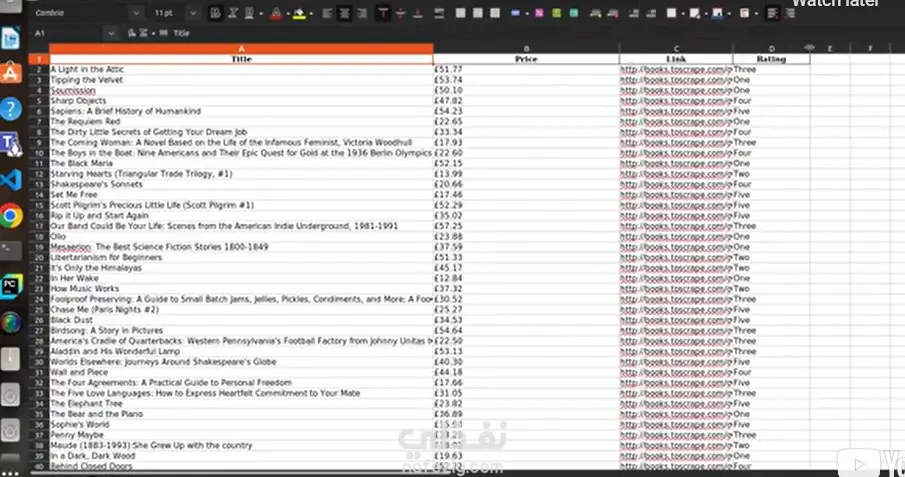
شروع Web Scraping احترافي يقوم باستخراج بيانات الكتب من موقع books.toscrape.com باستخدام مكتبتَي Selenium وBeautifulSoup.
البيانات المستخرجة تشمل:
عنوان الكتاب
السعر
رابط التفاصيل
رابط الصورة
التقييم
يتم حفظ النتائج تلقائيًا في ملفين: CSV وExcel، مما يسهل تحليلها أو استخدامها في أي تطبيق آخر.
مميزات المشروع:
كود منظم وسهل التعديل
يدعم التشغيل بدون واجهة رسومية (headless)
قابل للتوسعة لإضافة صفحات أو حقول جديدة