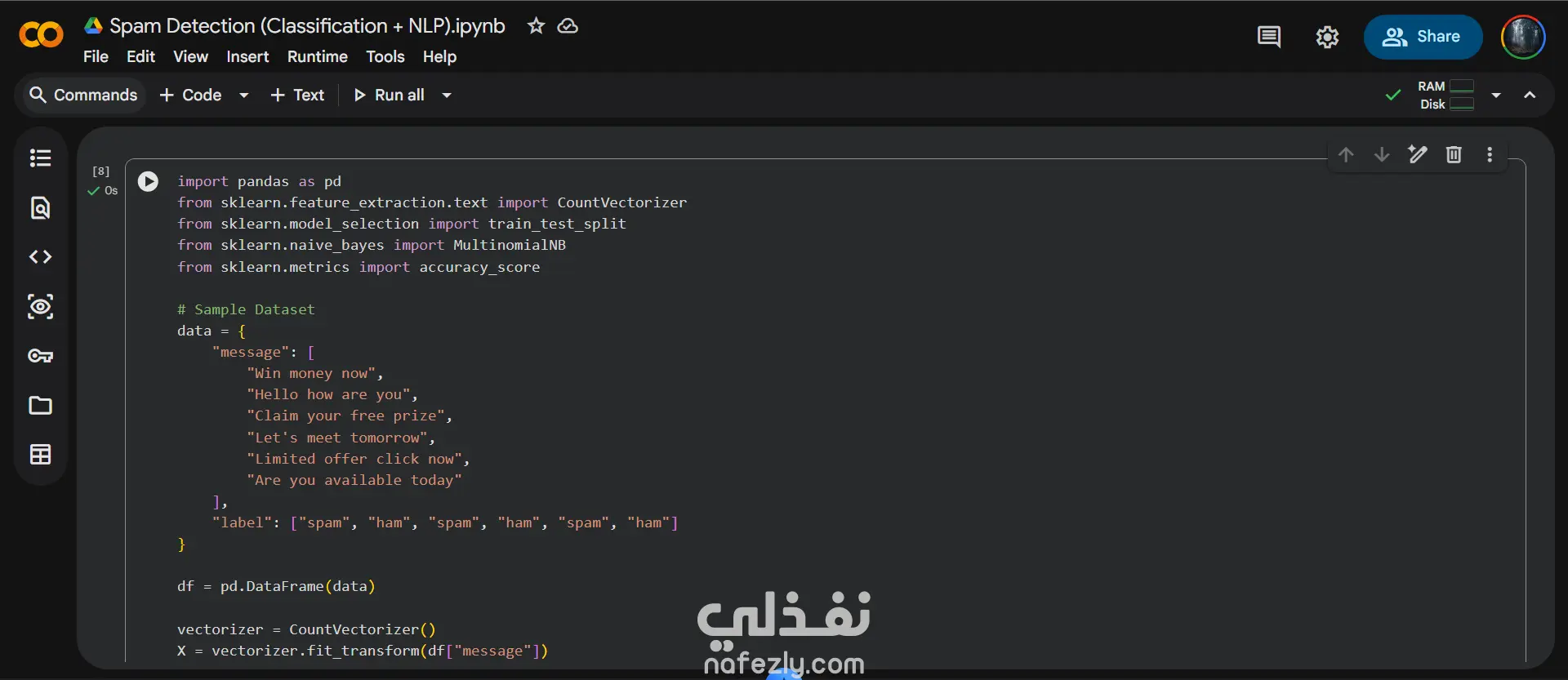
يهدف هذا المشروع إلى بناء نموذج ذكاء اصطناعي بسيط لتصنيف الرسائل النصية إلى:
رسائل مزعجة (Spam)
رسائل عادية (Ham)
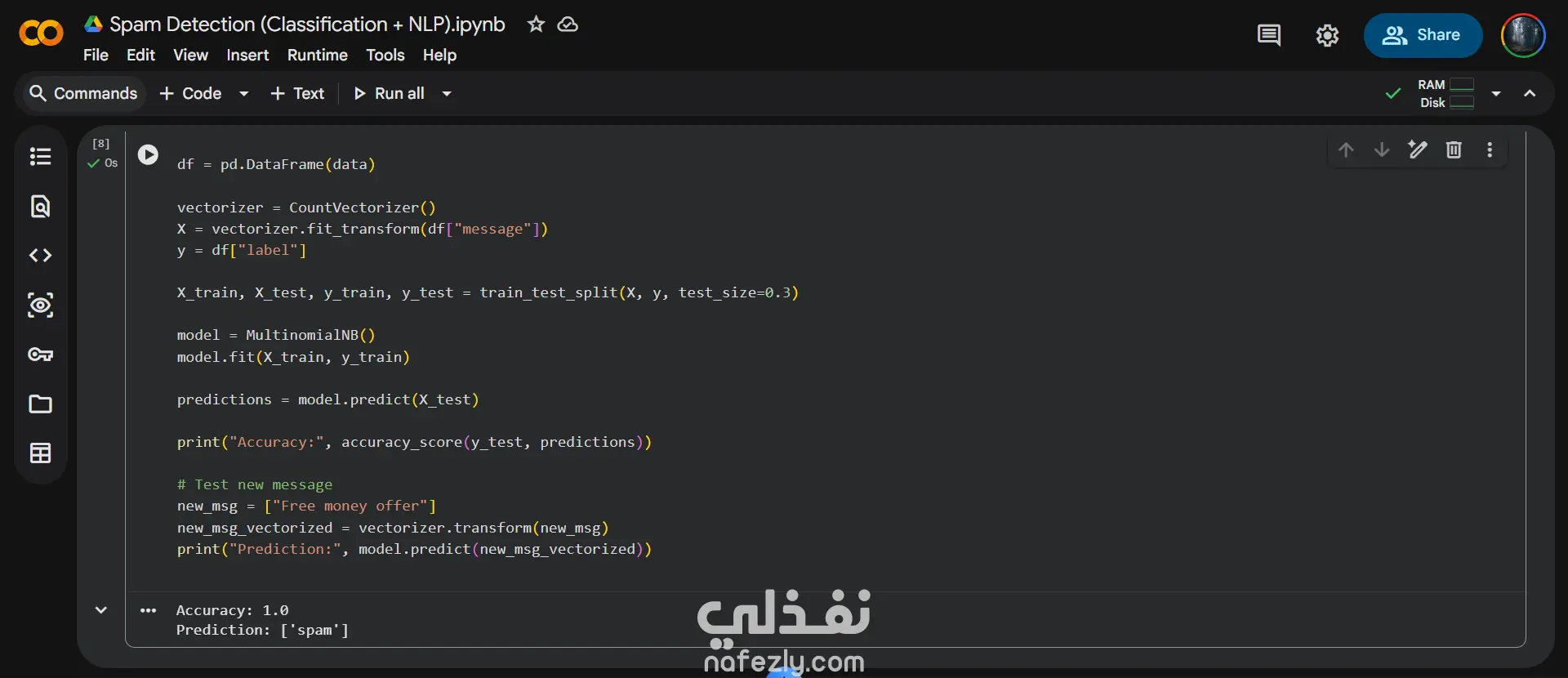
تم تطبيق تقنيات المعالجة الأولية للنصوص (NLP) باستخدام CountVectorizer، ثم تدريب نموذج تصنيف باستخدام خوارزمية Naive Bayes من مكتبة Scikit-learn.
يعكس المشروع فهمي لمفاهيم:
Natural Language Processing
Text Vectorization
Classification
Accuracy & Evaluation Metrics