This project involves the analysis and prediction of insurance charges using a dataset that includes features such as age, sex, BMI, number of children, smoking status, and region. The goal is to build a model that predicts insurance charges based on these features.
Key steps involved in the project:
Data Preprocessing: The dataset was cleaned by removing duplicates and handling categorical variables. It also included visualization to understand data distributions and relationships.
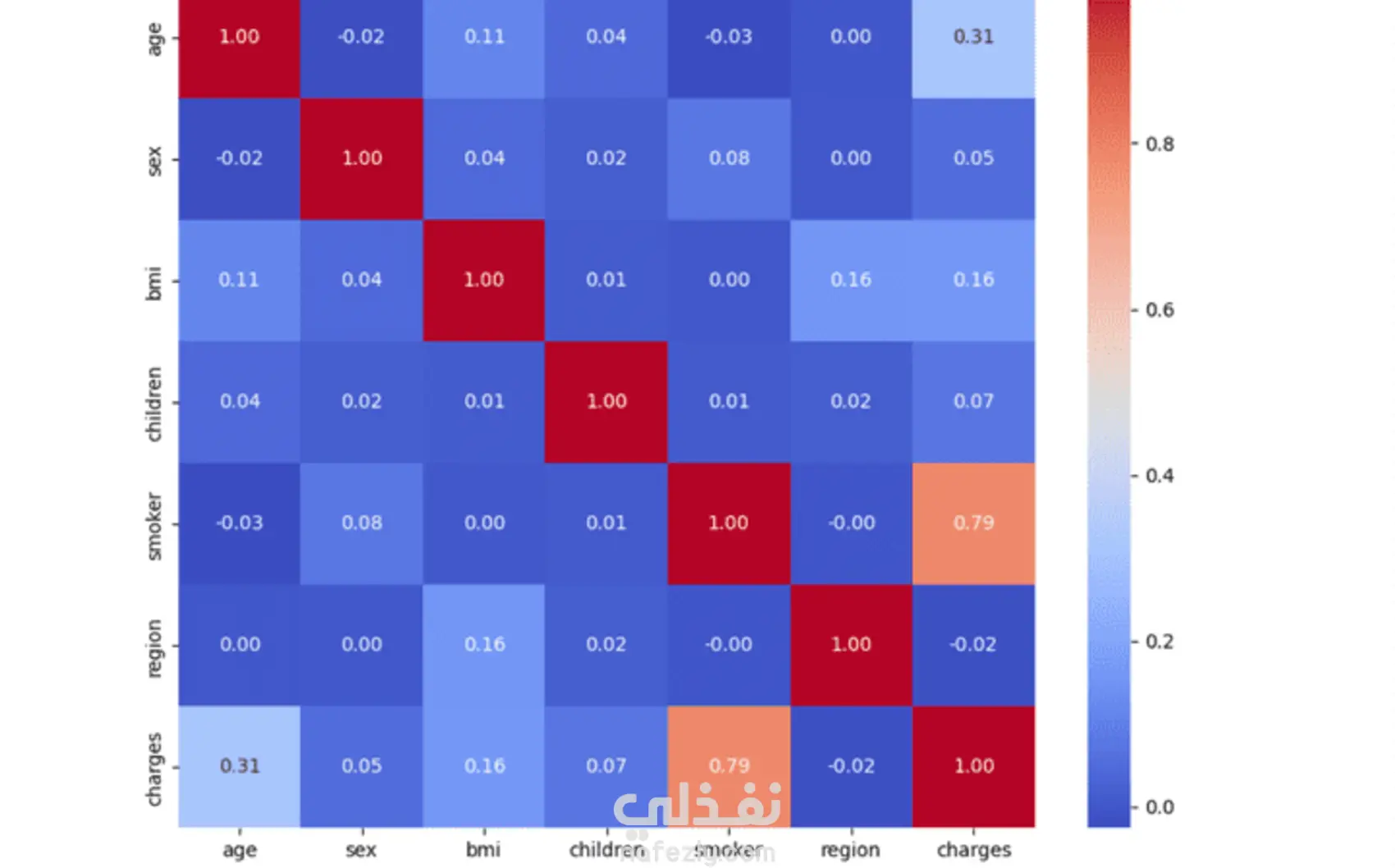
Exploratory Data Analysis (EDA): Visualizations such as scatter plots and box plots were used to understand the relationships between features like age, BMI, and charges.
Feature Engineering: Categorical features were encoded, and the dataset was prepared for modeling.
Modeling: Various regression models were implemented, including Decision Tree, Linear Regression, Gradient Boosting, and XGBoost. Their performance was compared using evaluation metrics like MAE, MSE, and R² Score.
Model Evaluation: After training and testing the models, the Gradient Boosting model provided the best performance with an R² Score of 0.87.
This project demonstrates proficiency in data cleaning, feature engineering, and model building, making use of advanced techniques like XGBoost to improve prediction accuracy.