في هذا المشروع قمت بتنفيذ نموذج Machine Learning للتصنيف (Classification) بهدف التنبؤ بالفئة الصحيحة لكل سجل بناءً على مجموعة من الخصائص (Features).
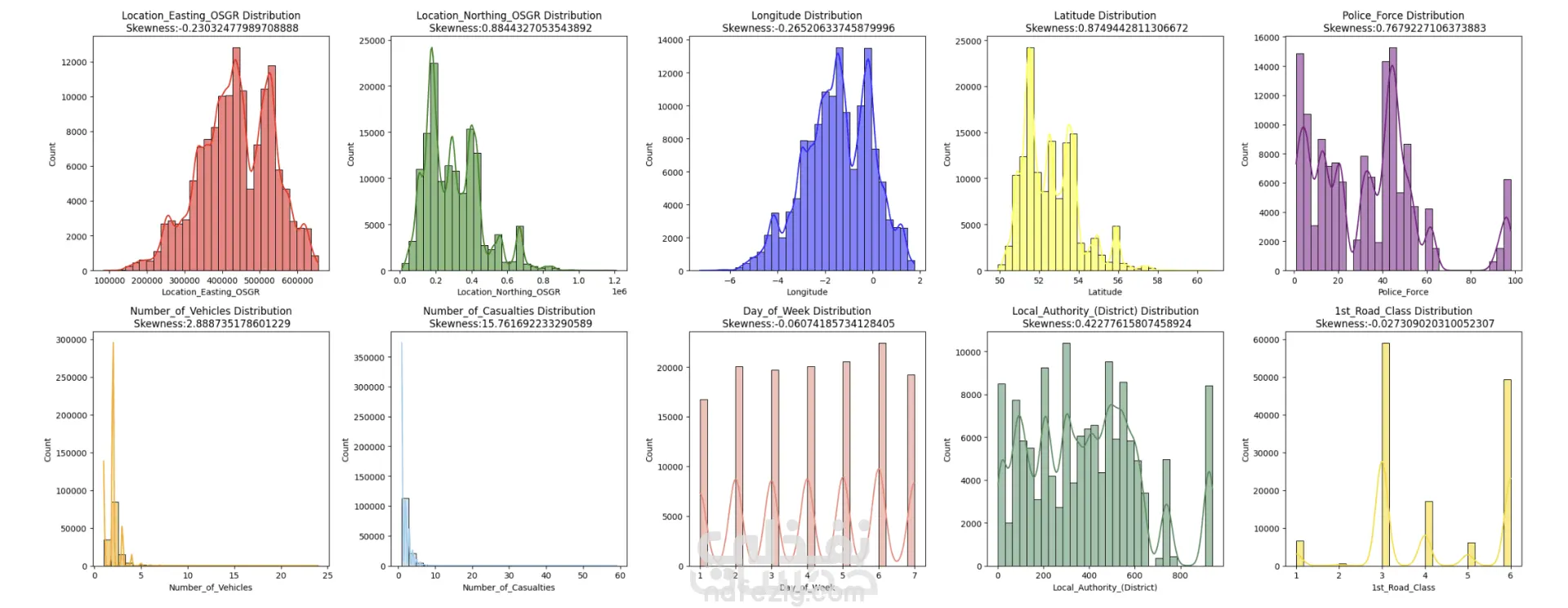
بدأ العمل بتحليل البيانات الاستكشافي (EDA) لفهم طبيعة البيانات واكتشاف القيم المفقودة وعدم توازن الفئات. بعد ذلك تم تنظيف البيانات ومعالجتها، واختيار الخصائص المناسبة لتحسين أداء النموذج.
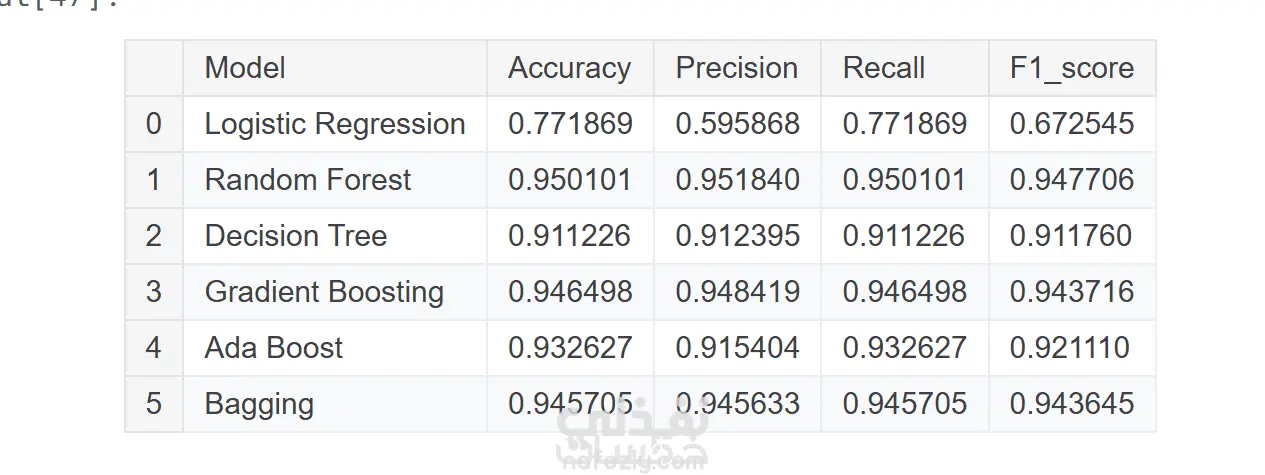
تم بناء وتجربة عدة نماذج تصنيف مثل:
Logistic Regression
Random Forest
Gradient Boosting
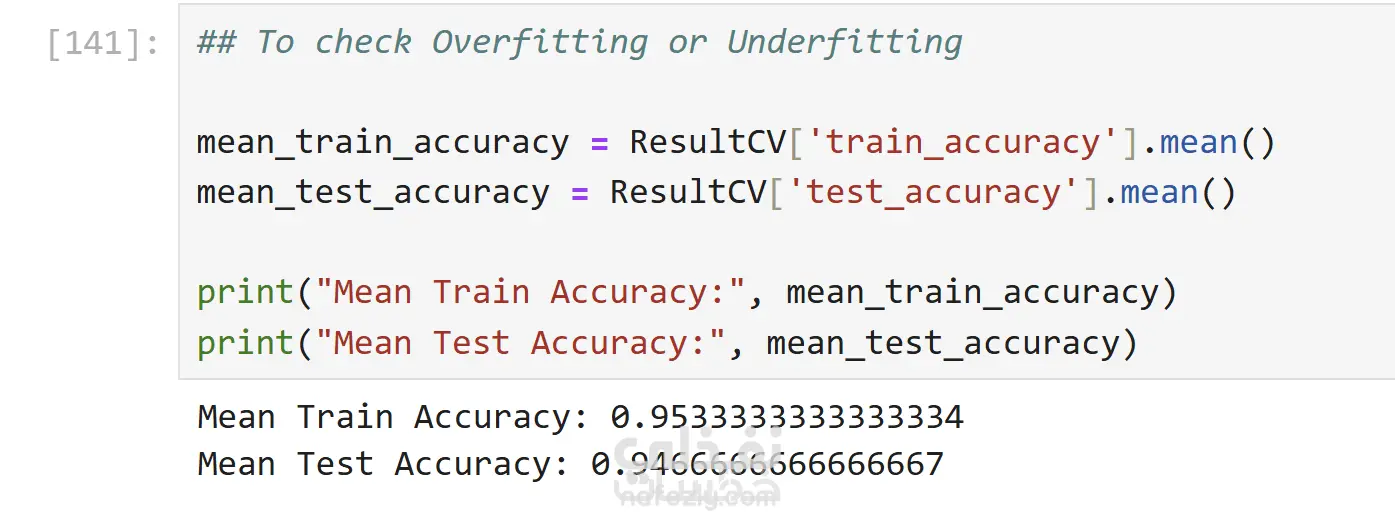
مع تطبيق Cross Validation و Hyperparameter Tuning للوصول إلى أفضل أداء ممكن دون حدوث Data Leakage.
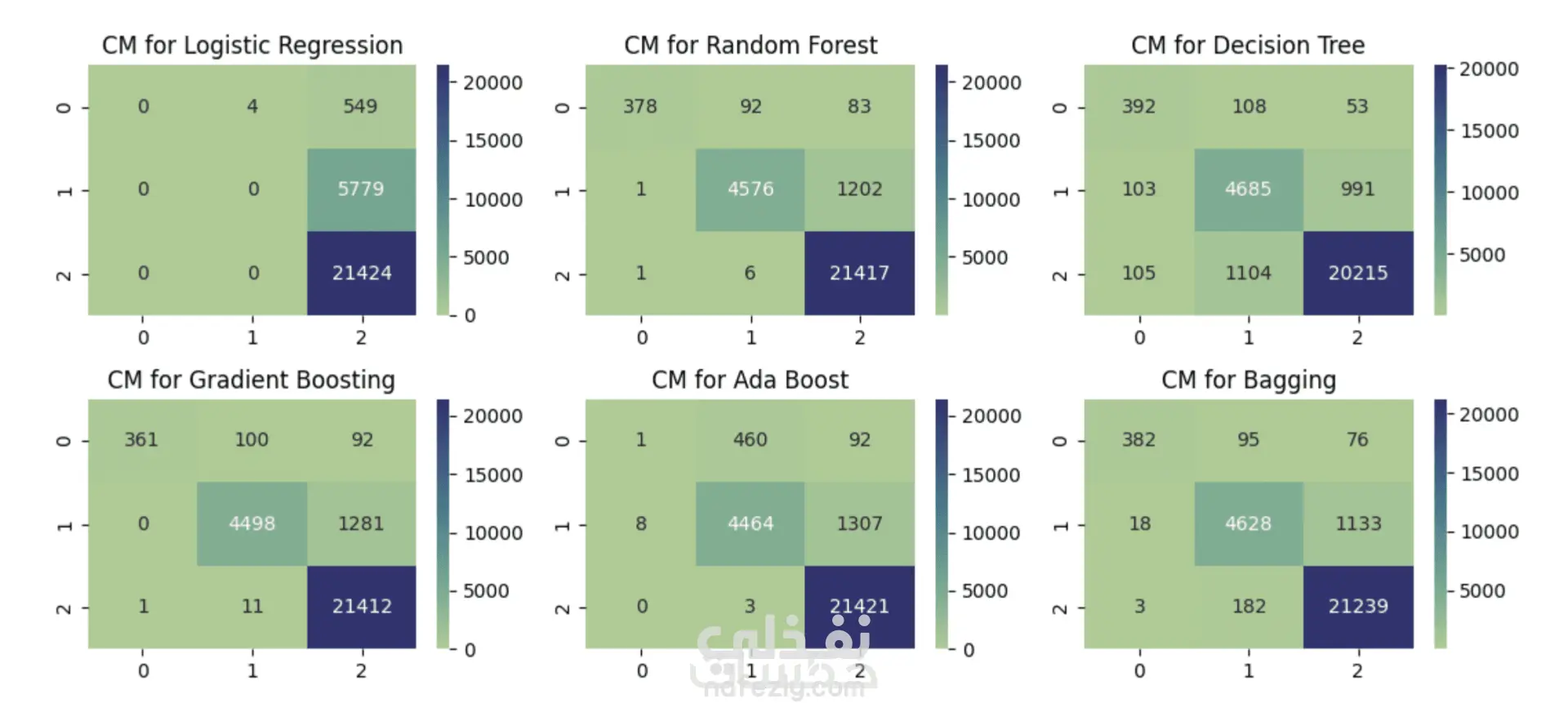
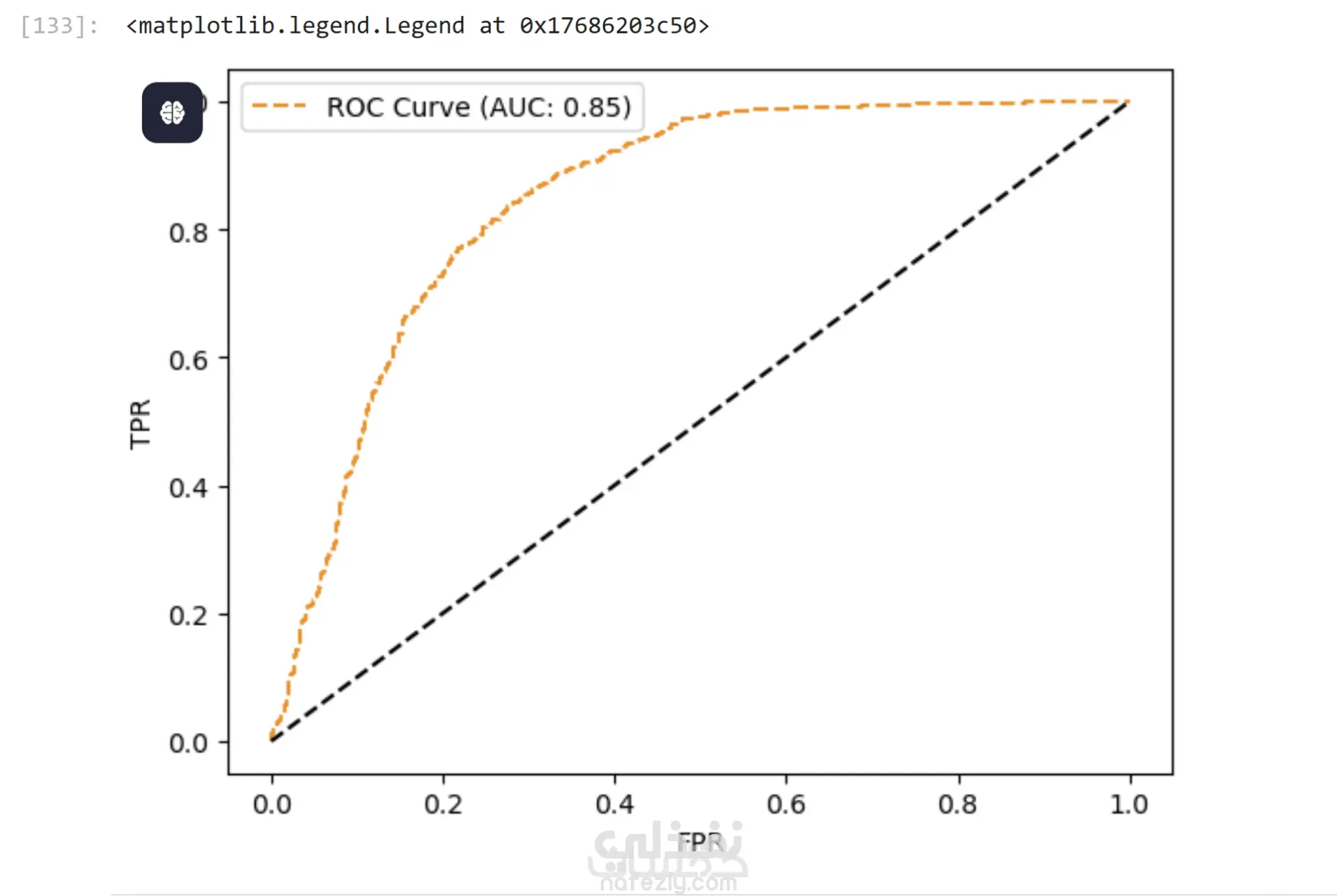
تم تقييم النموذج باستخدام مقاييس متعددة مثل:
Accuracy، Precision، Recall، F1-score و ROC-AUC
وتم اختيار النموذج النهائي بناءً على التوازن بين الدقة وقابلية التعميم.
النتيجة كانت نموذجًا مستقرًا وقابلًا للاستخدام في بيئة عمل حقيقية، مع كود منظم وقابل للتطوير.