توقع الانتماء الحزبي لأعضاء الكونجرس باستخدام التعلم الآلي.
تفاصيل العمل
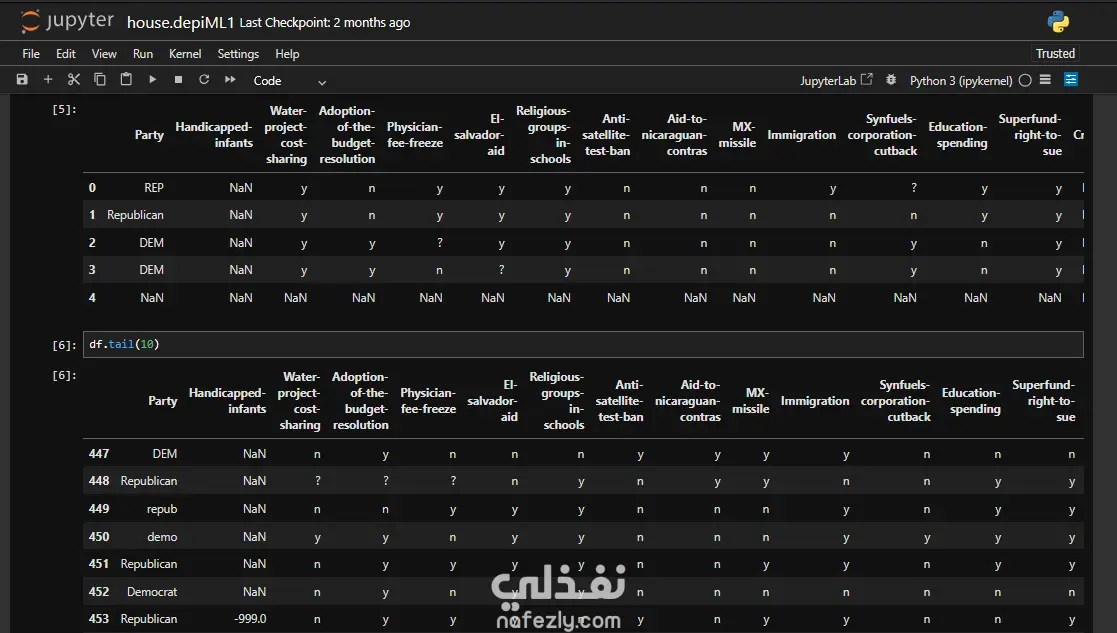
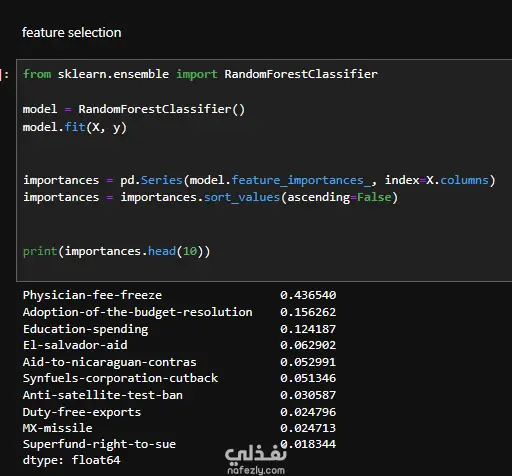
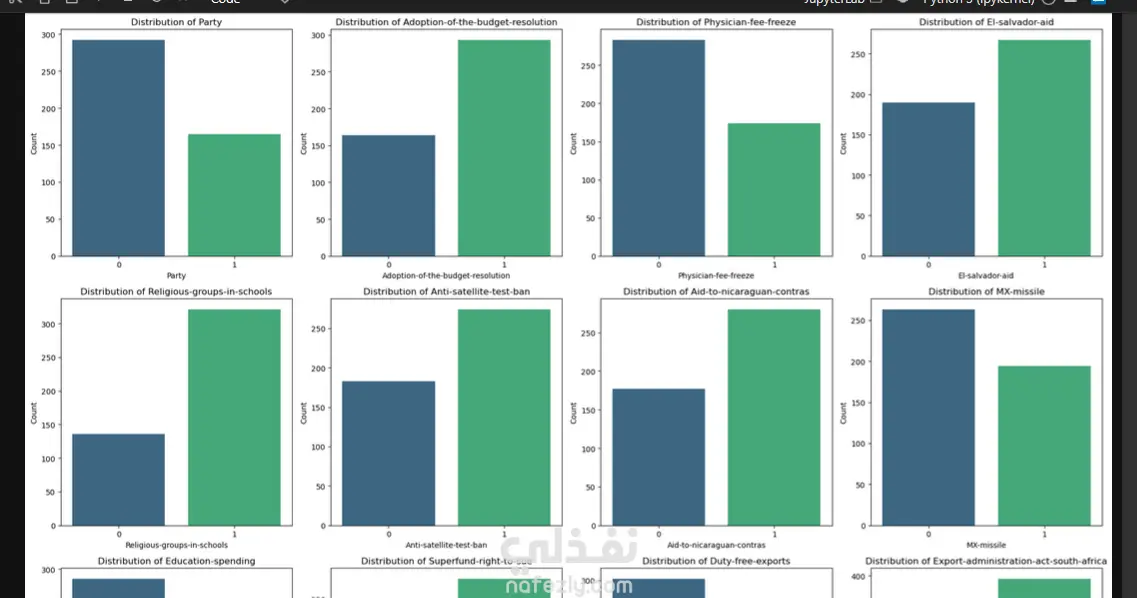
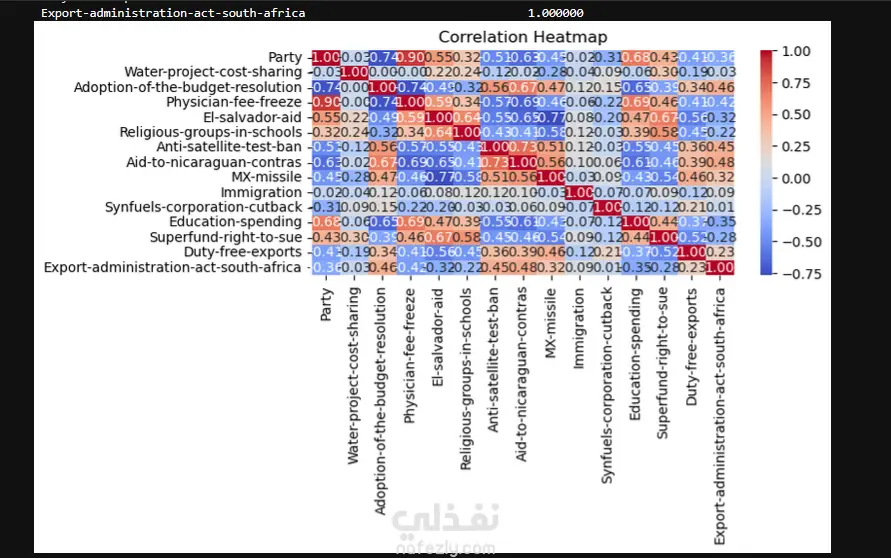
هدف المشروع: تطوير نموذج تعلم آلي (Machine Learning) للتنبؤ بالانتماء الحزبي لأعضاء الكونجرس الأمريكي (ديمقراطي/جمهوري) بناءً على سجلات تصويتهم في قضايا مفصلية. معالجة البيانات (Data Preprocessing): تنظيف البيانات ومعالجة القيم المفقودة (NaN) وغير المعروفة (؟) باستخدام طريقة الـ Mode Imputation للحفاظ على حجم البيانات ومنع حدوث Underfitting. استبعاد الأعمدة ذات القيم المفقودة العالية جداً مثل (Handicapped-infants و Crime) لضمان جودة النموذج. توحيد وتصحيح التسميات في العمود المستهدف (Target Column) لضمان دقة التصنيف. هندسة البيانات (Feature Engineering): تحويل المتغيرات الفئوية (Categorical Variables) إلى صيغة رقمية مناسبة للنمذجة. إجراء تحليل الارتباط (Correlation Analysis) وحذف المتغيرات المتكررة (Redundancy) مثل 'Immigration' و 'Water-project' لتقليل تعقيد النموذج. النمذجة والنتائج: استخدام تقنية الـ Stacking Ensemble Model لتحسين دقة التوقعات، مما أدى للوصول إلى دقة نهائية بلغت 96%. تحليل أهمية الميزات (Feature Importance)، حيث تبين أن التصويت على (Physician-fee-freeze) و (Adoption-of-the-budget-resolution) هما أقوى المؤشرات على التوجه الحزبي.
مهارات العمل
بطاقة العمل

طلب عمل مماثل












