Modern Data Stack Pipeline

تفاصيل العمل
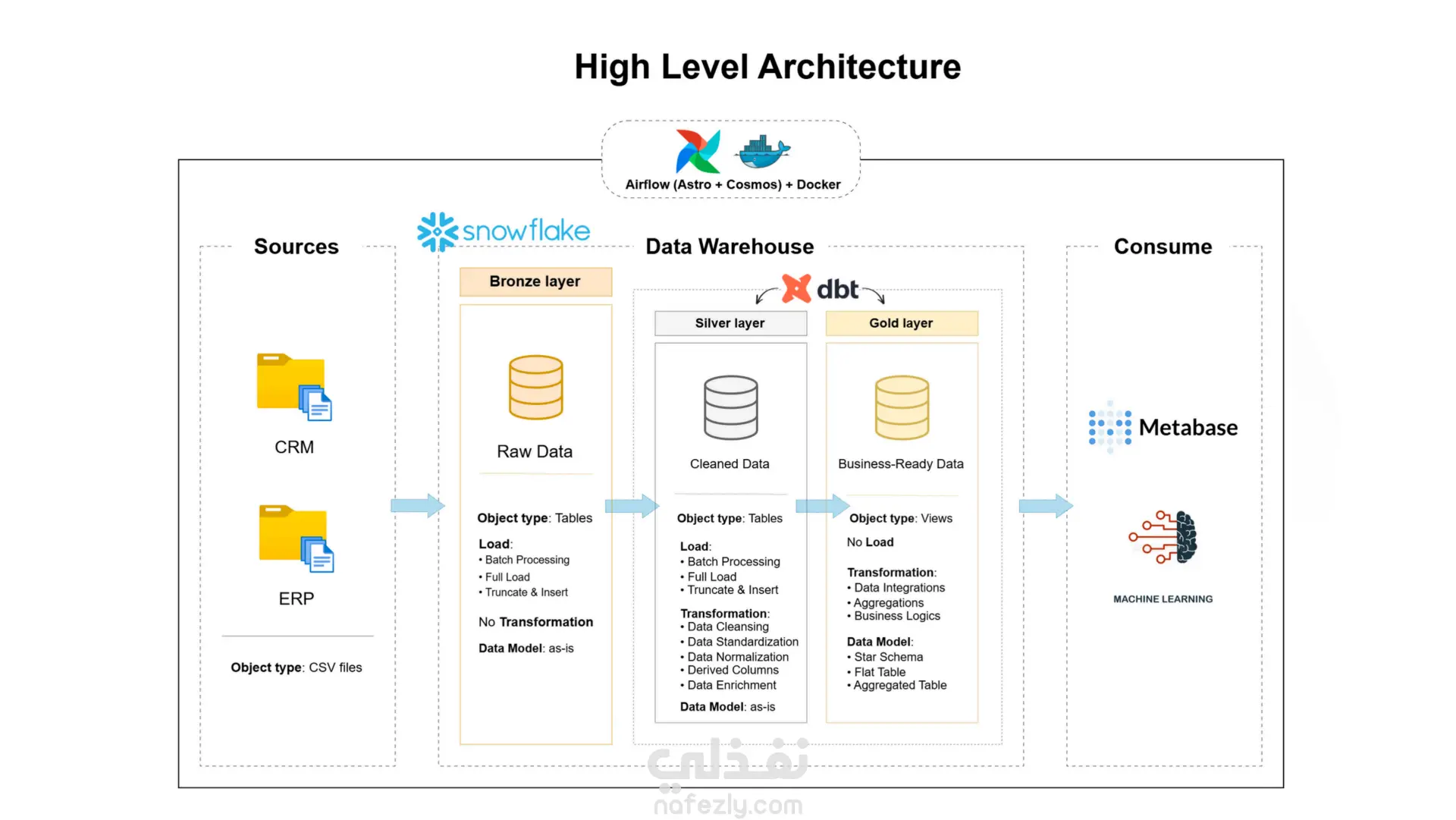
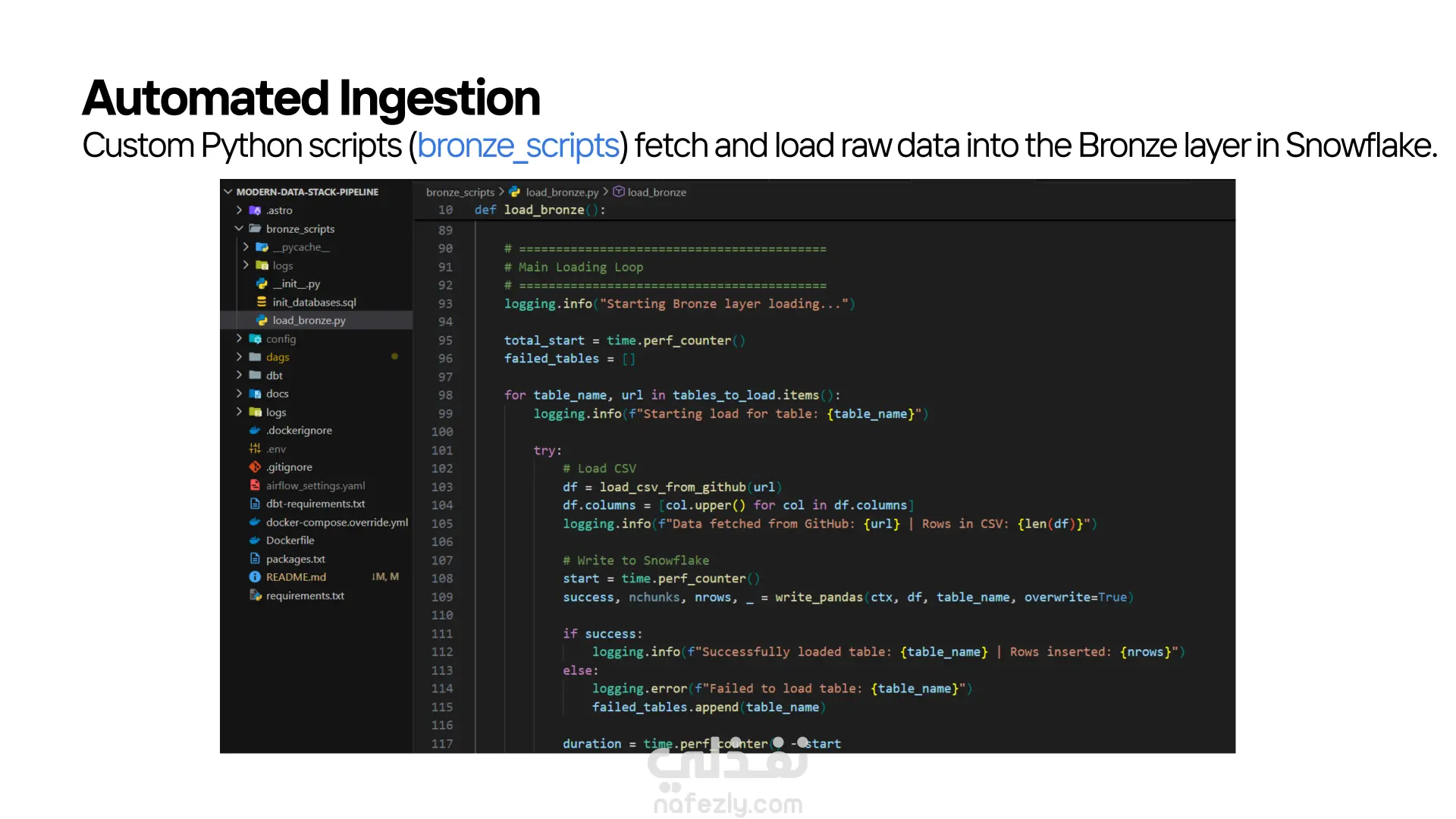
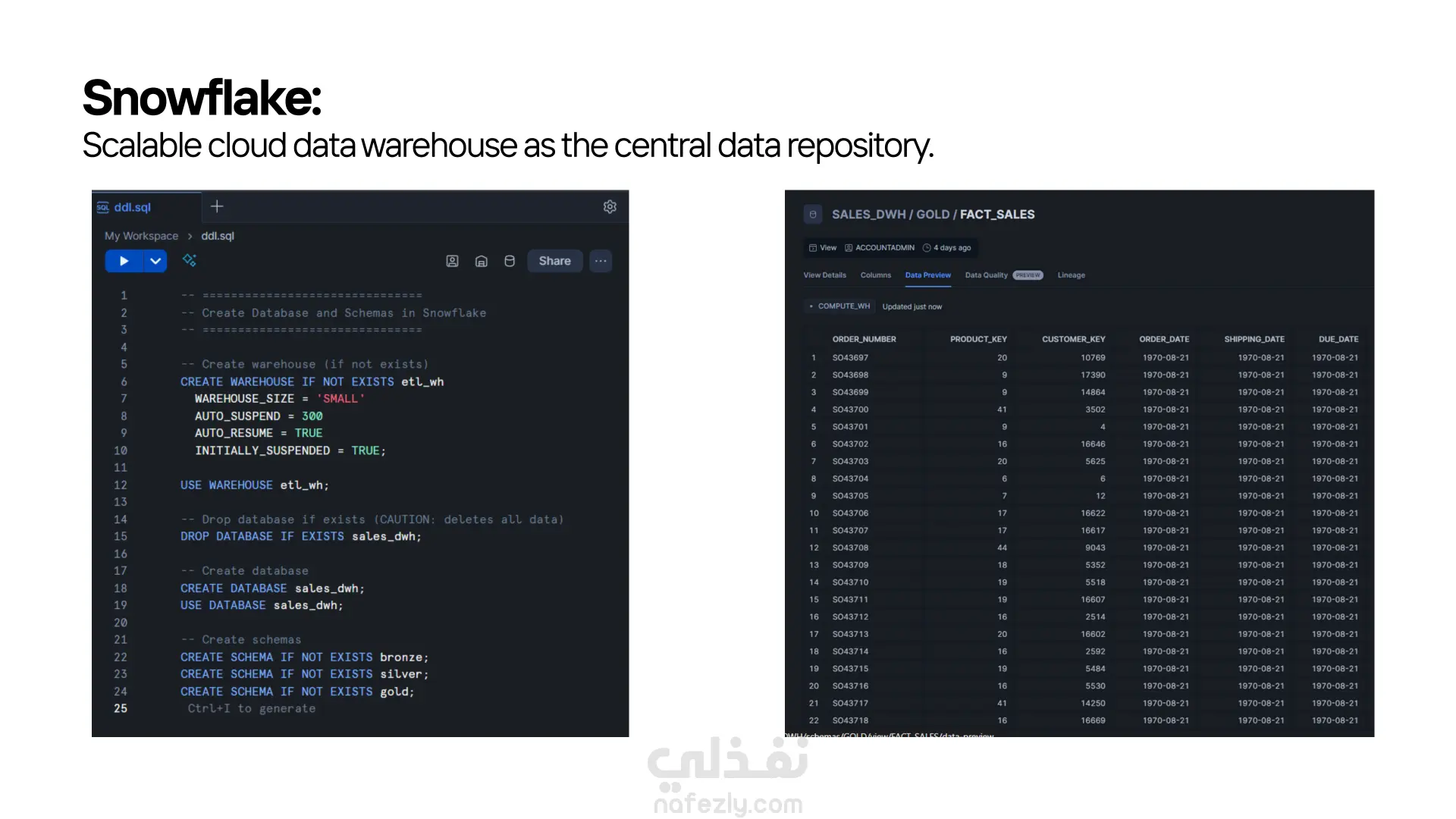
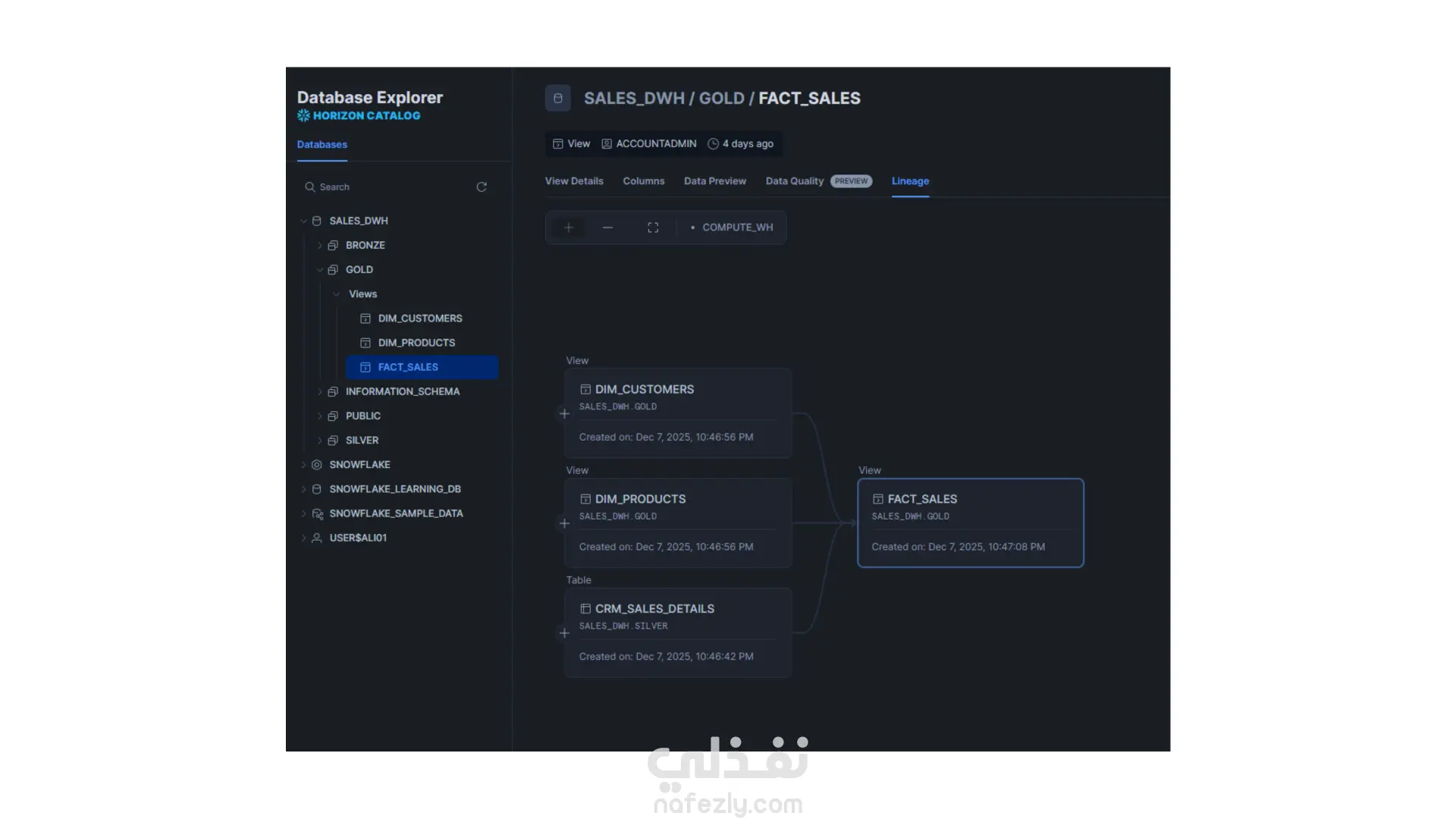
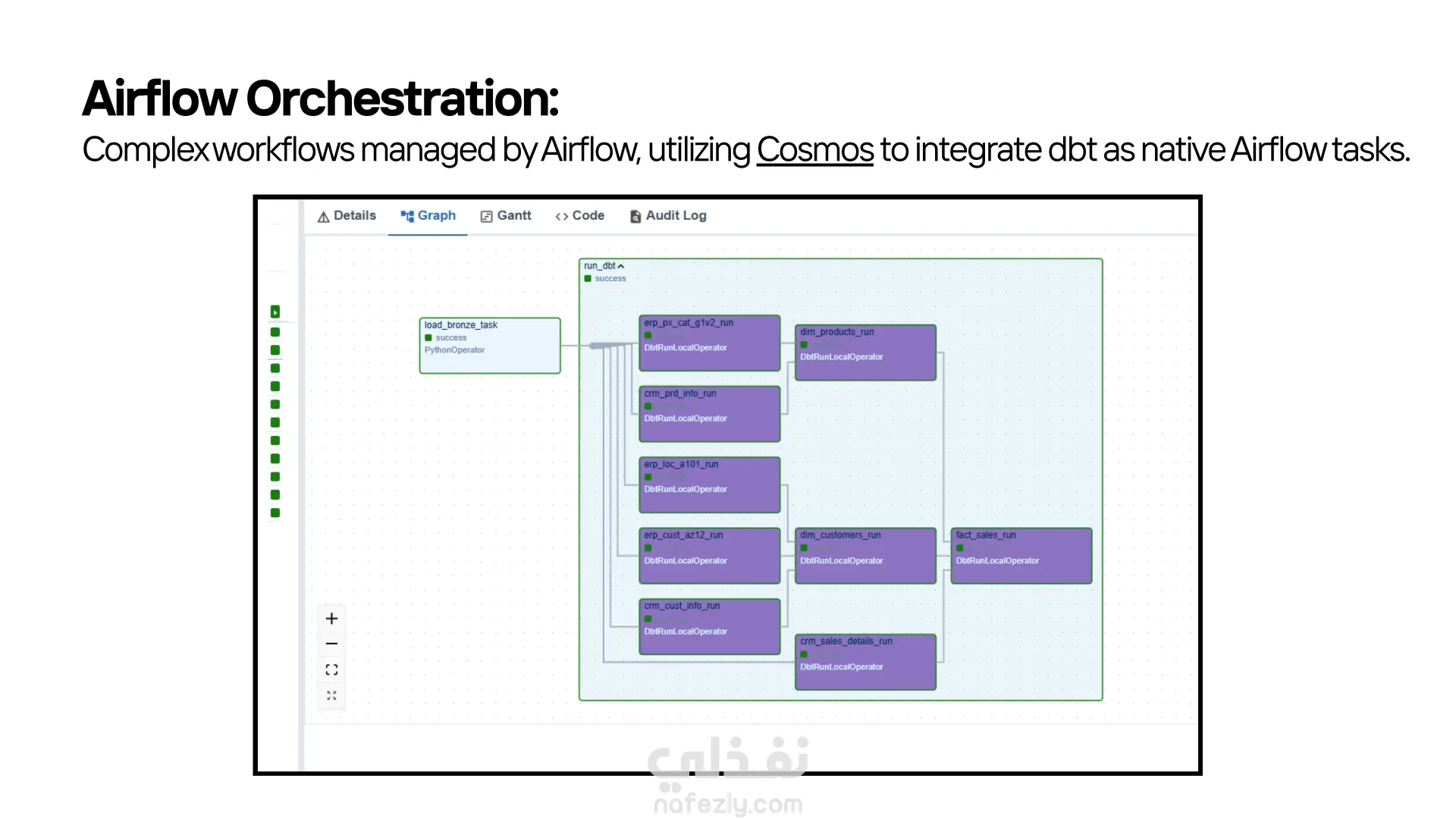
قمت بتنفيذ مشروع (Data Pipeline) متكامل يعتمد على أحدث أدوات الـ Modern Data Stack، بهدف استخراج البيانات الخام، تحميلها، تحويلها، وإدارة سير العمل بالكامل بشكل آلي. المشروع يجمع بين Python، Snowflake، dbt، Docker، وApache Airflow في منظومة واحدة متناسقة. ● استخراج البيانات – Python طوّرت سكريبتات Python داخل مجلد bronze_scripts تقوم بـ: جلب البيانات الخام من المصدر. تجهيزها أوليًا. تحميلها مباشرة إلى طبقة الـ Bronze في Snowflake. ● تحميل البيانات إلى Snowflake بعد الاستخراج، يتم تخزين البيانات داخل Snowflake ضمن طبقات منظّمة، مما يسمح بمعالجة أسرع وتنظيم أفضل للبيانات. ● تحويل البيانات – dbt Core اعتمدت على dbt Core لتنفيذ نماذج التحويل داخل Snowflake، من خلال ثلاث طبقات رئيسية: • Bronze: البيانات الخام كما هي. • Silver: بيانات منظّفة وموحّدة وجاهزة للاستخدام التحليلي. • Gold: مارت جاهزة للأعمال، يتم الاعتماد عليها في الـ dashboards والتحليلات النهائية. ● الأتمتة – Apache Airflow قمت بإعداد Airflow لتشغيل وإدارة جميع خطوات pipeline من خلال DAGs مخصّصة. كما استخدمت Cosmos لدمج dbt داخل Airflow وتشغيل الـ models كمهام طبيعية في الـ DAG. ● البيئة التشغيلية – Docker المشروع بالكامل يعمل داخل بيئة Docker لضمان: ثبات الإصدارات سهولة التشغيل على أي جهاز قابلية النقل والتنفيذ بدون مشاكل بيئية
مهارات العمل













