Delivery Logistics



تفاصيل العمل
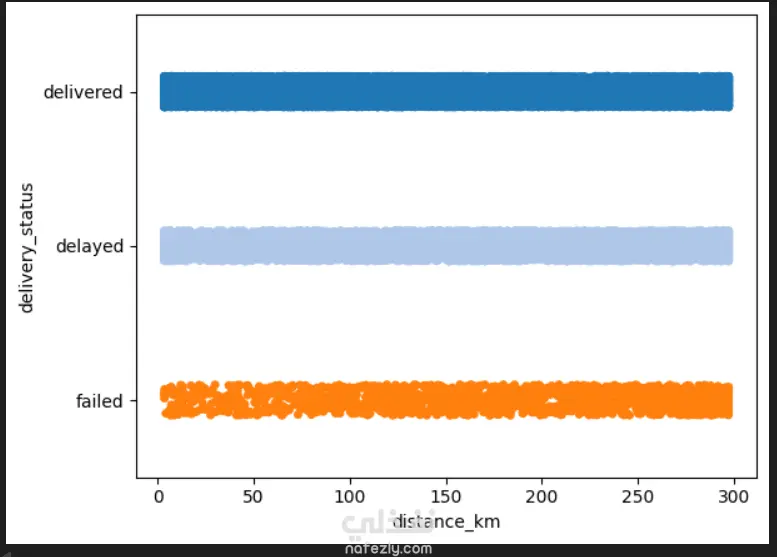
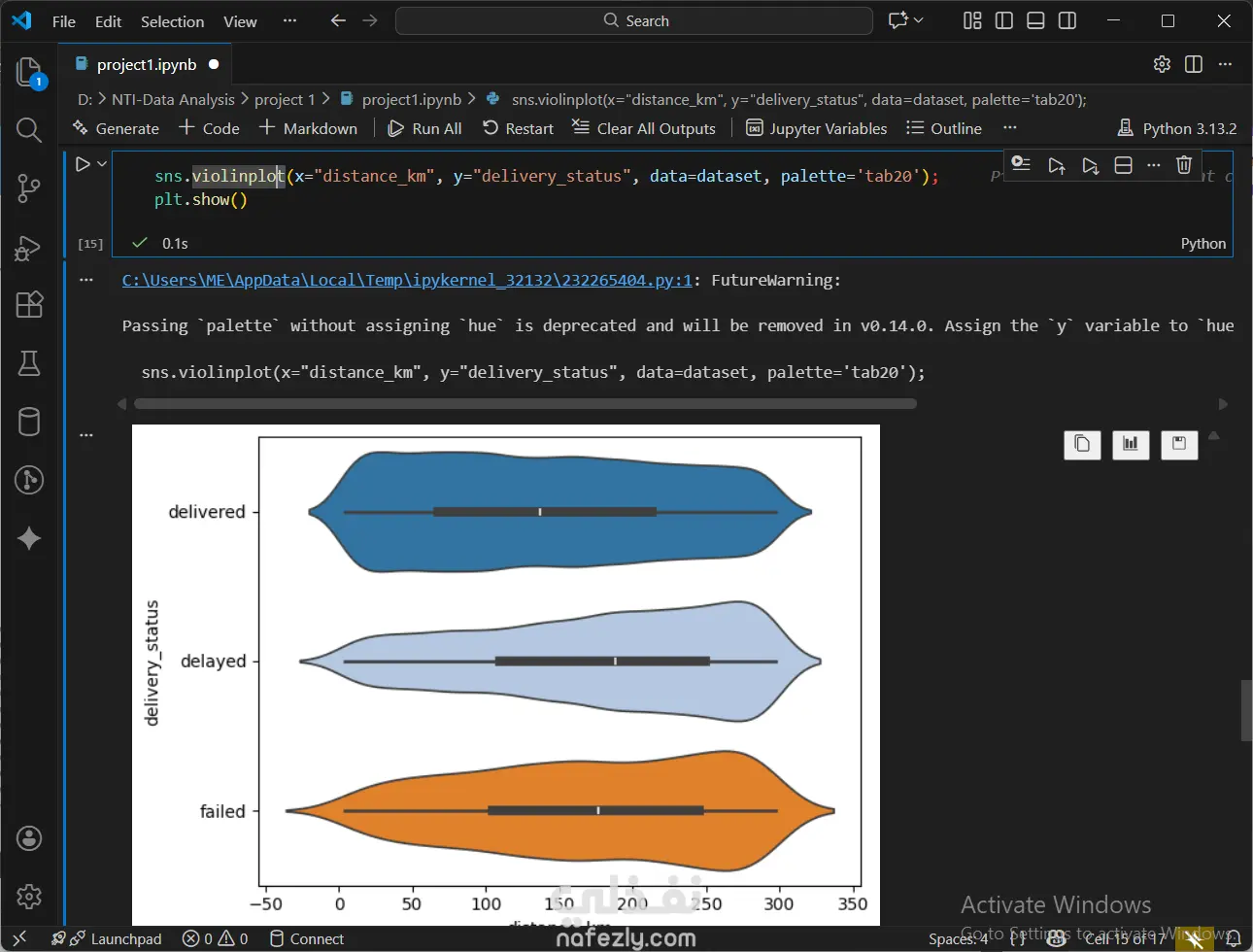
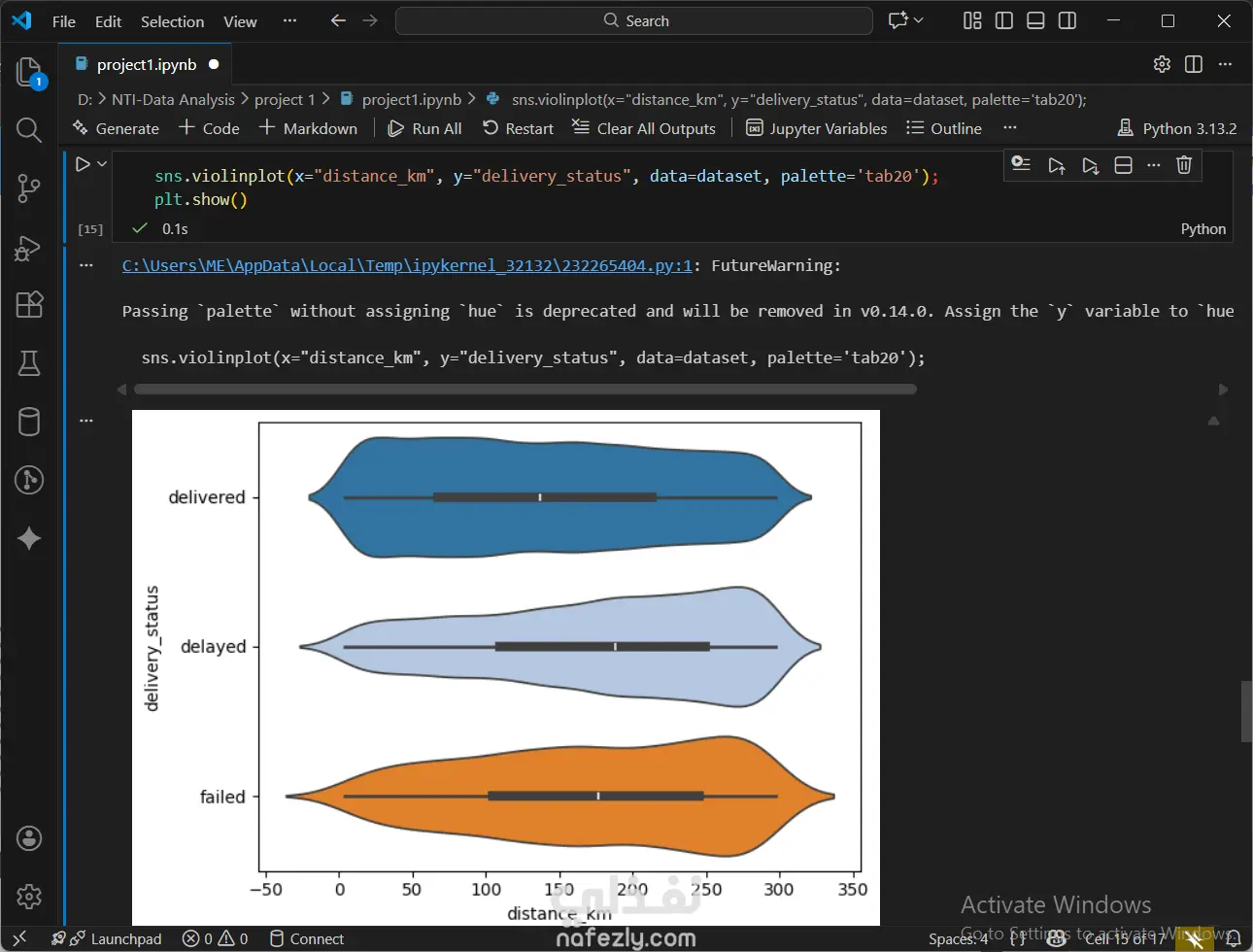
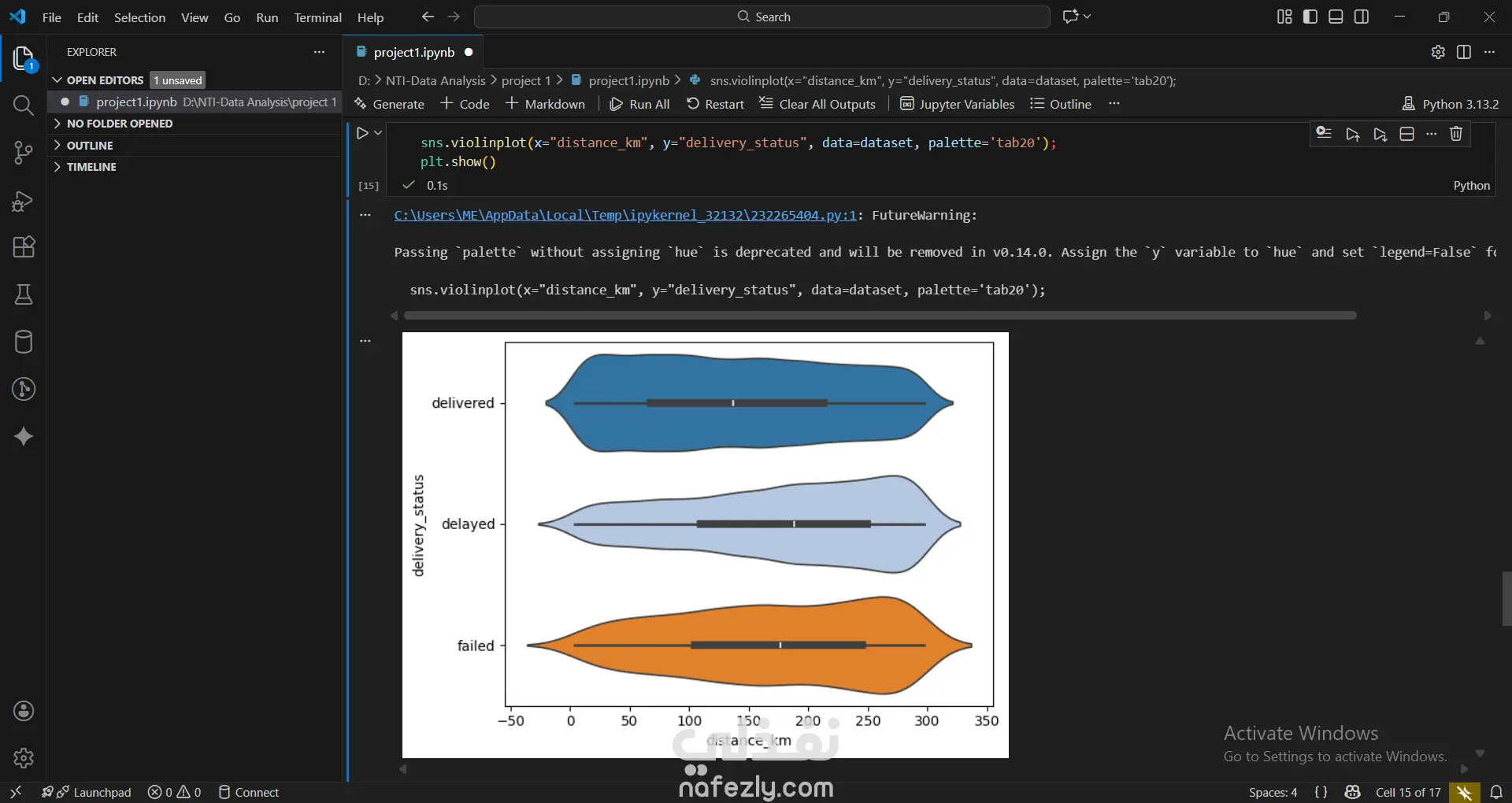
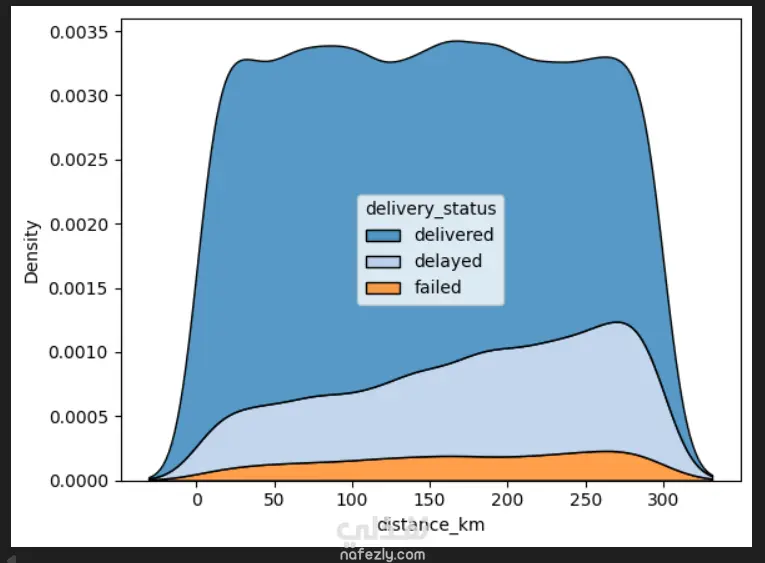
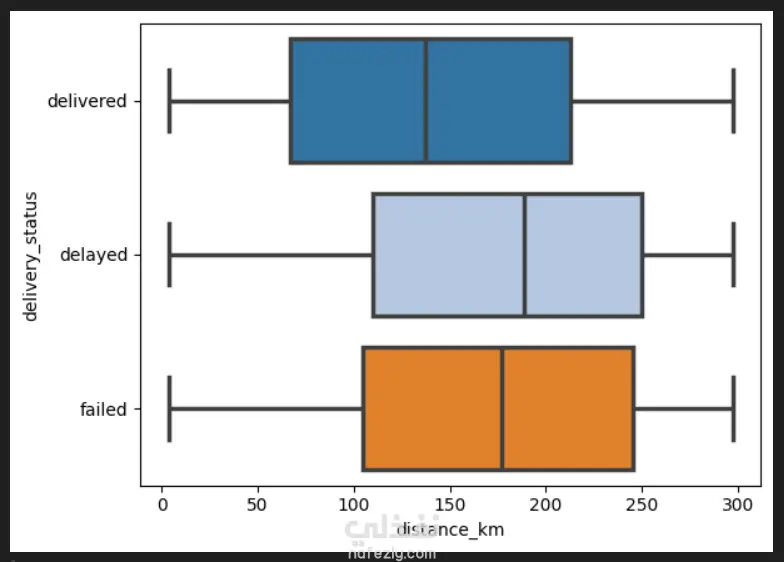
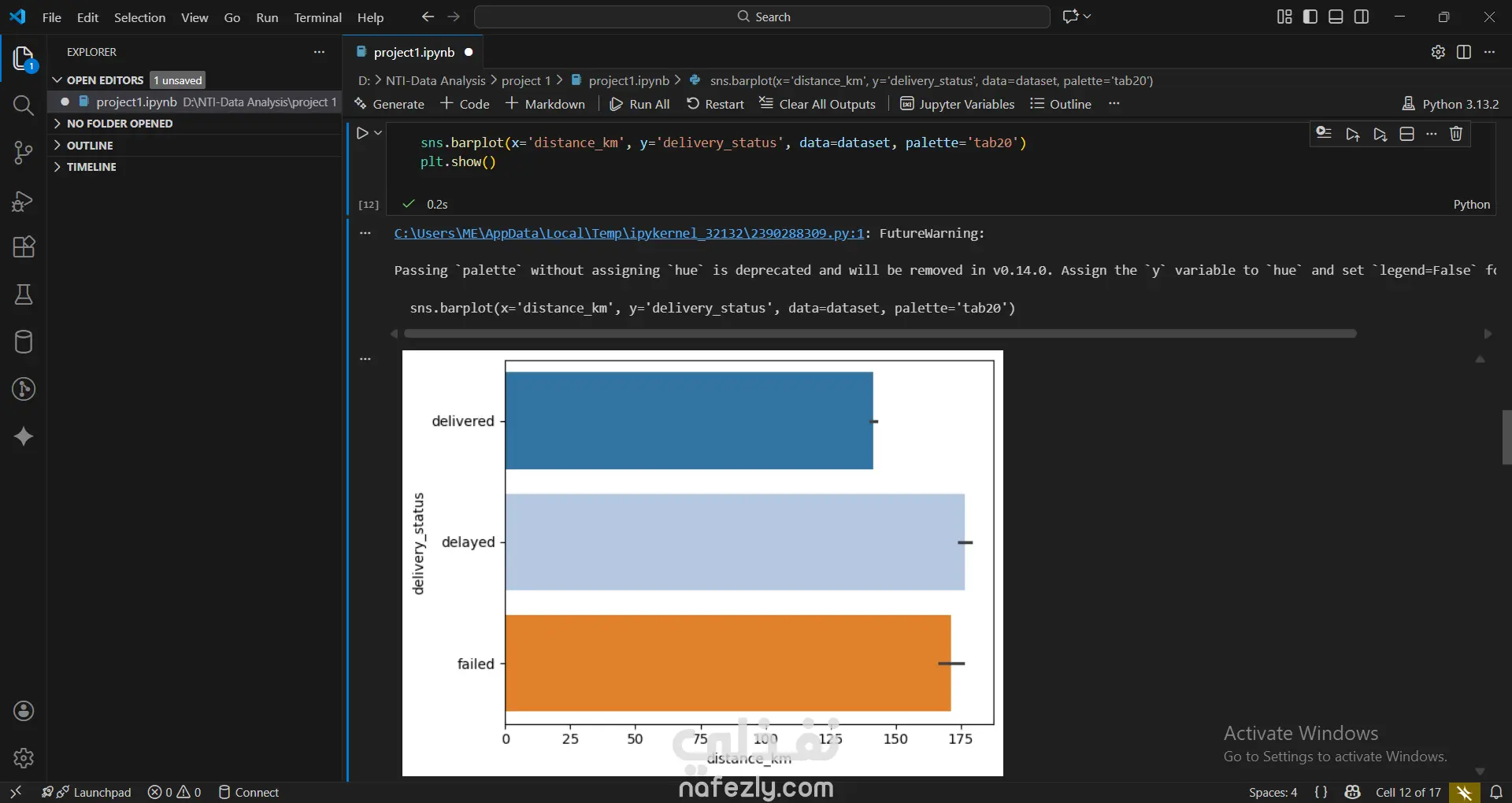
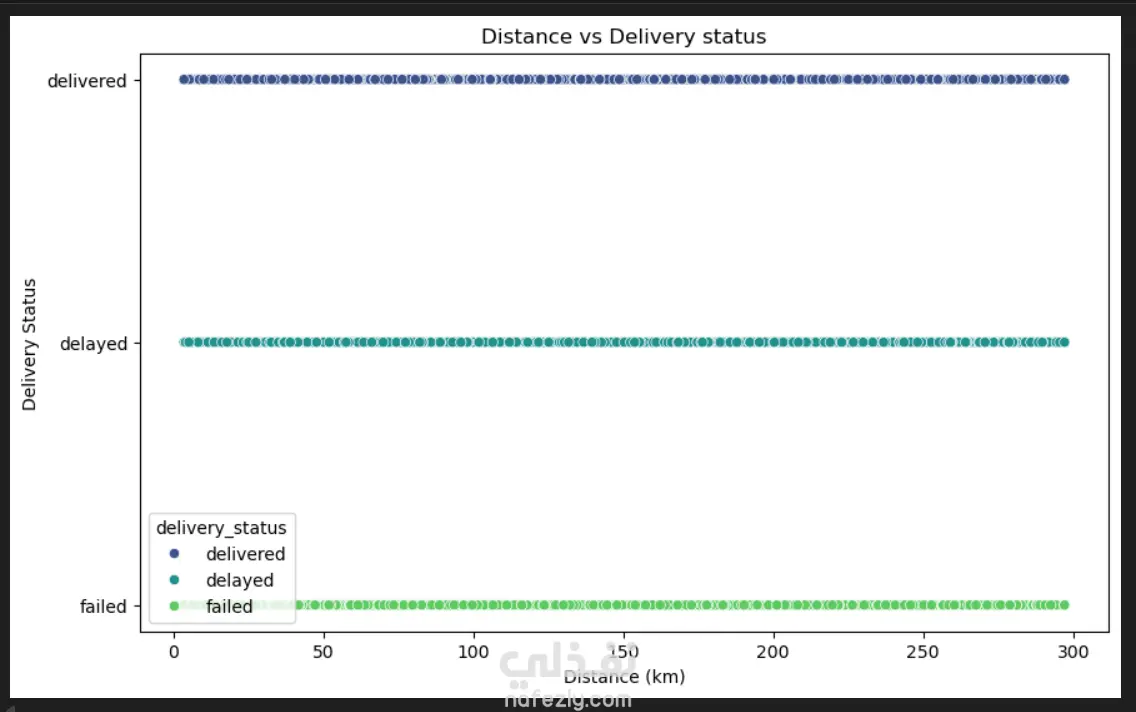
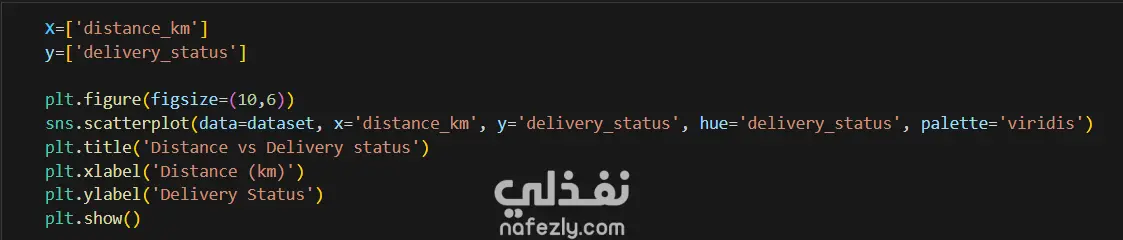
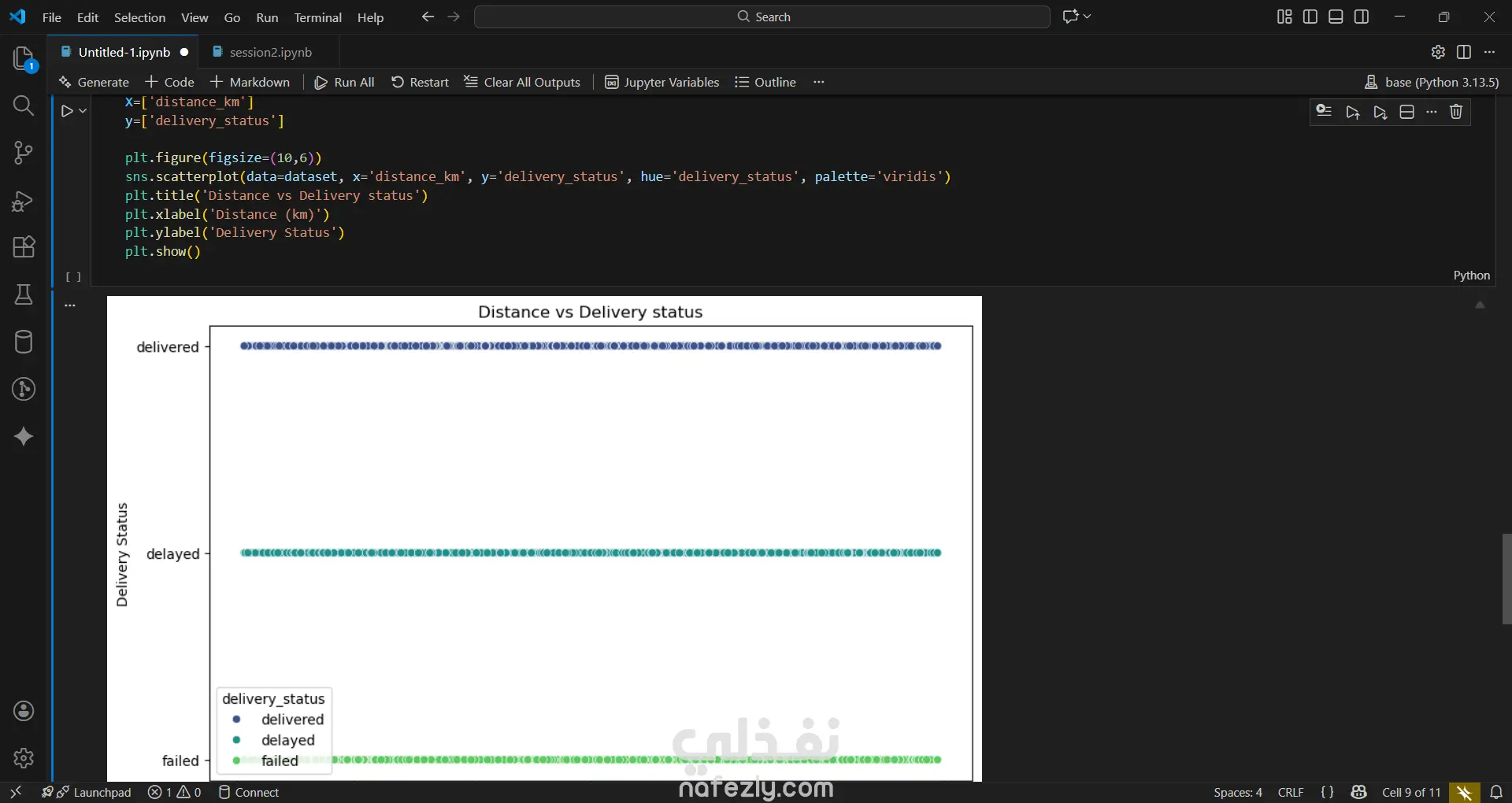
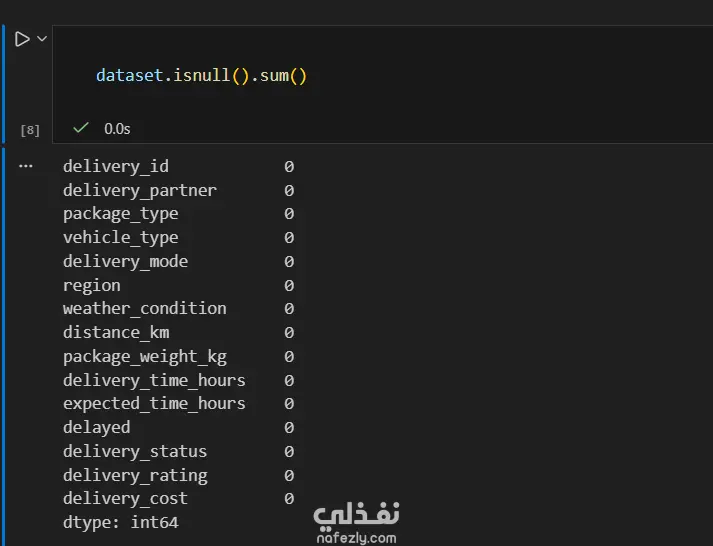
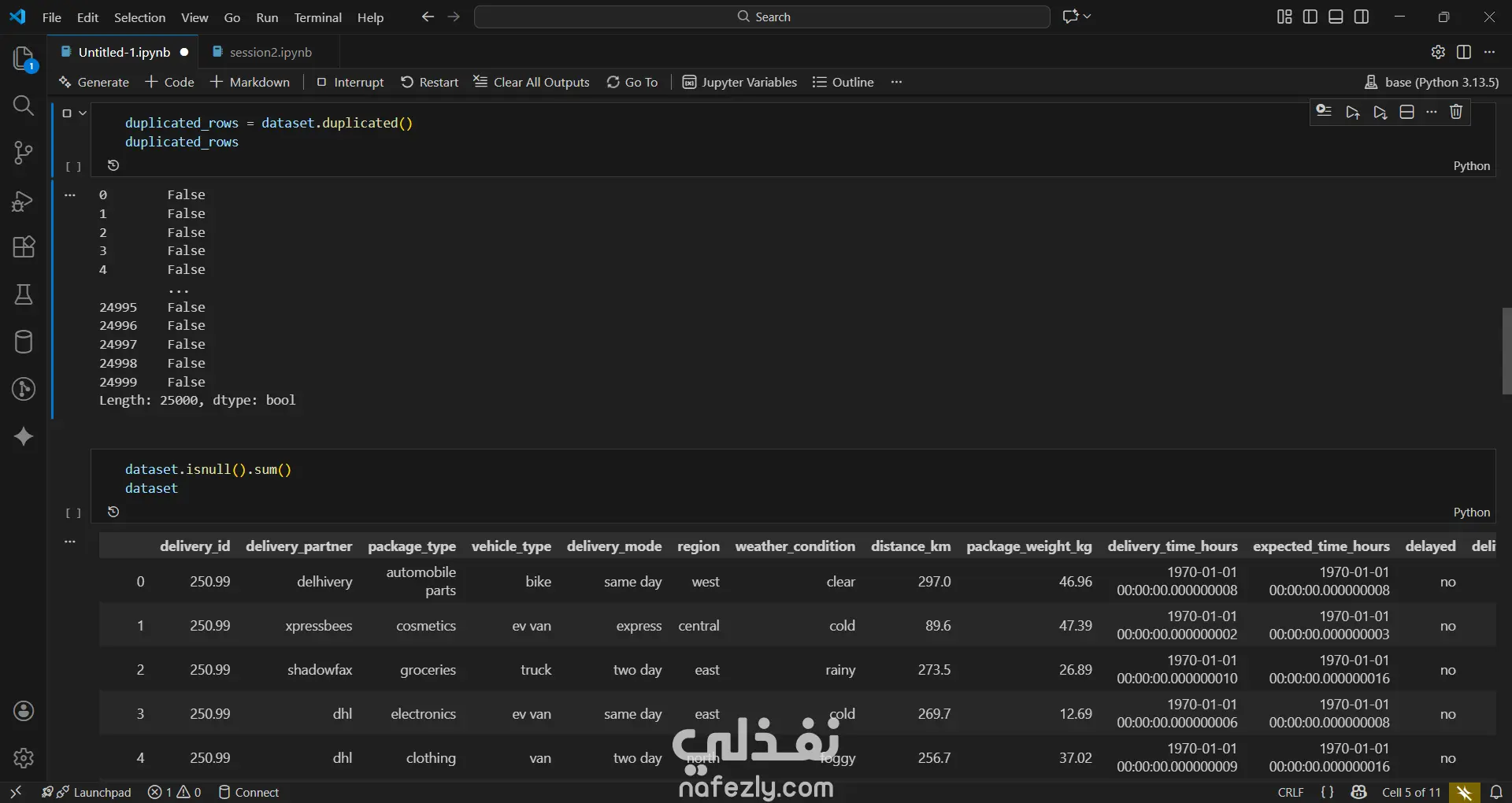
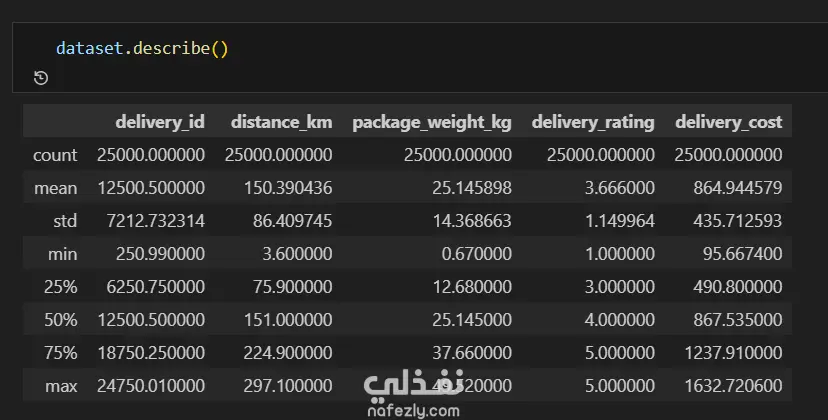
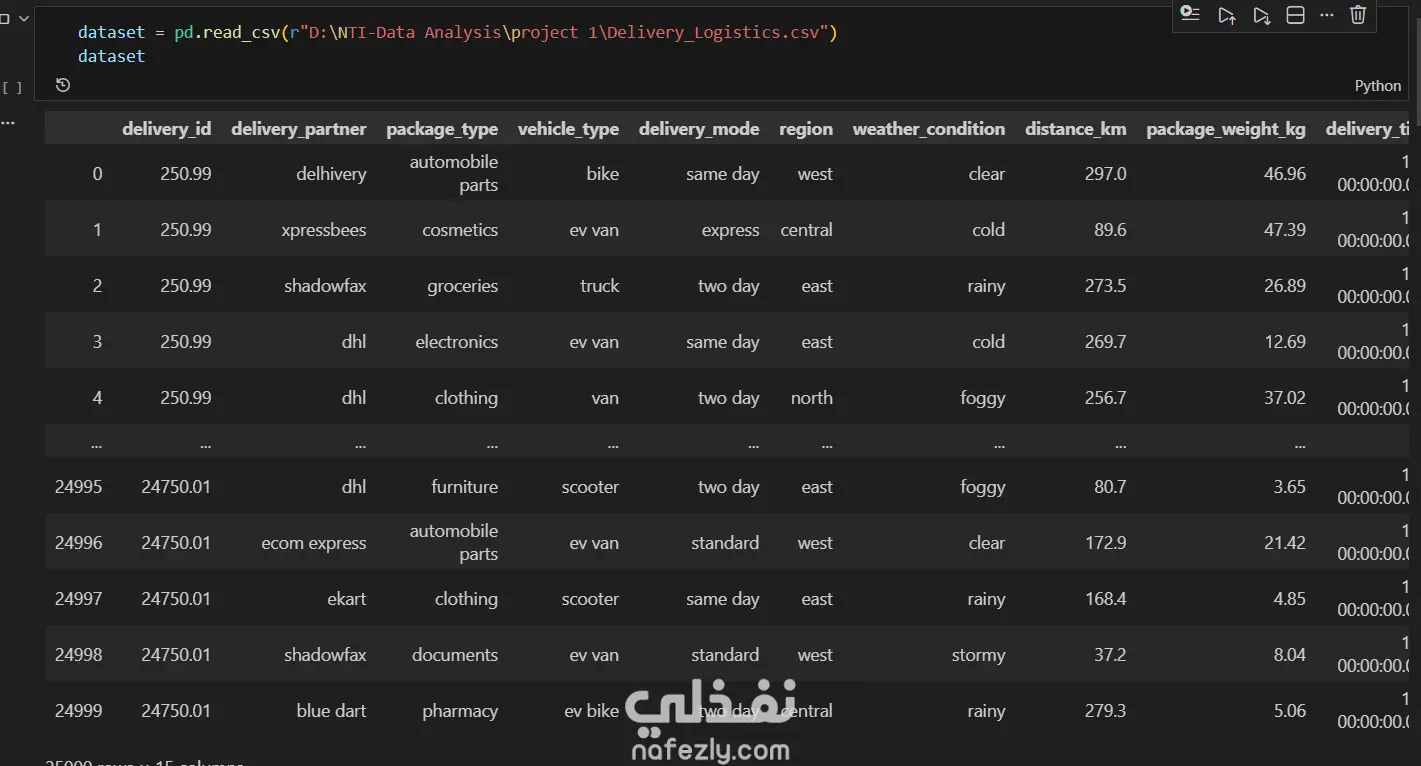
1. إعداد البيئة واستيراد البيانات المكتبات المستخدمة: تبدأ الصور باستيراد المكتبات الأساسية لتحليل البيانات وتصورها مثل pandas للمعالجة، وnumpy للعمليات الحسابية، وmatplotlib وseaborn للرسم البياني. تحميل الملف: يتم قراءة ملف بيانات من نوع CSV باسم Delivery_Logistics.csv يحتوي على 25,000 صف و15 عموداً. 2. استكشاف البيانات (Exploratory Data Analysis) نظرة عامة: تظهر البيانات معلومات حول رقم الشحنة، شريك التوصيل، نوع المركبة، المسافة بالكيلومتر، الوزن، وحالة التوصيل. الإحصاء الوصفي: تم استخدام أمر dataset.describe() لإظهار القيم الإحصائية (المتوسط، الانحراف المعياري، القيم الصغرى والعظمى) للأعمدة الرقمية مثل المسافة والوزن وتكلفة التوصيل. تنظيف البيانات: تم التحقق من وجود صفوف مكررة باستخدام duplicated()، والتأكد من عدم وجود قيم فارغة (Null values) في كافة الأعمدة لضمان جودة البيانات. 3. التصور البياني (Data Visualization) تم إنشاء رسوم بيانية من نوع Scatter Plot (مخطط تشتت) لدراسة العلاقة بين المسافة بالكيلومتر وحالة التوصيل (ناجح، متأخر، فاشل). يظهر من الرسم توزيع نقاط البيانات بشكل خطي أفقي يمثل الحالات الثلاث المختلفة عبر مختلف المسافات. 4. النمذجة والتنبؤ (Machine Learning) بناء النموذج: تم استخدام مكتبة sklearn لاستيراد نموذج الارتباط الخطي (Linear Regression). دالة النتائج: تم كتابة دالة برمجة باسم plot_results تهدف إلى رسم البيانات الحقيقية كنقاط حمراء، ومقارنتها بخط التوقع الخاص بالنموذج باللون الأزرق.
مهارات العمل













