End-to-End Diabetes Prediction Pipeline: Data Cleaning, Imputation, and Model Tuning for 100% Medical Recall


تفاصيل العمل
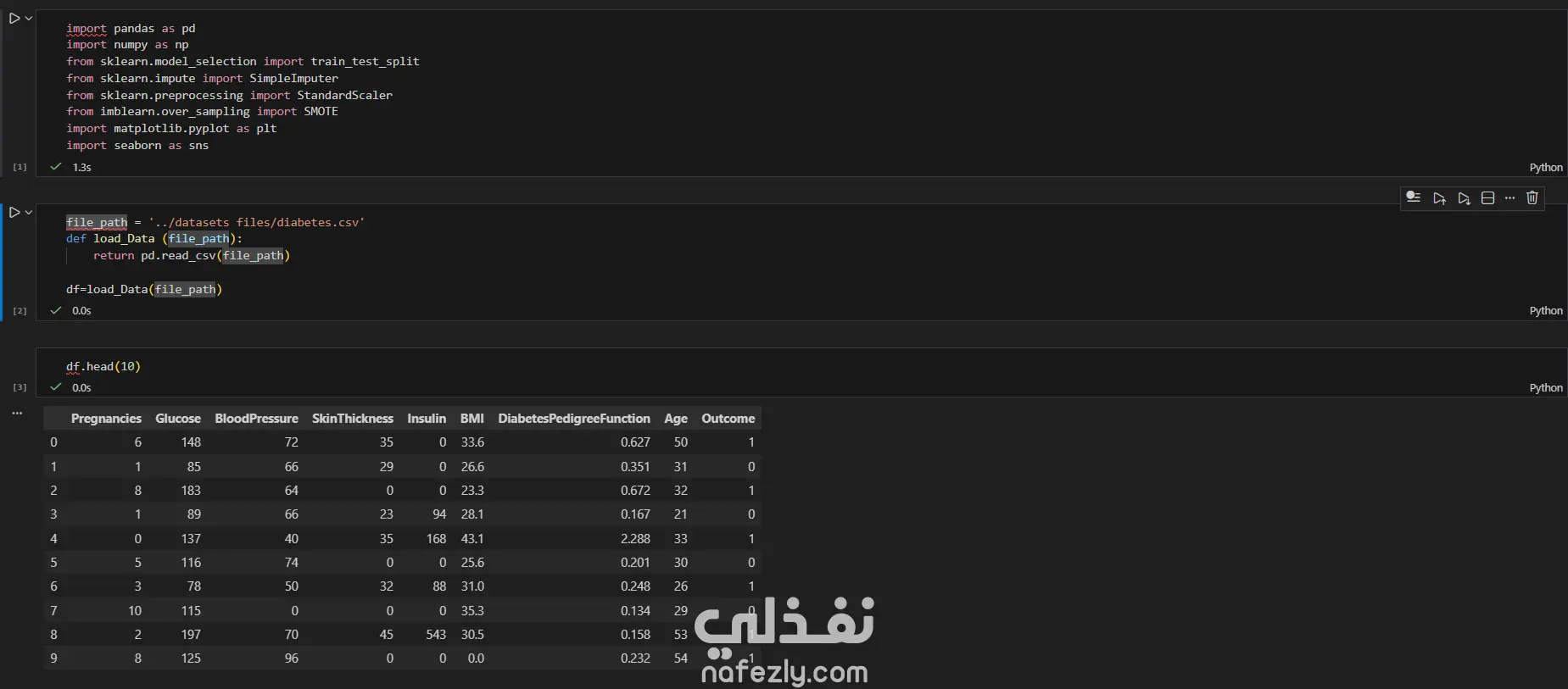
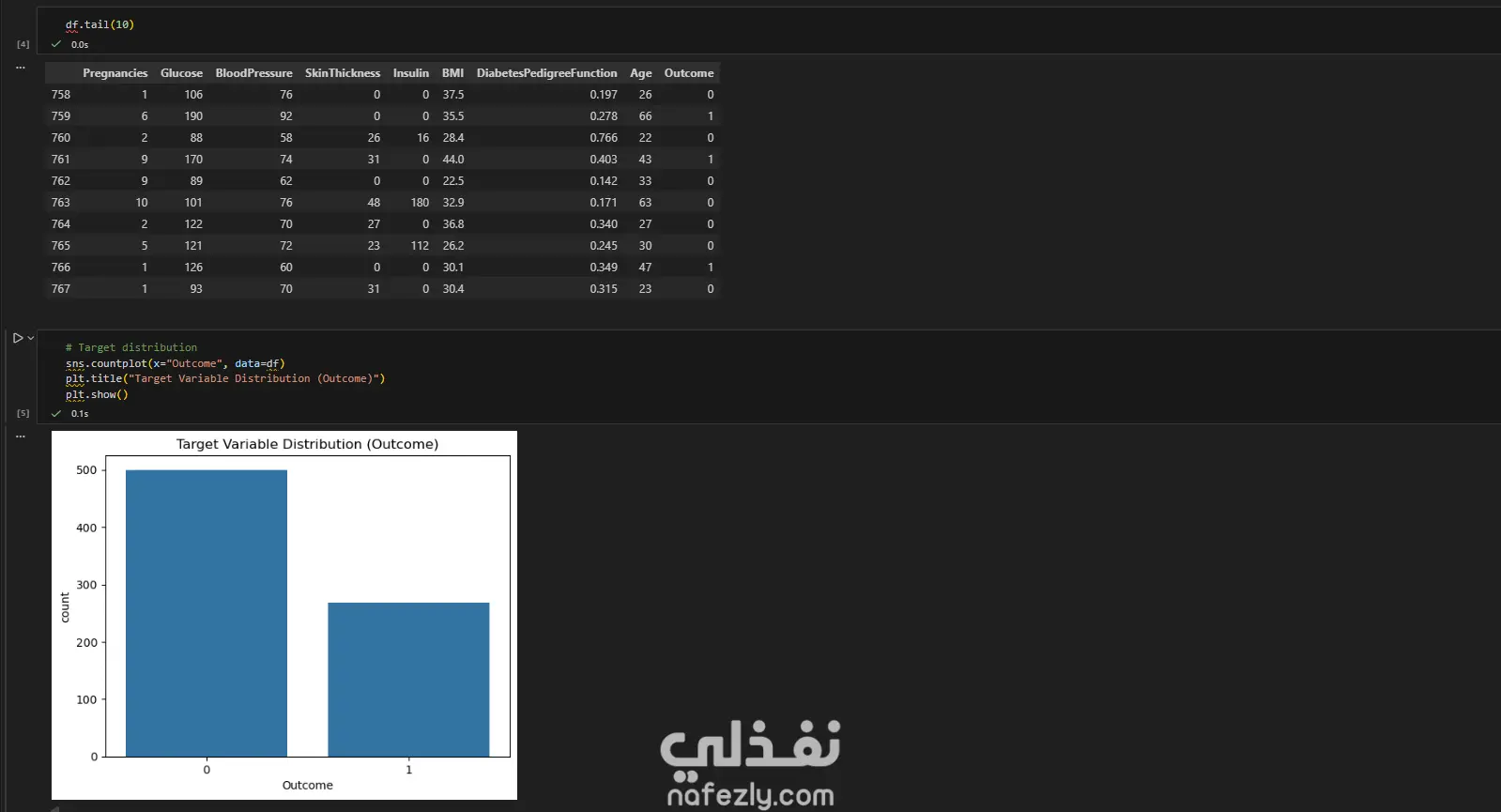
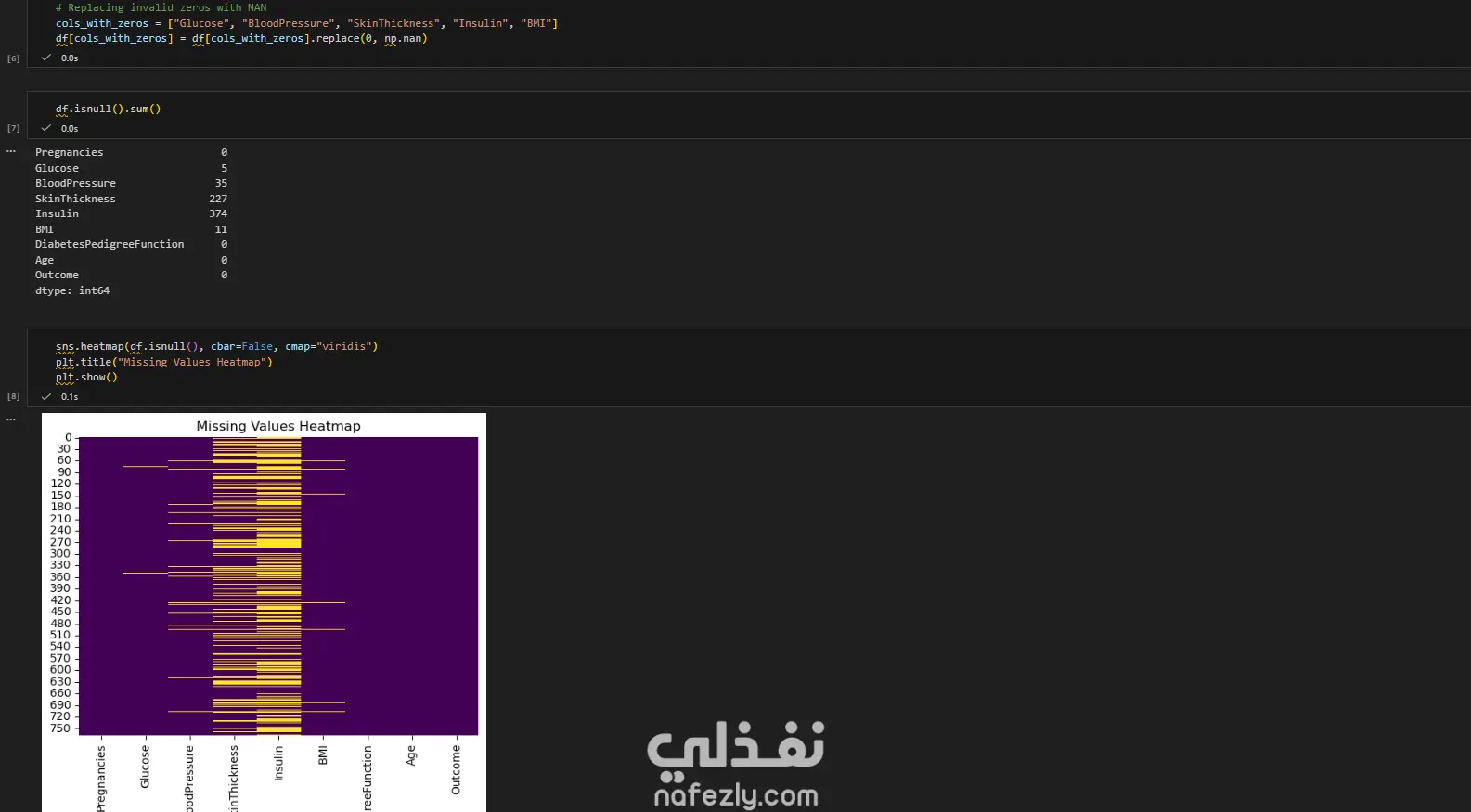
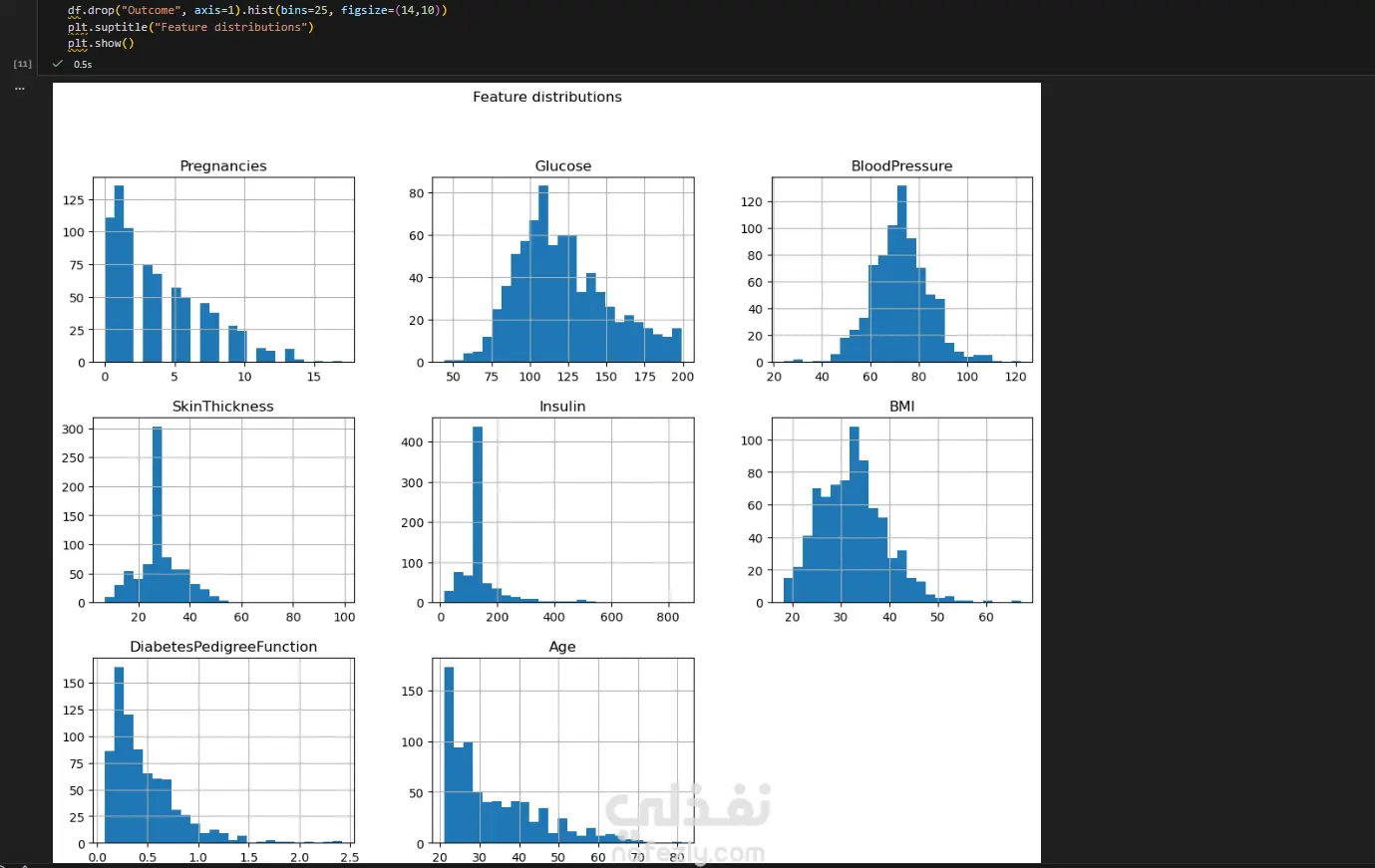
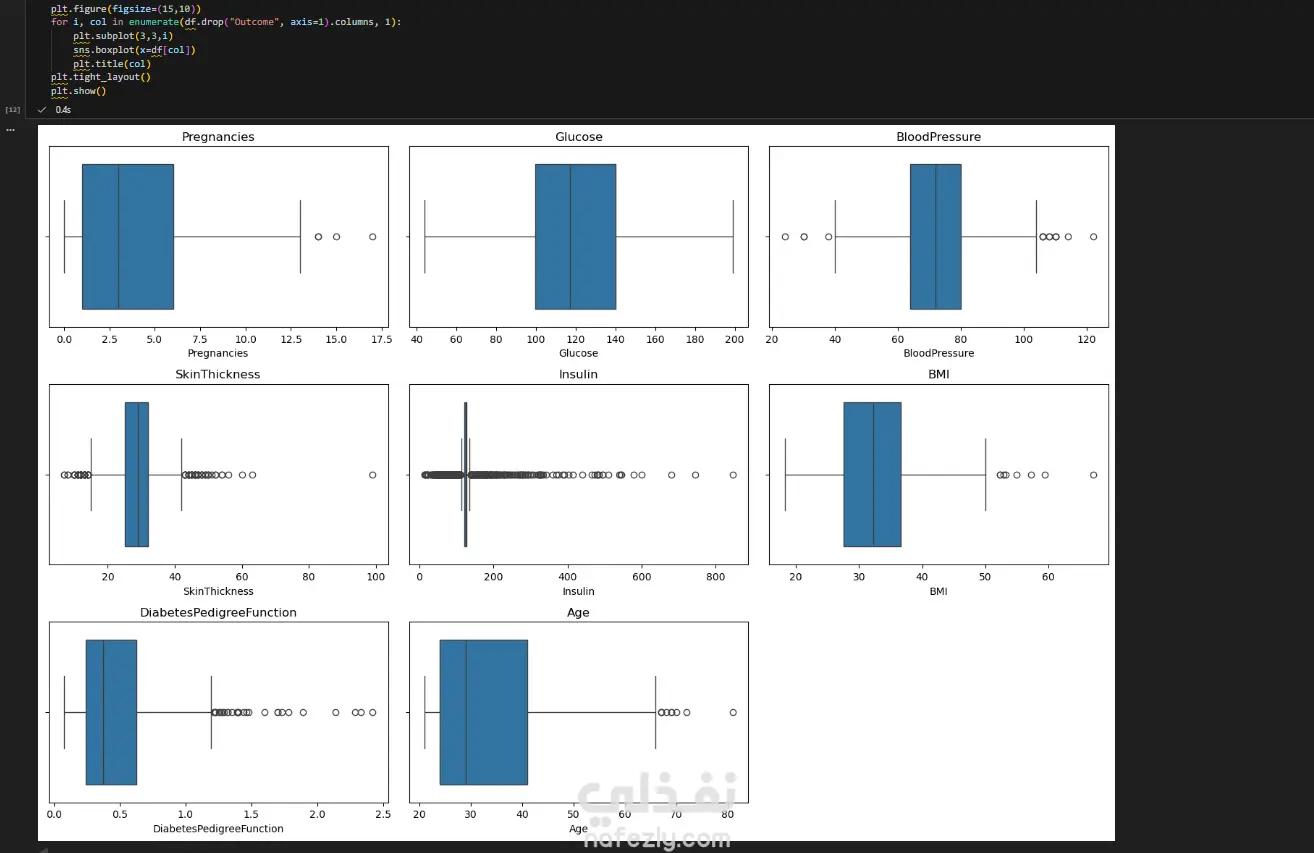
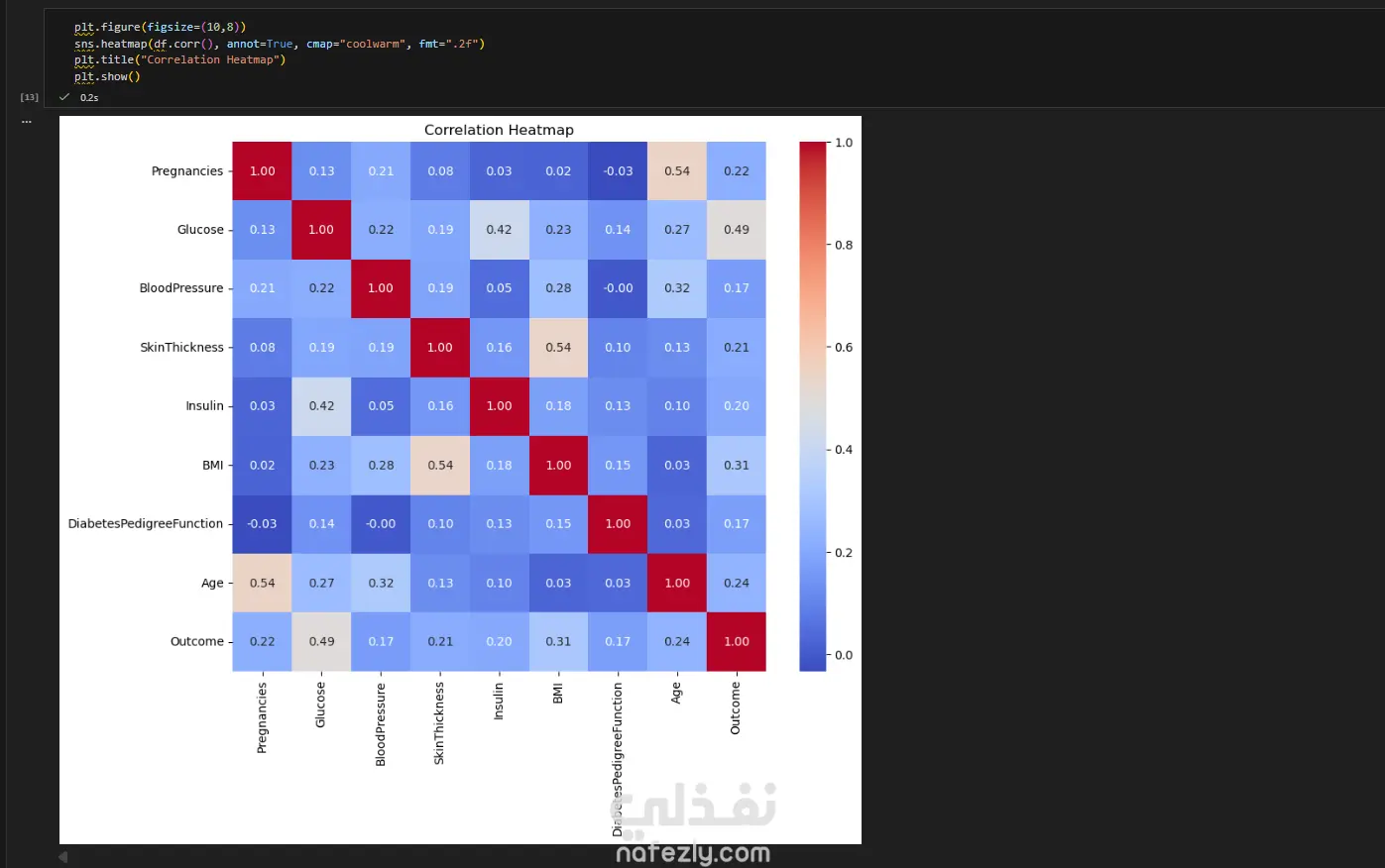
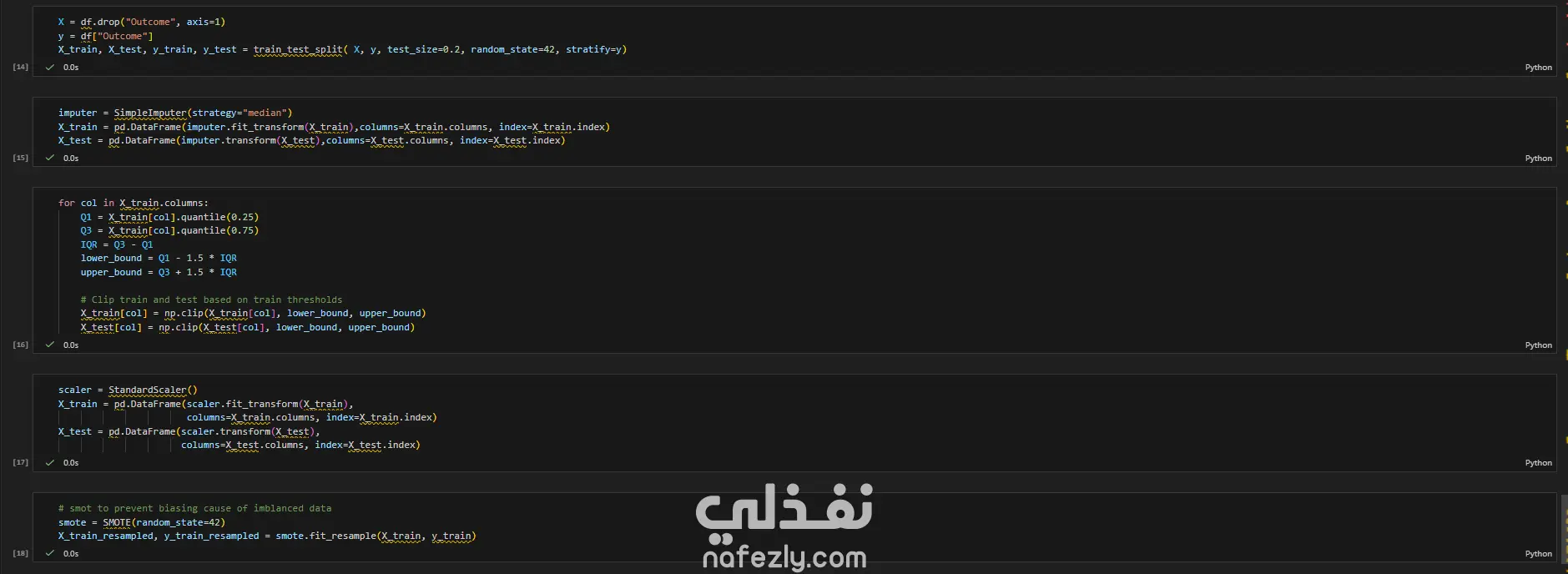
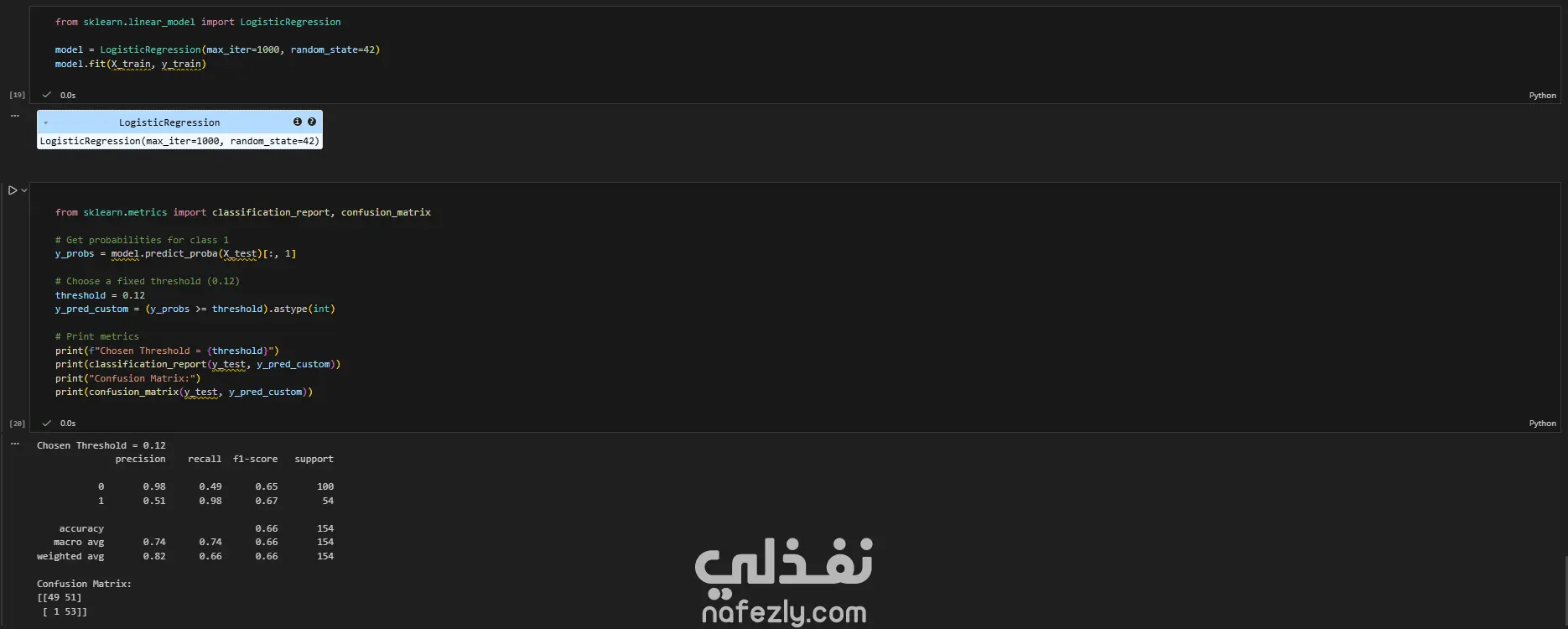
مشروع متكامل لبناء نموذج تعلم آلي لتشخيص مرض السكري (PIMA Diabetes Prediction)، مع التركيز الأساسي على تحقيق أعلى معدل استدعاء (Recall) لضمان اكتشاف جميع الحالات الإيجابية (المصابة) وتقليل مخاطر التشخيص الخاطئ. الخطوات بالتفصيل: تحميل واستكشاف البيانات (EDA): تم تحميل مجموعة البيانات (diabetes.csv) والقيام بتحليل استكشافي أولي. تم اكتشاف أن البيانات غير متوازنة (Imbalanced) (الخلية 5)، مما يتطلب معالجة خاصة. تم اكتشاف قيم "صفر" (0) غير منطقية في أعمدة حيوية مثل (Glucose, BloodPressure, Insulin, BMI)، والتي لا يمكن أن تكون صفراً في الواقع الطبي (الخلية 6). تنظيف ومعالجة البيانات (Data Preprocessing): تنظيف البيانات: تم استبدال جميع قيم "الصفر" غير المنطقية بقيم مفقودة (NaN) (الخلية 6). تقسيم البيانات: تم تقسيم البيانات إلى 80% للتدريب و 20% للاختبار باستخدام train_test_split، مع تفعيل خاصية stratify=y لضمان الحفاظ على نفس نسبة الفئات (المصابة وغير المصابة) في مجموعتي التدريب والاختبار (الخلية 14). ملء القيم المفقودة (Imputation): تم ملء قيم NaN الناتجة عن خطوة التنظيف باستخدام SimpleImputer واستراتيجية "الوسيط" (median) (الخلية 15). معالجة القيم المتطرفة (Outlier Handling): تم تحديد ومعالجة القيم الشاذة باستخدام طريقة (IQR) و "قصها" (Clipping) عند الحدين الأعلى والأدنى لضمان عدم تأثيرها على النموذج (الخلية 16). توحيد المقاييس (Scaling): تم تطبيق StandardScaler على جميع الميزات لتوحيد مقاييسها، وهو أمر ضروري لخوارزميات مثل SVM و Logistic Regression (الخلية 17). معالجة عدم توازن البيانات (Imbalance Handling): تم تطبيق تقنية SMOTE (Oversampling) على بيانات التدريب (الخلية 18) لإنشاء عينات اصطناعية للفئة الأقل (المصابين)، وذلك لتدريب النماذج على بيانات متوازنة. بناء النماذج، التحسين، والتقييم: تم بناء نموذجين رئيسيين للتقييم والمقارنة: الانحدار اللوجستي (Logistic Regression) (الخلية 19) جهاز المتجهات الداعمة (Support Vector Machine - SVC) (الخلية 21) تحسين الأداء (Threshold Tuning): نظراً لأن الهدف الطبي هو اكتشاف جميع المصابين (أعلى Recall)، تم التخلي عن عتبة القرار الافتراضية (0.5). تم اختيار عتبة منخفضة (0.12) لتحسين حساسية النماذج بشكل كبير لاكتشاف الحالات الإيجابية (الخلايا 20 و 21). النتائج وأفضل أداء: تم التركيز على مقياس الاستدعاء (Recall) كونه المقياس الأهم في هذا السياق الطبي. النموذج الأفضل (أعلى استدعاء): حقق نموذج Support Vector Machine (SVC) بعد ضبط العتبة (Threshold) إلى 0.12: Recall: 100% (نجح النموذج في التعرف على جميع الحالات الـ 54 المصابة في عينة الاختبار بنجاح). Accuracy: 50% (وهي دقة منخفضة متوقعة نتيجة الانحياز التام لزيادة الـ Recall). النموذج المتوازن: حقق نموذج Logistic Regression بعد ضبط العتبة (Threshold) إلى 0.12: Recall: 98% (نجح في اكتشاف 53 حالة من أصل 54). Accuracy: 66% (يقدم هذا النموذج توازناً أفضل بين الدقة والاستدعاء).
بطاقة العمل

طلب عمل مماثل














