استخراج البيانات من بطاقات الهوية باستخدام OCR (Tesseract + Python)

تفاصيل العمل
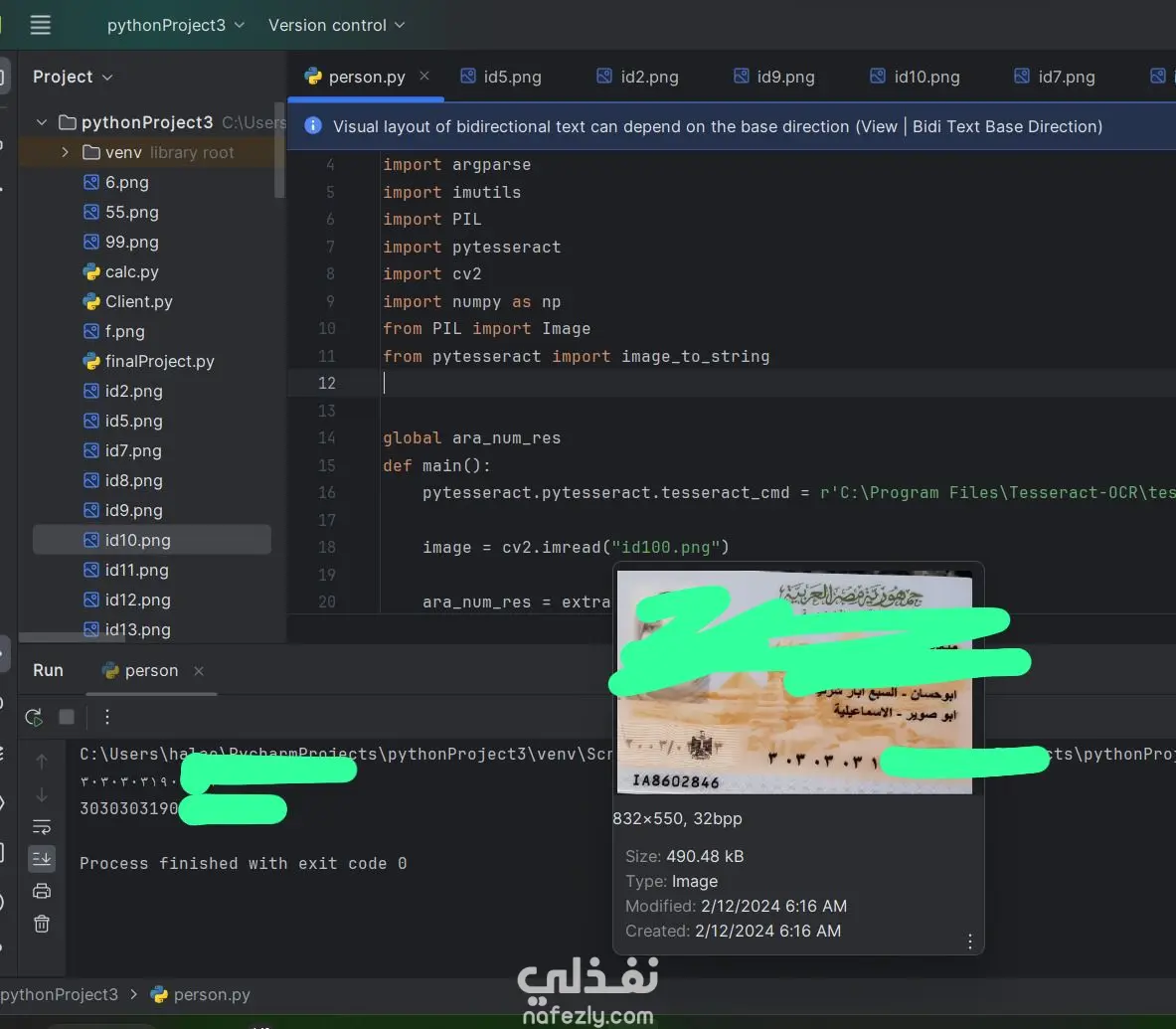
قمت بتنفيذ مشروع تعرّف ضوئي على الحروف (OCR) باستخدام لغة Python ومكتبة Tesseract لاستخراج البيانات النصية من صور بطاقات الهوية المصرية. يهدف المشروع إلى أتمتة قراءة الأرقام والنصوص العربية من الصور، وتحويلها إلى بيانات رقمية قابلة للاستخدام في الأنظمة المختلفة. يشمل العمل: قراءة الصور باستخدام OpenCV معالجة الصور لتحسين دقة التعرف (Preprocessing) استخدام مكتبة Tesseract لاستخراج النص العربي من الصور استخراج الرقم القومي من البطاقة تحويل الأرقام العربية إلى أرقام إنجليزية تلقائيًا تنظيف النص الناتج من الرموز غير المرغوبة طباعة النتائج النهائية بشكل منظم دعم عدة صور داخل نفس المشروع تم تنظيم الكود بشكل نظيف وقابل للتطوير لإضافة حقول أخرى مستقبلًا مثل الاسم والعنوان وتاريخ الميلاد. ? الأدوات والتقنيات المستخدمة: Python OpenCV Tesseract OCR Pytesseract
مهارات العمل
بطاقة العمل

طلب عمل مماثل














