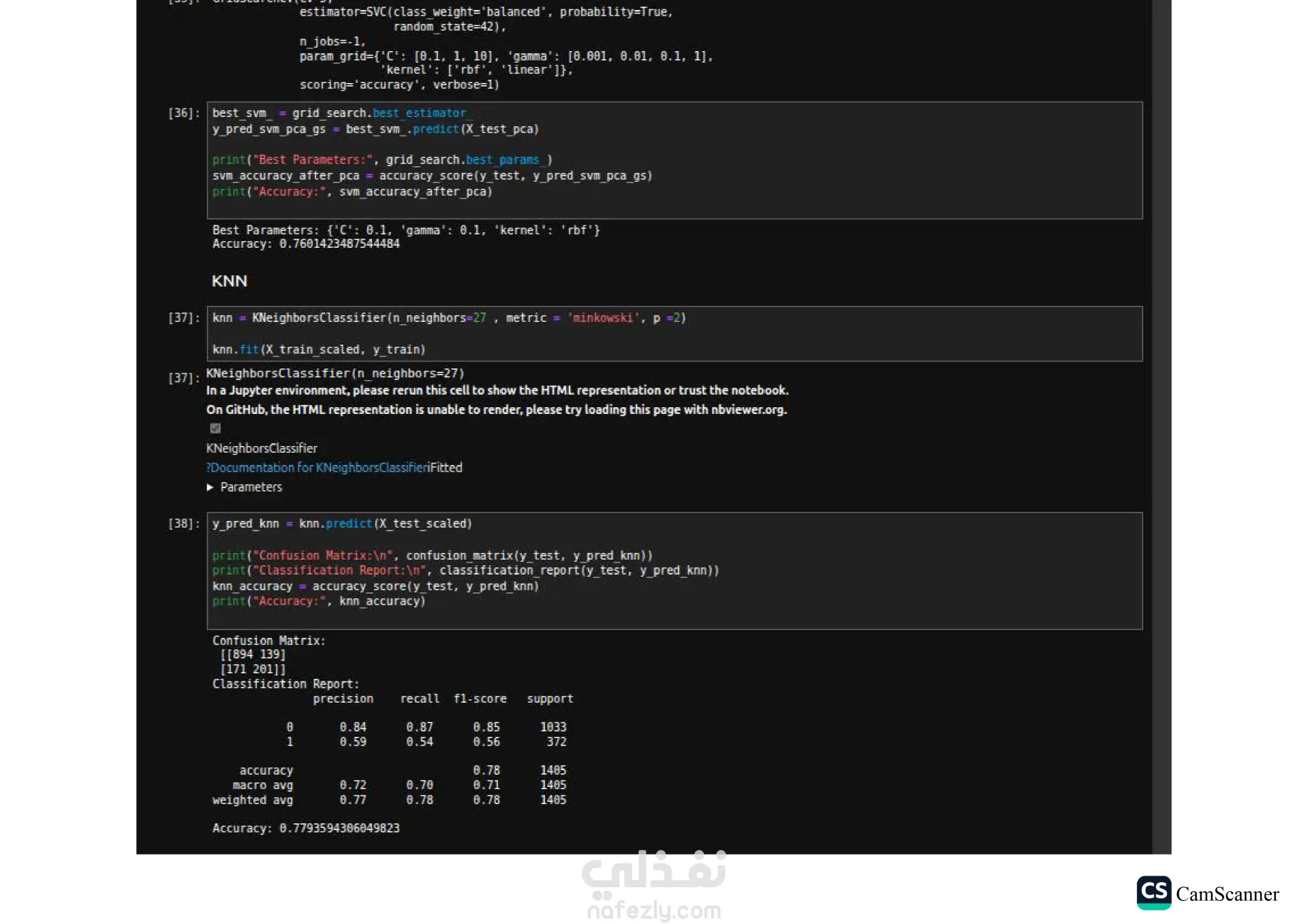
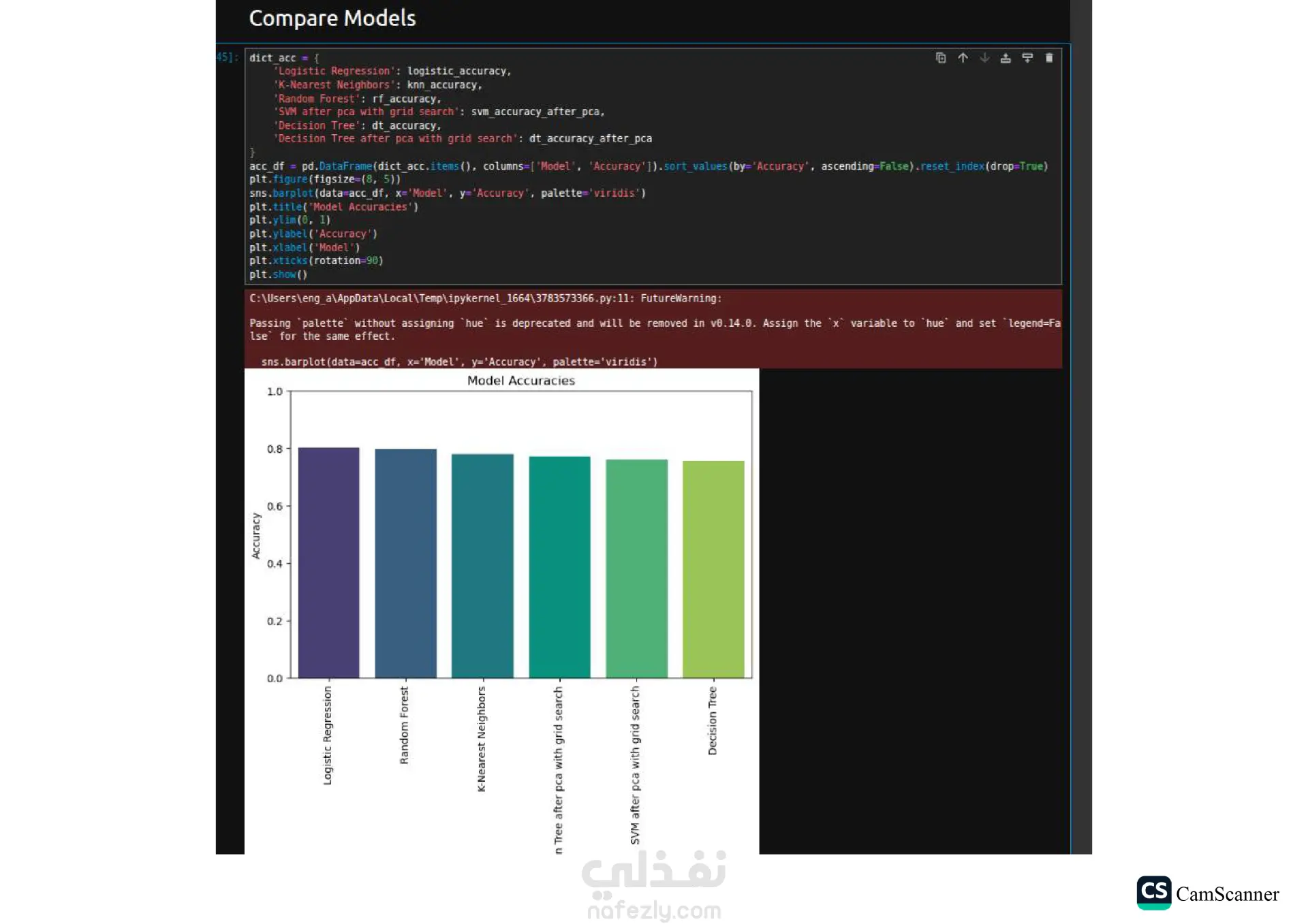
نبذة عن المشروع: يهدف هذا المشروع إلى تحليل مجموعة بيانات وبناء نماذج تنبؤية (Classification Models) للمفاضلة بين الخوارزميات المختلفة واختيار الأكثر دقة وكفاءة للتعامل مع البيانات. الخطوات والتقنيات المستخدمة: معالجة البيانات (Data Preprocessing): تنظيف البيانات وتجهيزها للتدريب. تقليل الأبعاد (Dimensionality Reduction): استخدام تقنية PCA لتقليل تعقيد البيانات وتحسين سرعة المعالجة لبعض النماذج. تحسين النماذج (Hyperparameter Tuning): استخدام Grid Search للبحث عن أفضل القيم للمتغيرات (Parameters) للحصول على أفضل أداء ممكن. الخوارزميات المستخدمة: تم تدريب واختبار مجموعة متنوعة من الخوارزميات، منها: Logistic Regression Random Forest K-Nearest Neighbors (KNN) Support Vector Machines (SVM) Decision Trees التقييم والعرض (Evaluation & Visualization): مقارنة النتائج بناءً على دقة النموذج (Accuracy)، وتمثيل النتائج بيانيًا باستخدام مكتبة Seaborn لتسهيل اتخاذ القرار. النتائج: أظهرت النتائج تفوق نموذج Logistic Regression في هذه الحالة بدقة تصل إلى 80%، مما يجعله الخيار الأمثل لهذه البيانات، مع تقارب ملحوظ في أداء Random Forest. الأدوات: Python, Pandas, Scikit-Learn, Matplotlib, Seaborn.
مهارات العمل
بطاقة العمل

طلب عمل مماثل












