Ai_powerd drug discovery
تفاصيل العمل
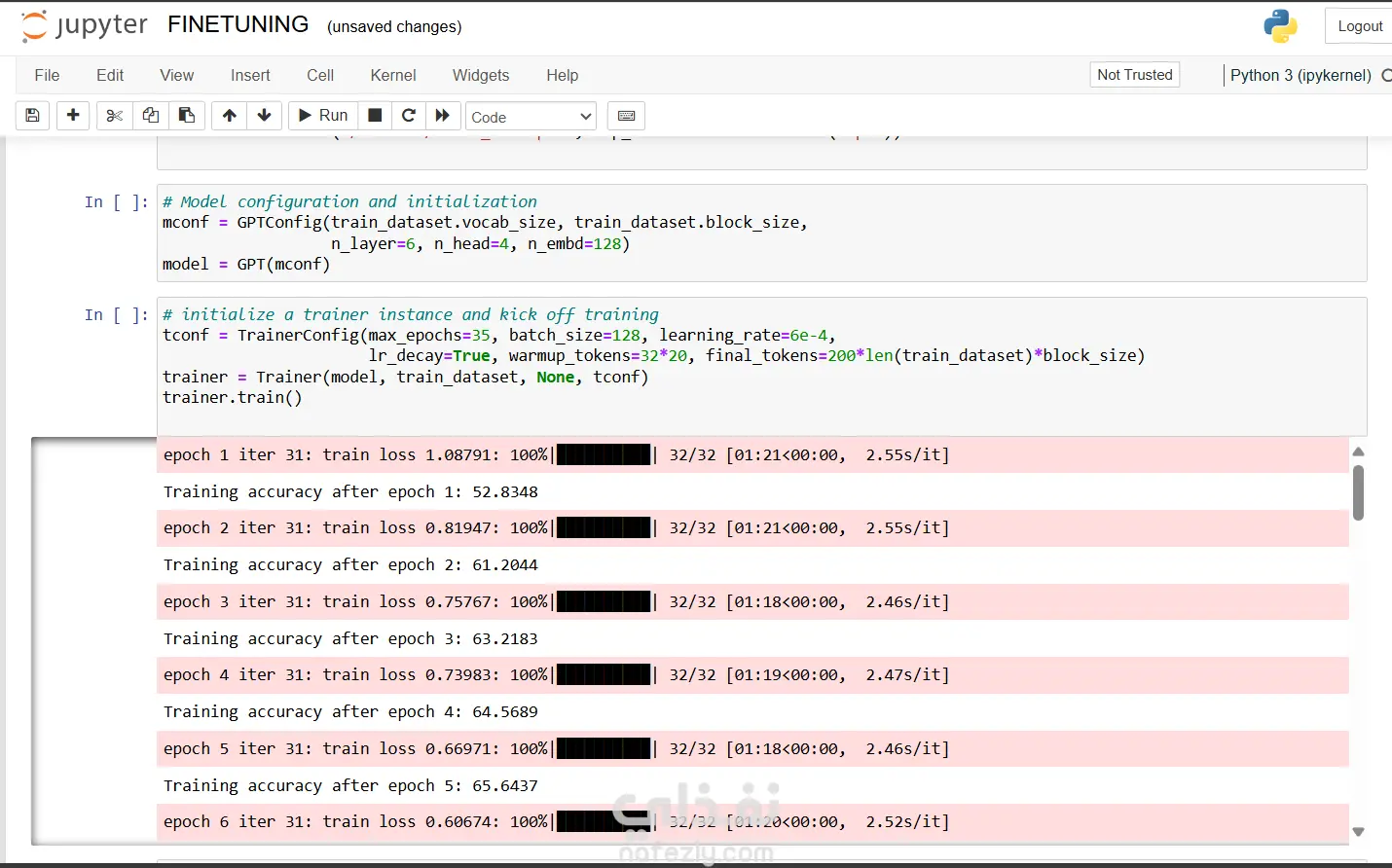
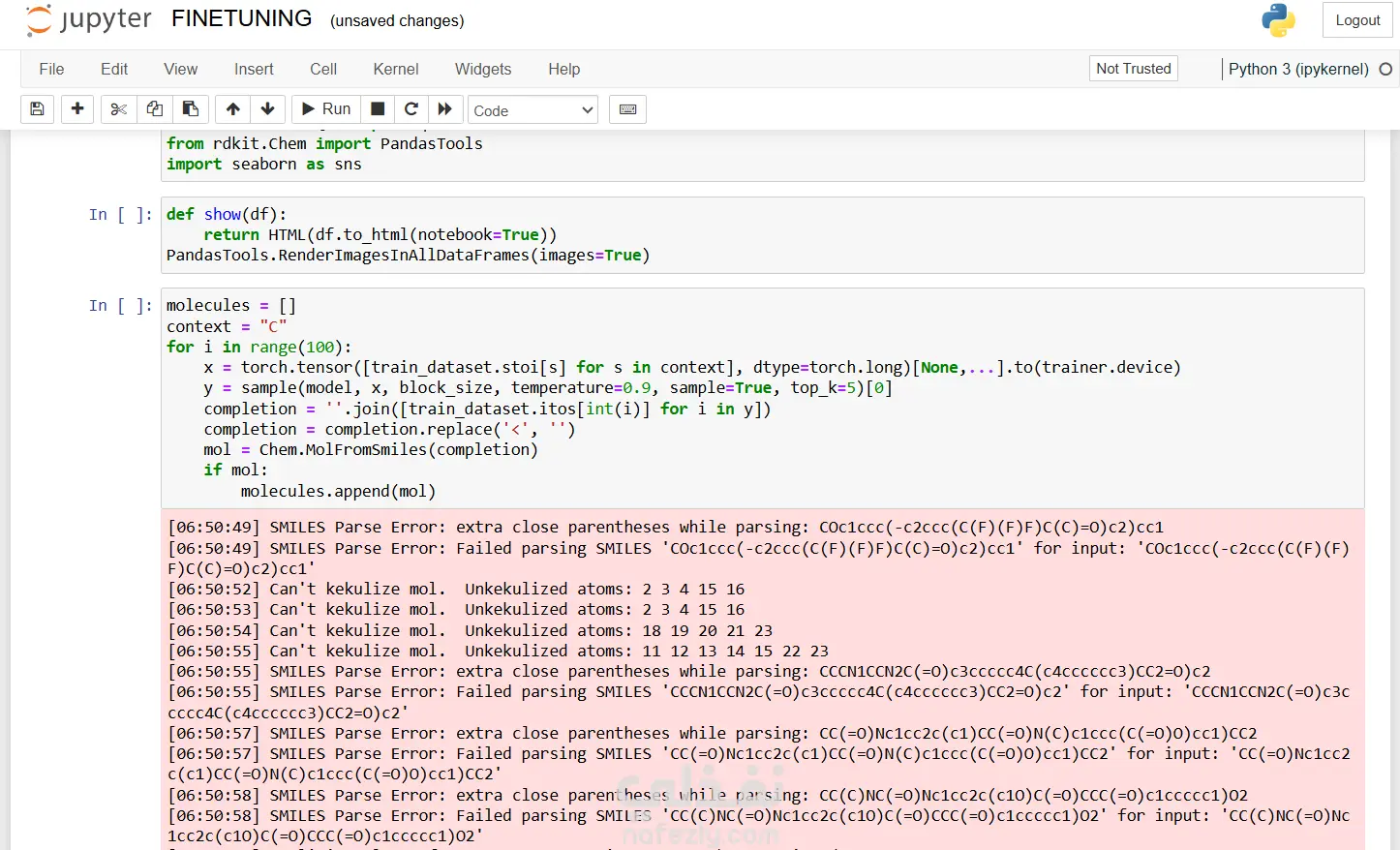
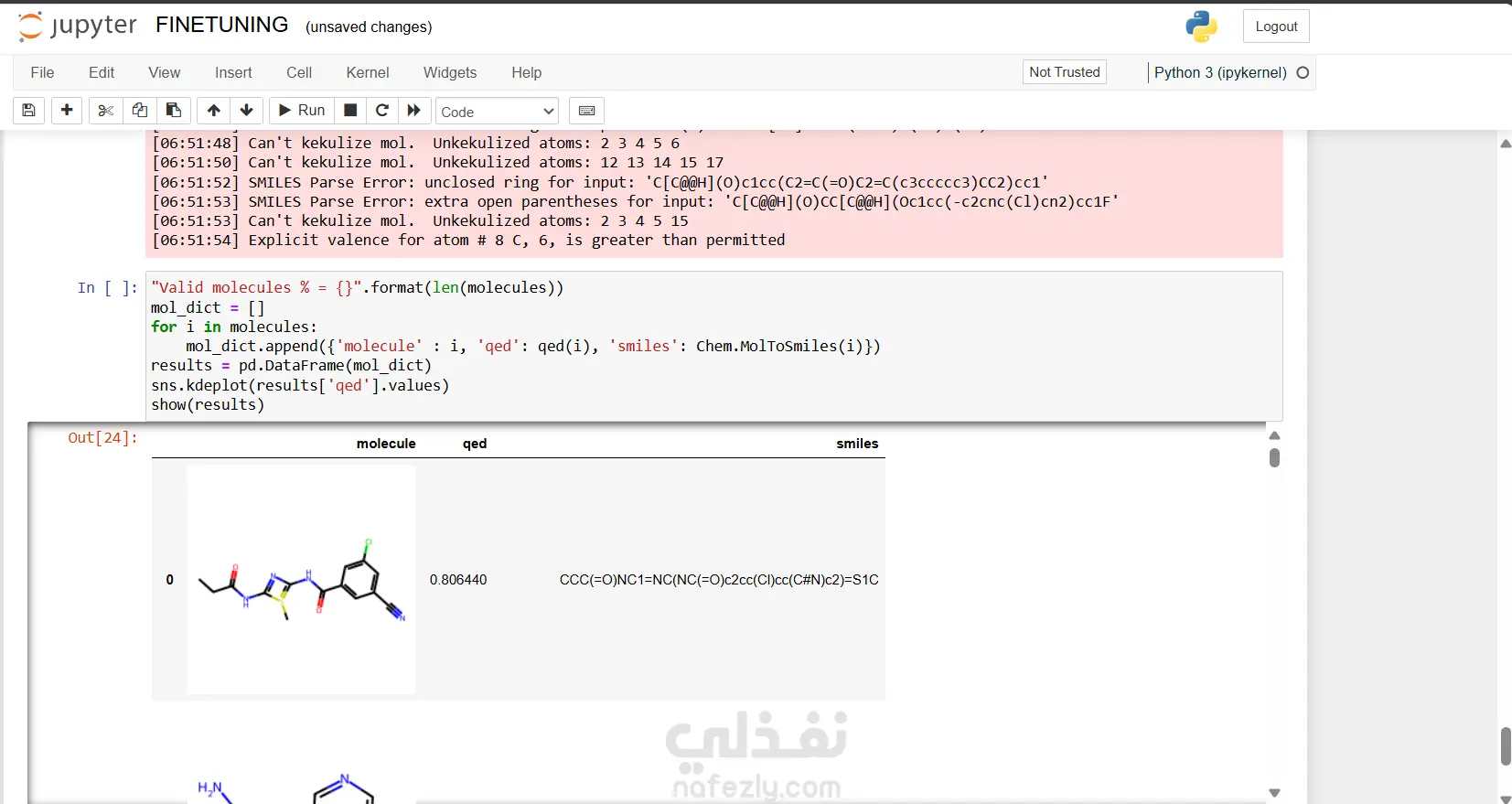
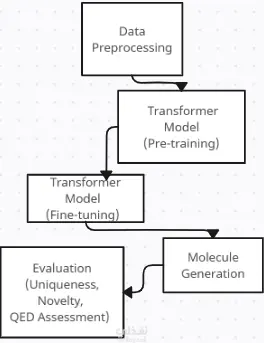
نظرة عامة على المشروع قمتُ بتطوير خط أنابيب لاكتشاف الأدوية، مُدعّم بالذكاء الاصطناعي، يُركّز على تحديد مُرشّحات مثبطة مُحتملة لهدف بيولوجي مُحدّد، باستخدام تقنيات مُتقدّمة في التعلّم العميق والمعلوماتية الكيميائية. يُدمج النظام مُعالجة البيانات المُسبقة، وتعلّم التمثيل الجزيئي، والنمذجة التنبؤية، وسير عمل التقييم، لتسريع المراحل المُبكرة لاكتشاف الأدوية. مسؤولياتي: أنشأتُ سير عمل ذكاء اصطناعي مُتكامل لاكتشاف الأدوية، بما في ذلك جمع البيانات، وتنظيفها، ومعالجتها المُسبقة، وهندسة خصائص البيانات الجزيئية. طبقت تقنيات تمثيل جزيئي مثل ترميز SMILES، والبصمات الجزيئية، والتمثيلات البيانية. طورت نماذج تنبؤية باستخدام بنى قائمة على Transformer لفحص وتصنيف مُرشّحات المثبّطات المُحتملة. أجريت فحصًا افتراضيًا، وولّدتُ جزيئات مُرشّحة باستخدام نماذج توليدية مُتعمقة. دمجت RDKit للتحقق الجزيئي، وتسجيل التشابه، وحساب الحداثة، وتحليل الفضاء الكيميائي. أجريتُ تقييمًا للنماذج باستخدام مقاييس مثل ROC-AUC، واستدعاء الدقة، والتحقق القائم على التشابه. تم تنفيذ خطوط أنابيب متعددة المعالجة لتسريع معالجة SMILES وتسجيل الجزيئات. عرض النتائج بشكل مرئي، بما في ذلك التشابه الجزيئي، وتحليل التوزيع، ومقاييس الأداء. تم توثيق سير عمل البحث بالكامل، بما في ذلك المنهجية، ومجموعات البيانات، وتصميم النموذج، والنتائج. الأدوات والتقنيات: Python، وPyTorch، وTensorFlow، وScikit-learn RDKit لمعلوماتية الكيمياء المحولات ونماذج التعلم العميق Pandas، وNumPy، وMatplotlib، وSeaborn معالجة SMILES والبصمة الجزيئية المعالجة المتعددة لتحسين الحوسبة بيئة Jupyter Notebook / Kaggle نتيجة المشروع: تم بنجاح تحديد مجموعة من المثبطات المحتملة المرشحة للبروتين المستهدف. حقق أداءً قويًا للنموذج، وتم التحقق من حداثة المرشح باستخدام مقاييس التشابه الكيميائي. تم إنشاء خط أنابيب الذكاء الاصطناعي القابل للتكرار والتوسع والموثق جيدًا والذي يمكن تمديده لأهداف بيولوجية إضافية.
مهارات العمل
بطاقة العمل

طلب عمل مماثل













