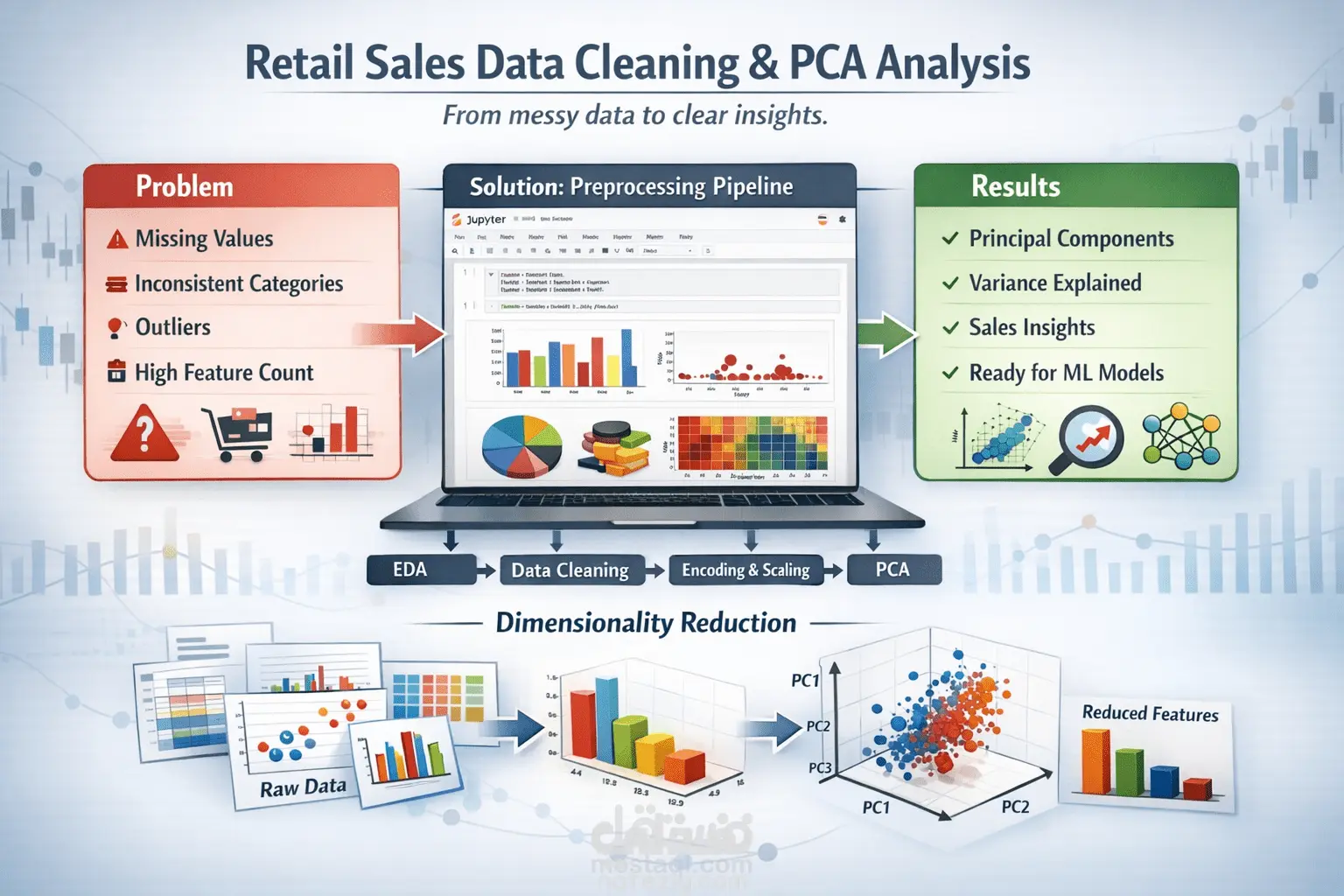
Problem
Retail sales datasets contain missing values, inconsistent categories, and outliers.
High feature count makes analysis and modeling harder.
Sales prediction suffers without clean data.
Solution
A complete preprocessing pipeline in one Jupyter notebook.
Includes EDA, cleaning, encoding, scaling, and PCA.
Produces clear visual outputs for analysis and reporting.
Idea
Reduce more than ten numerical and categorical features into a few principal components.
Preserve most data variance.
Prepare data for machine learning models.