Full-Pipeline Breast Cancer Classification: Data Cleaning, Feature Engineering & Optimized Model Analysis (100% Recall)







تفاصيل العمل
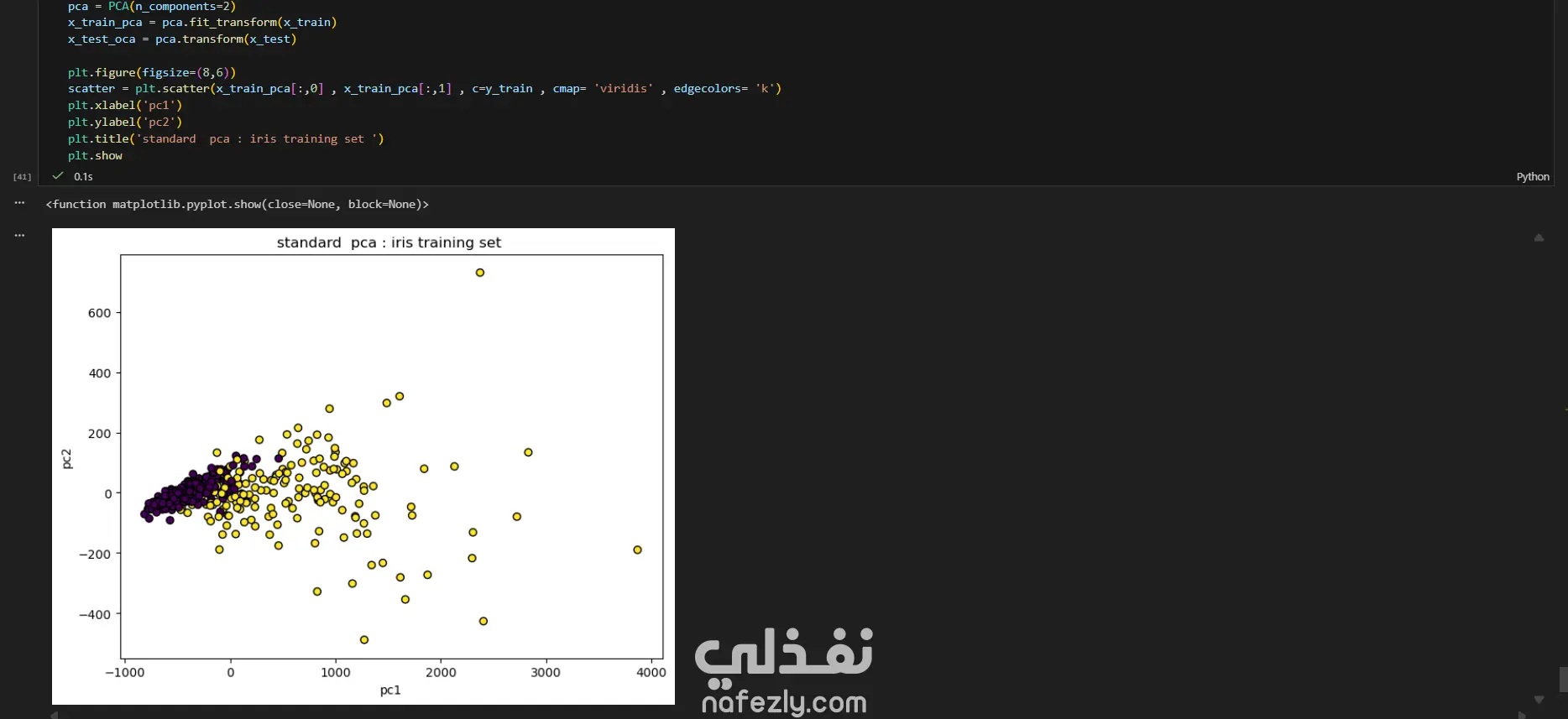
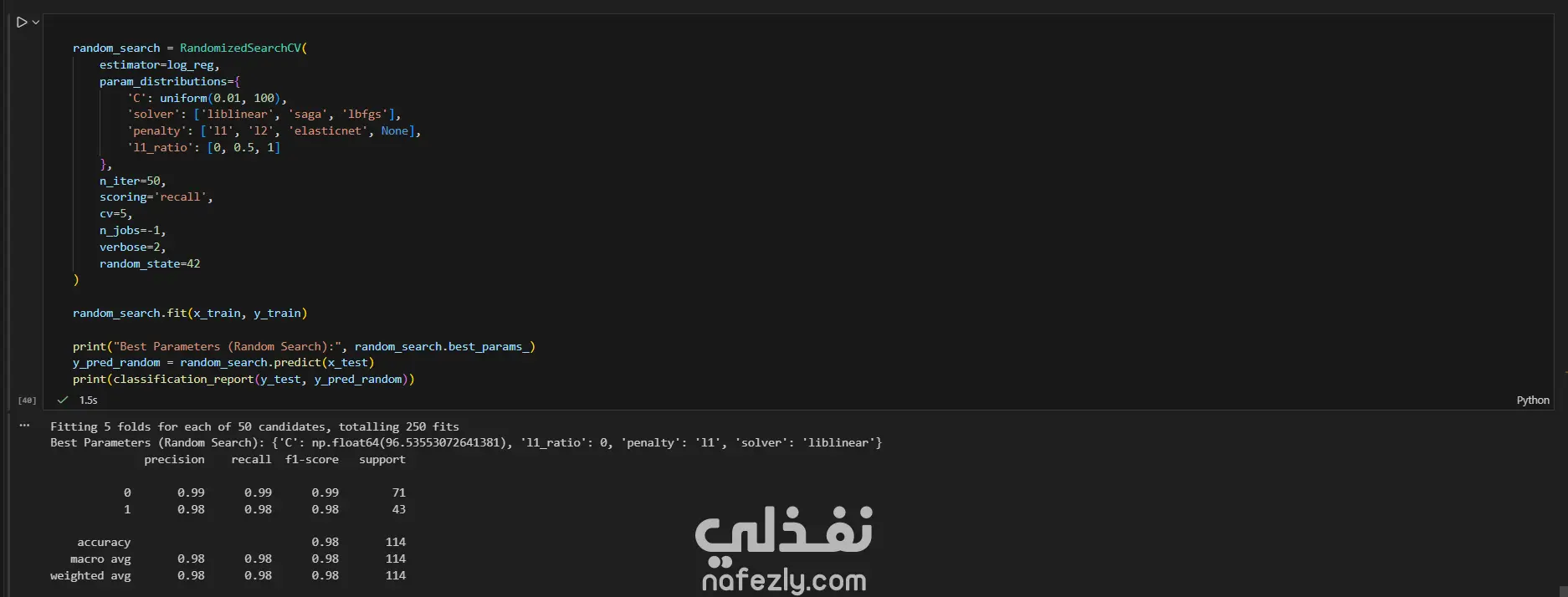
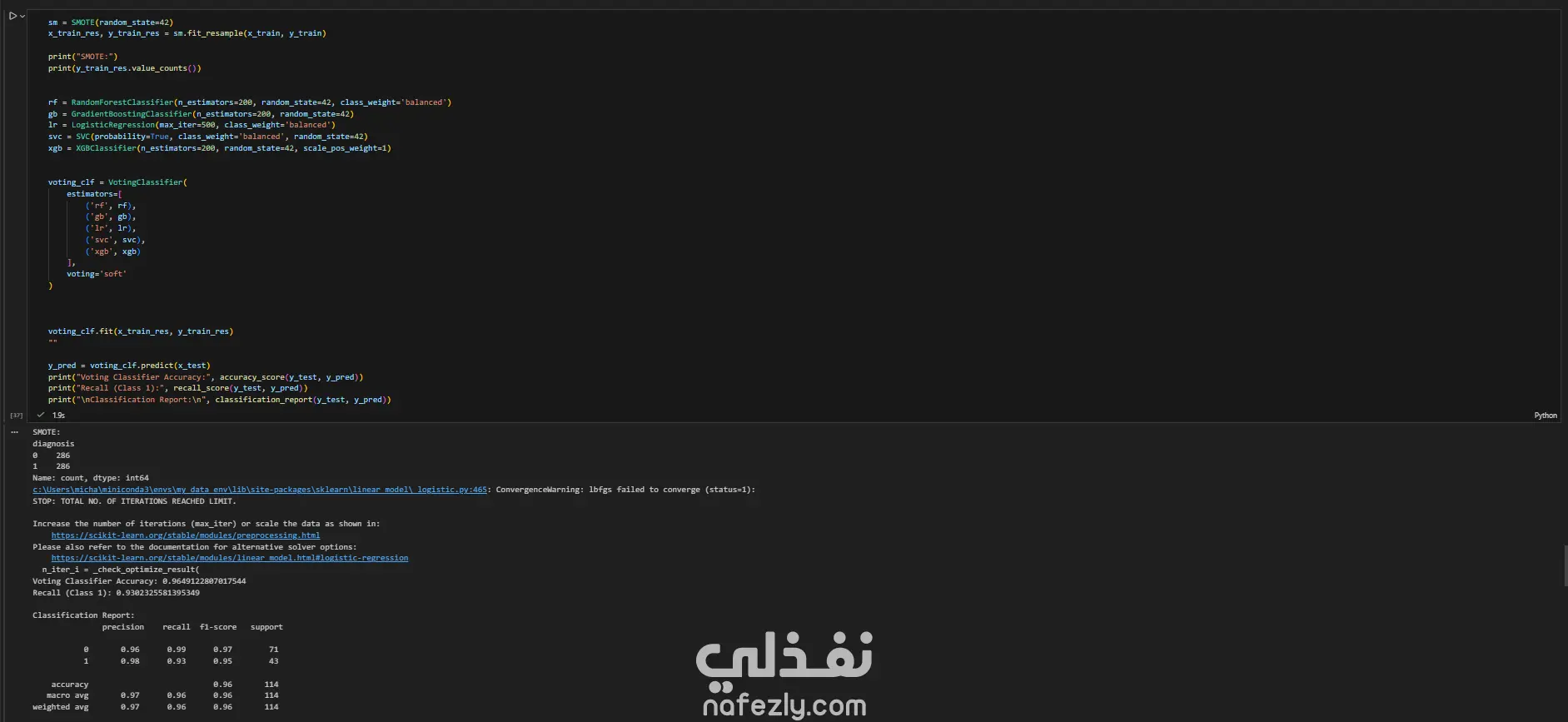
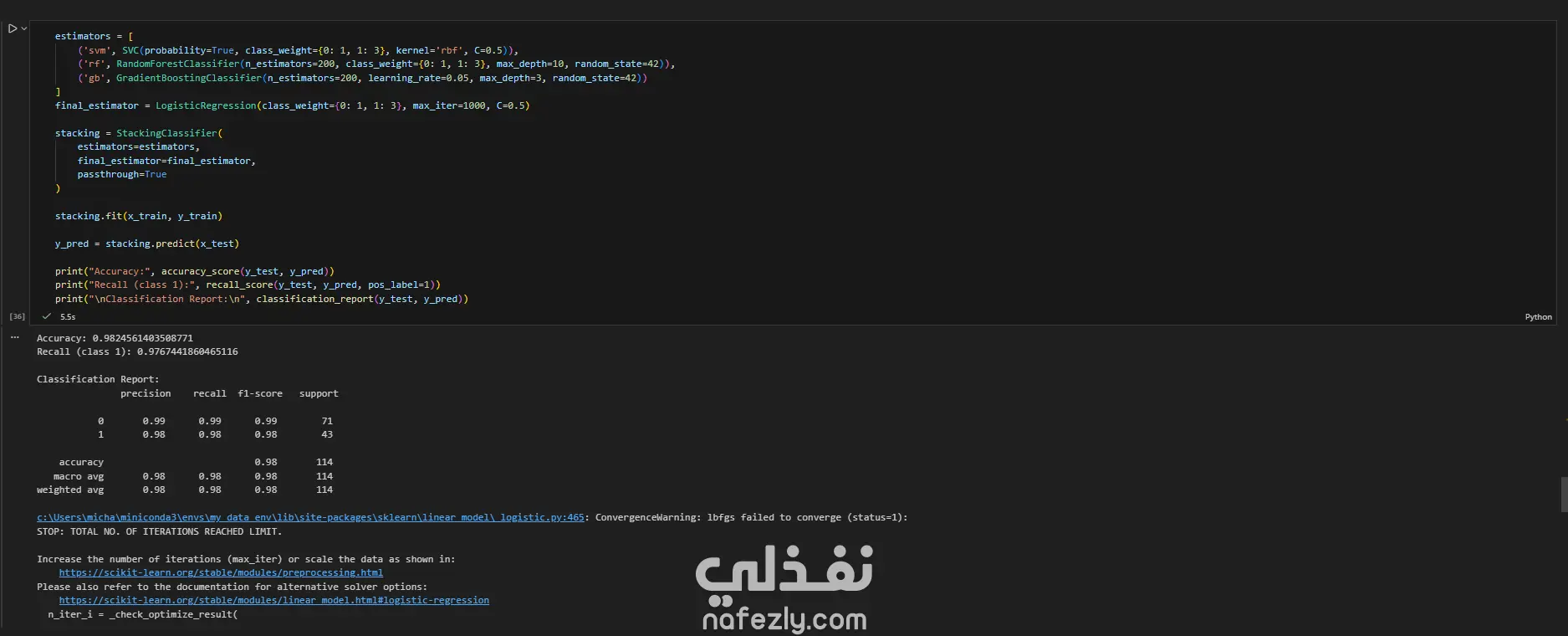
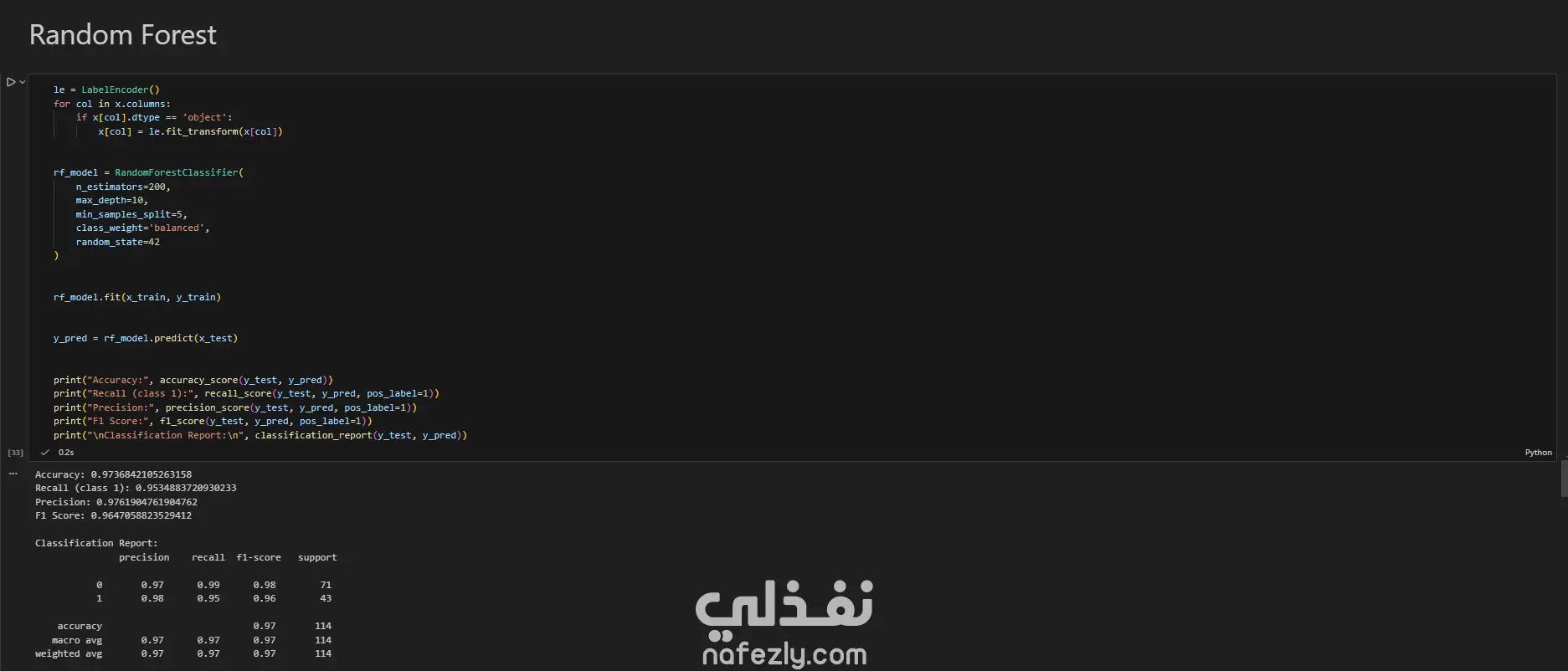
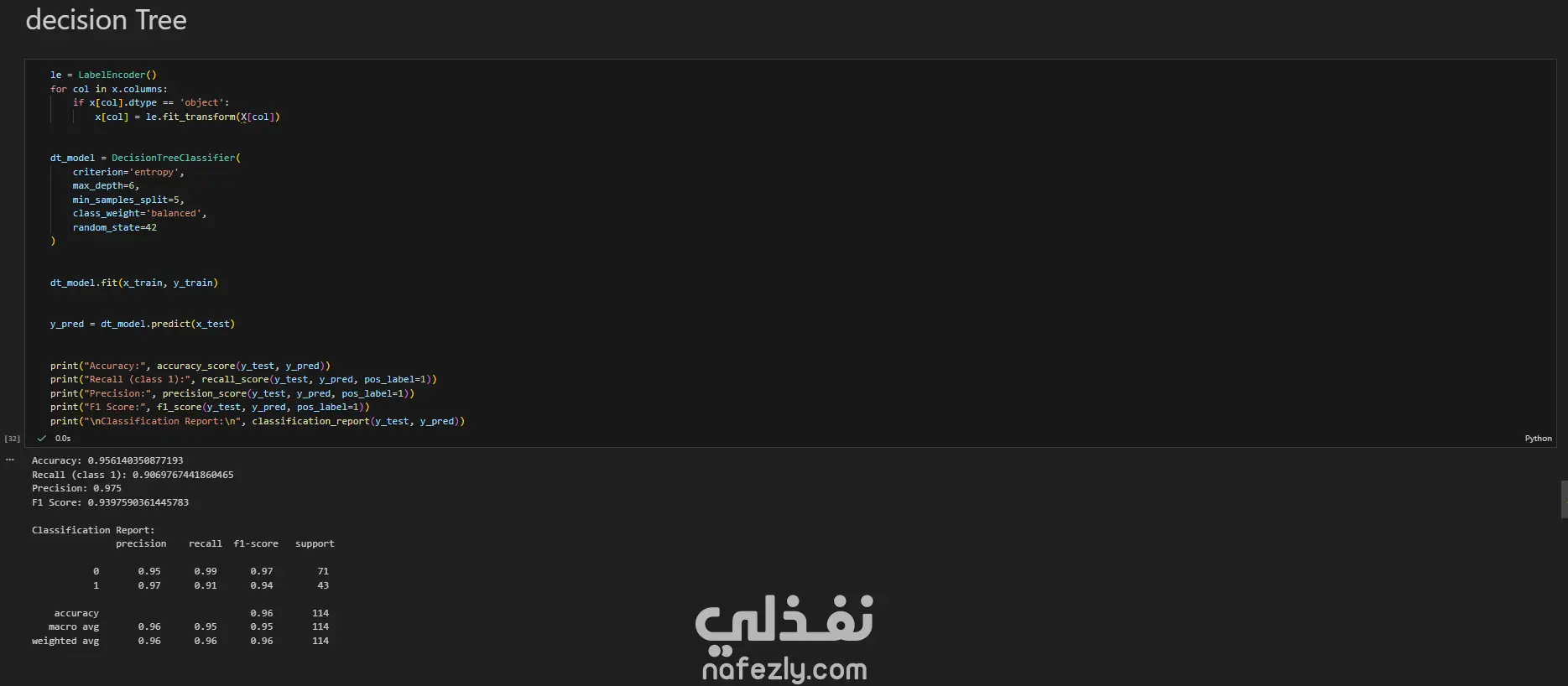
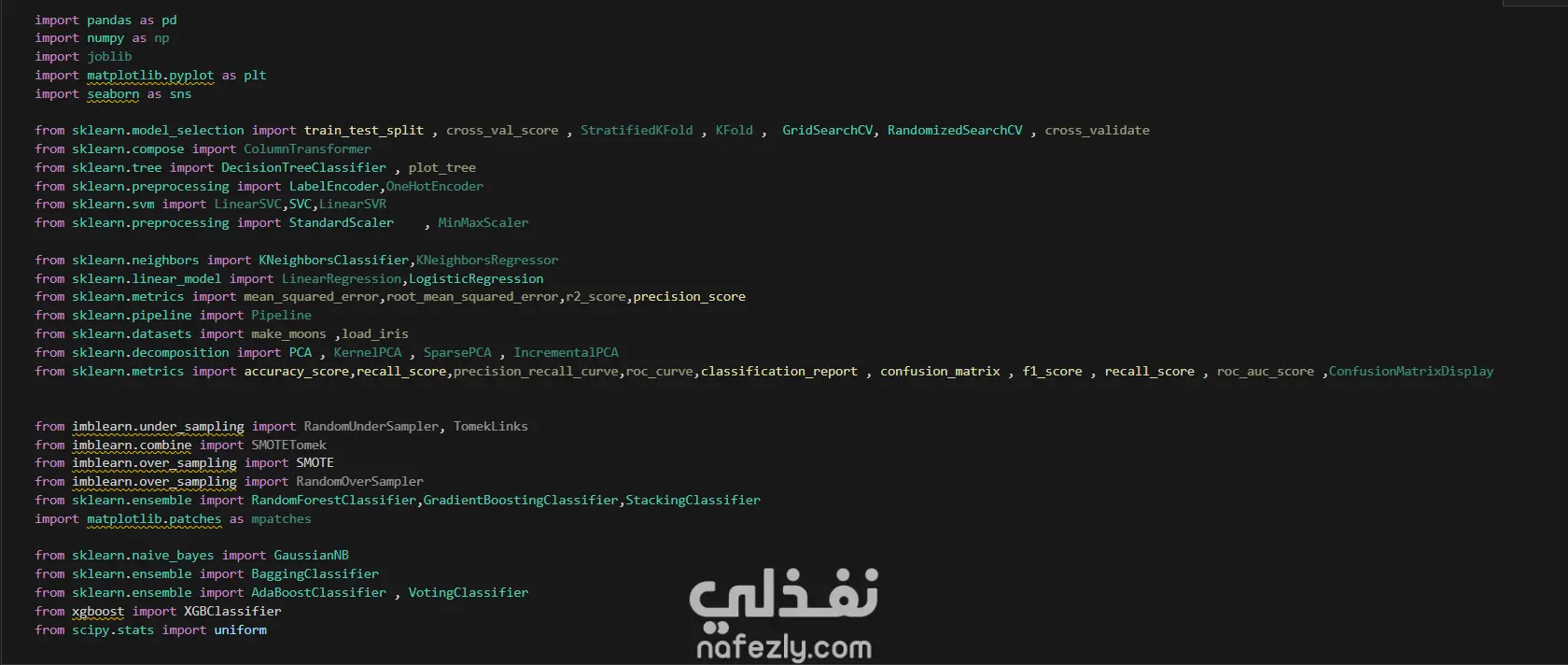
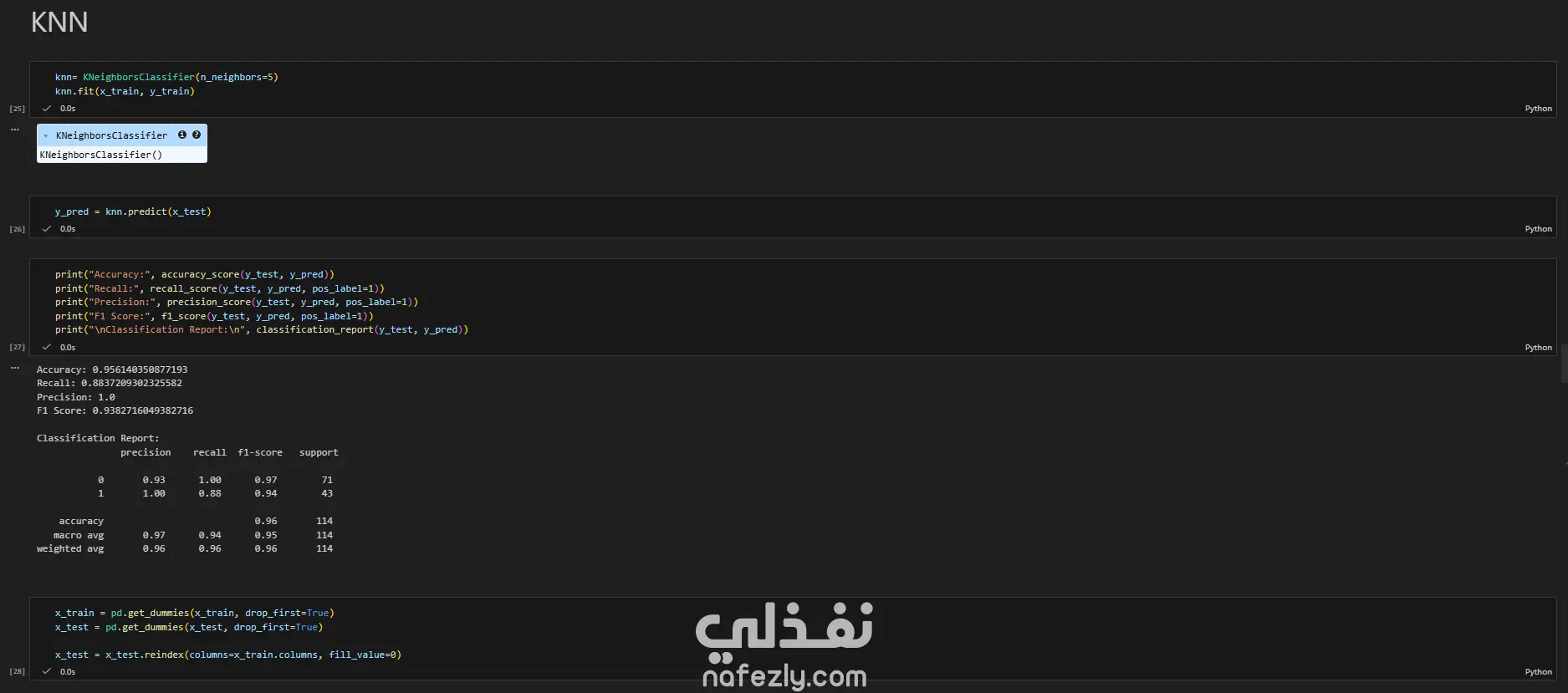
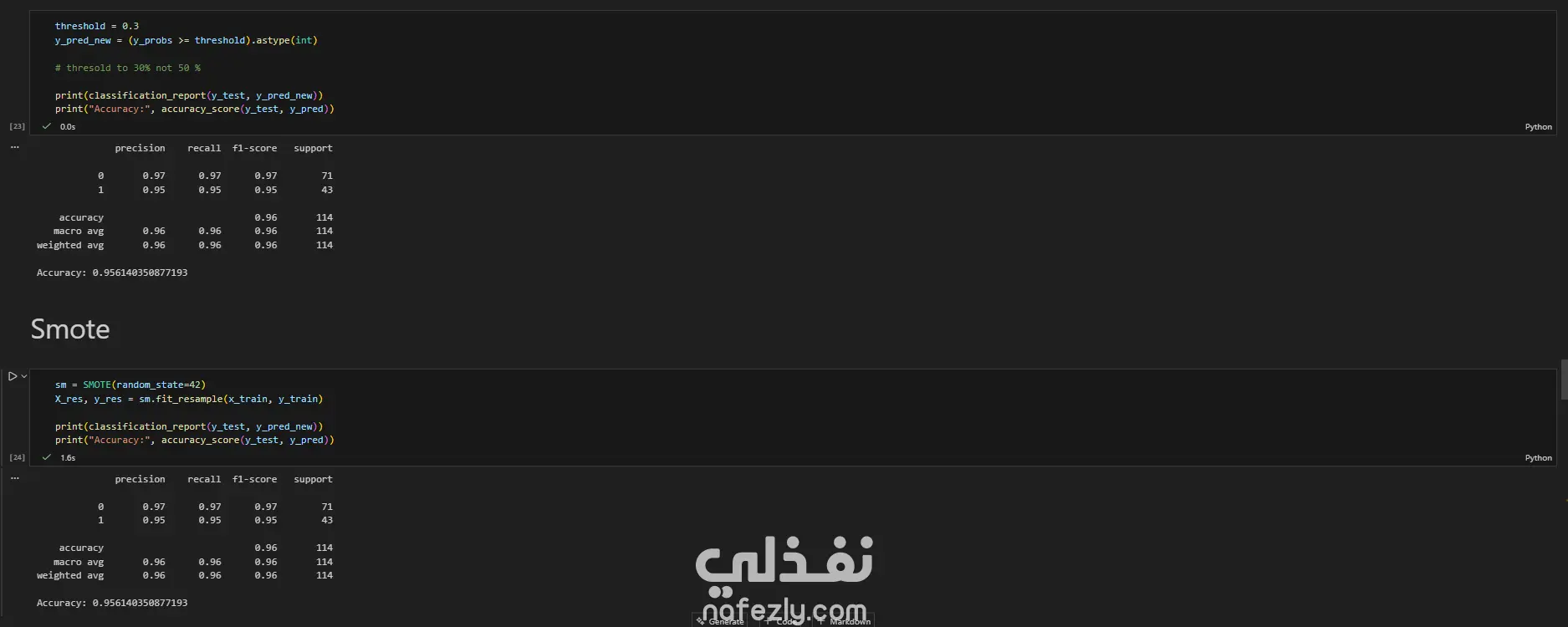
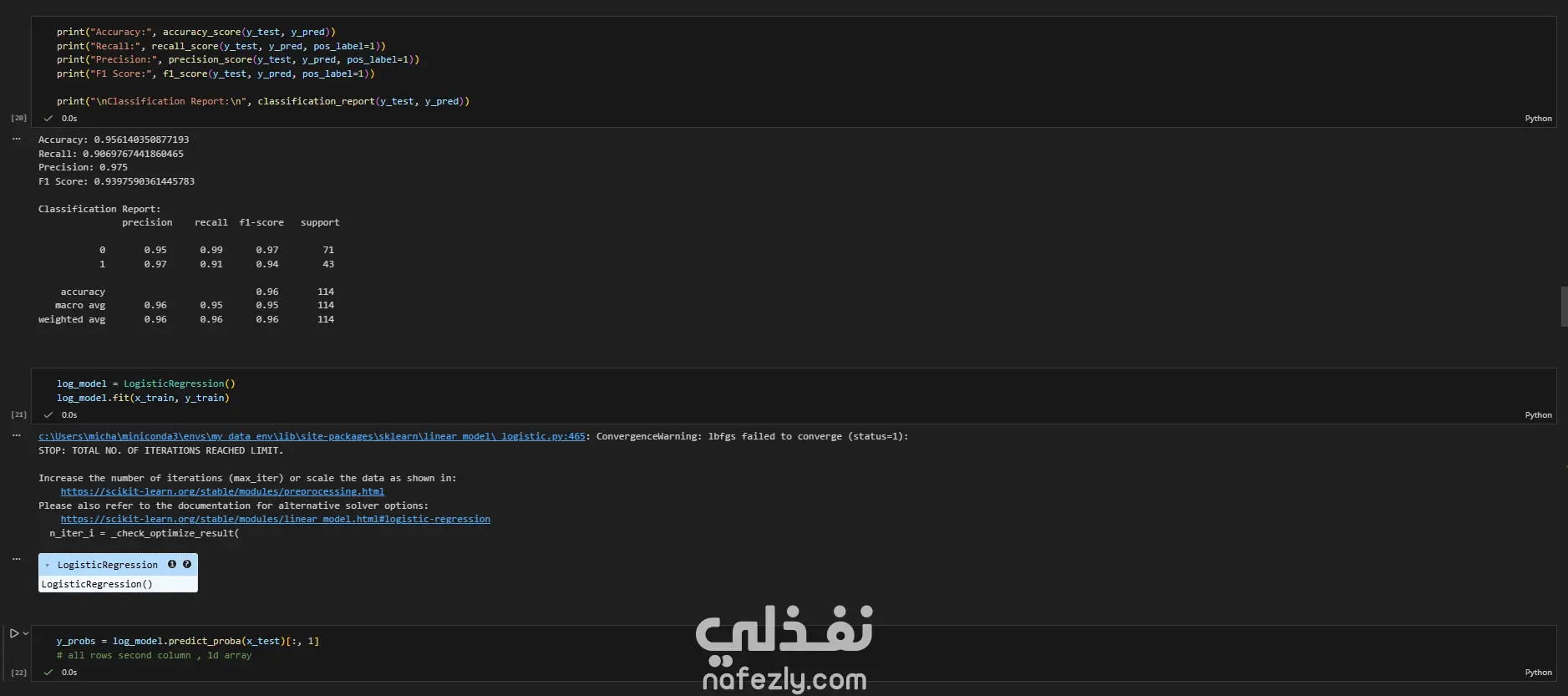
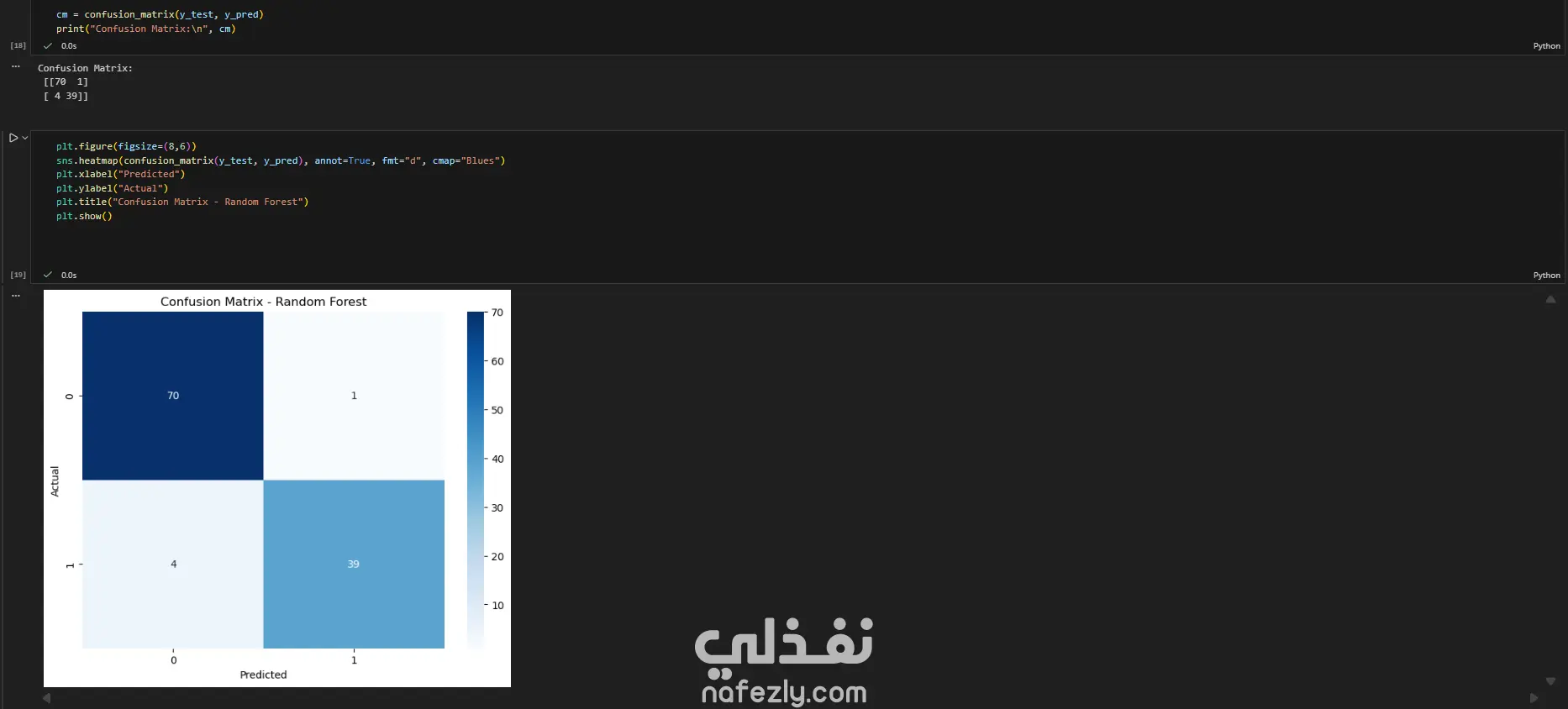
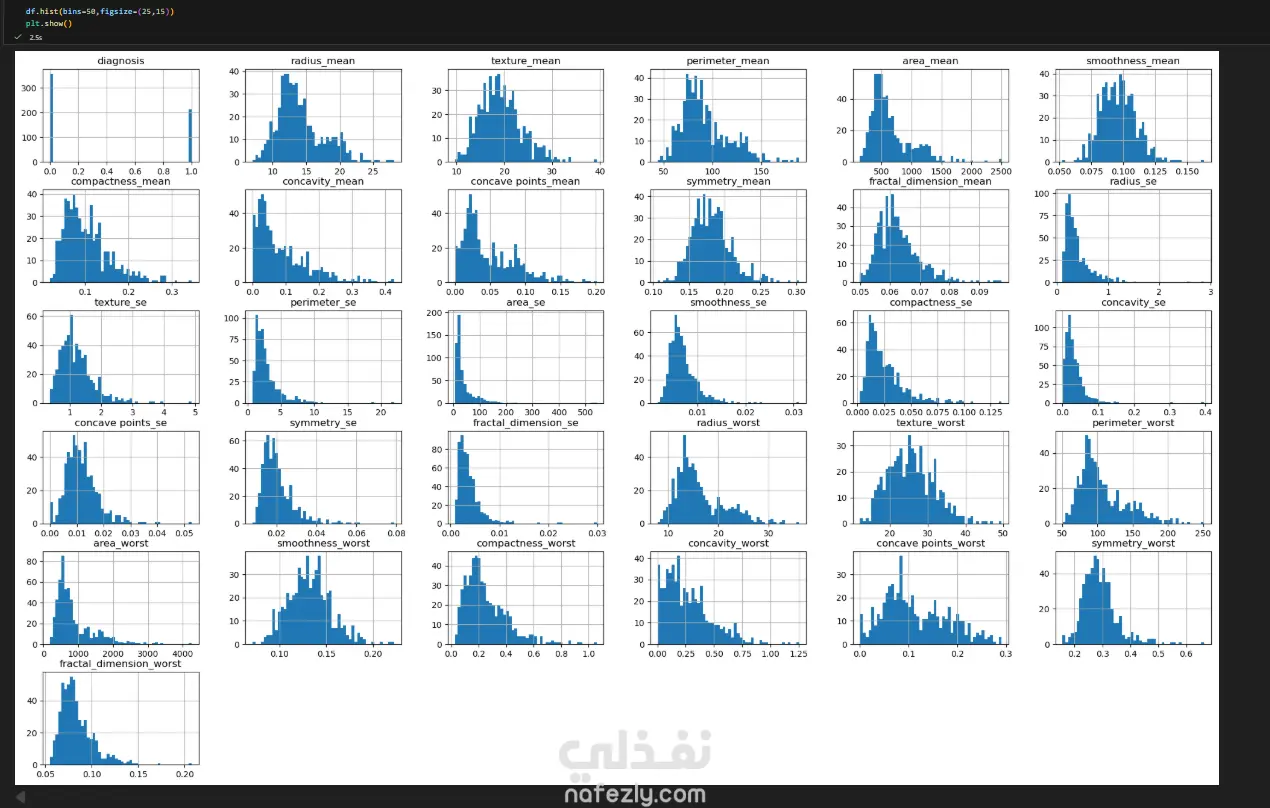
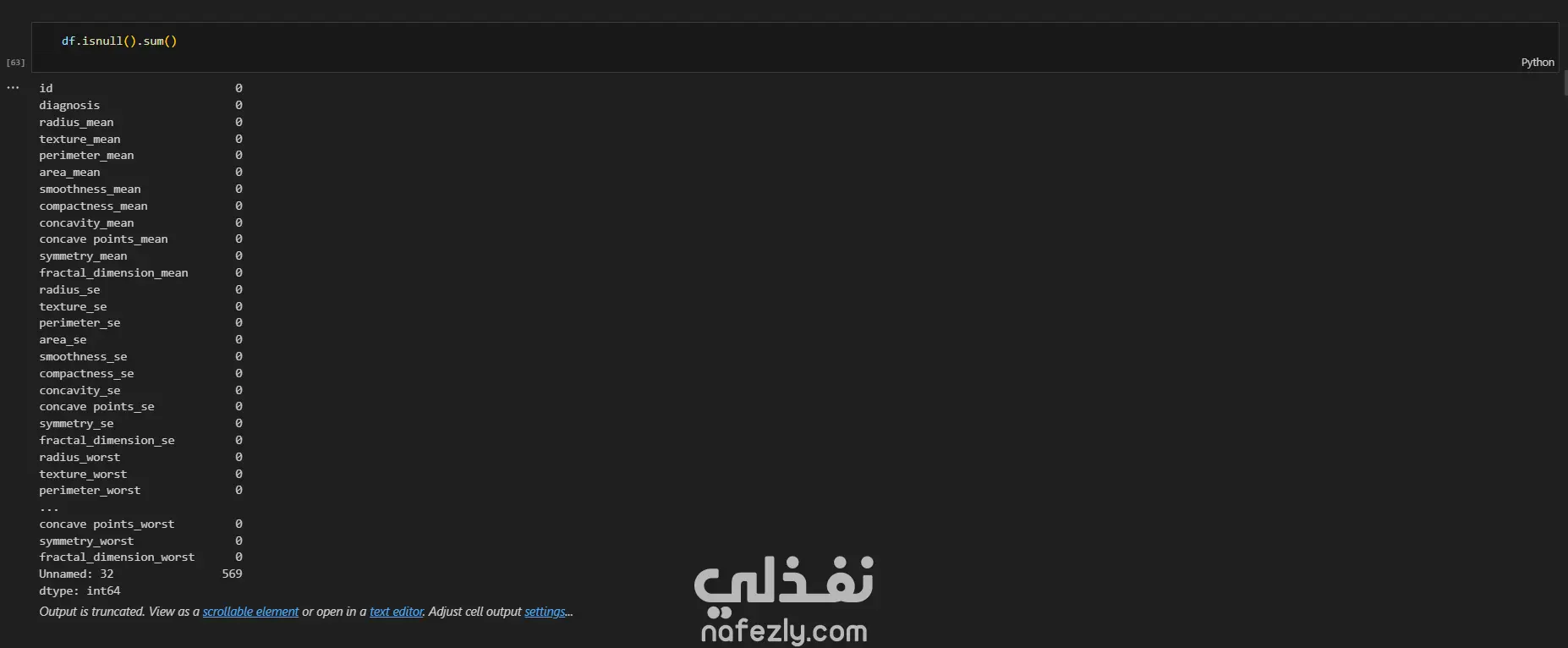
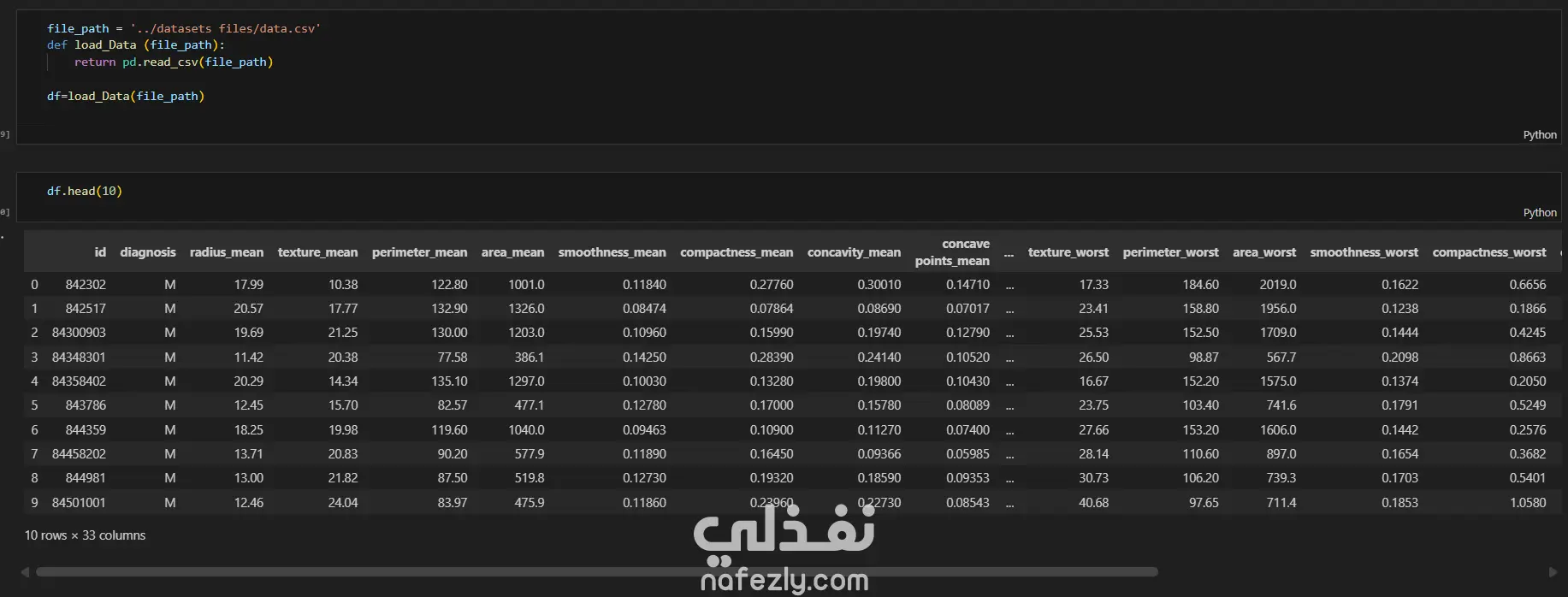
يهدف هذا المشروع إلى بناء وتدريب نماذج تعلم آلي متعددة لتصنيف أورام سرطان الثدي (خبيثة أو حميدة) بدقة عالية، باستخدام مجموعة بيانات سرطان الثدي (WBC) المعروفة. الخطوات بالتفصيل: تحضير البيانات (Data Preprocessing): بدأ العمل بتحميل البيانات وفهم طبيعتها وخصائصها الإحصائية. تم تنظيف البيانات عبر حذف الأعمدة غير الضرورية (مثل id) والأعمدة التي تحتوي على قيم فارغة بالكامل (Unnamed: 32). تم تحويل المتغير المستهدف (Diagnosis) من قيم نصية (M و B) إلى قيم رقمية (1 و 0) باستخدام LabelEncoder لتهيئة البيانات للنماذج. التحليل الاستكشافي (EDA): تم إنشاء رسوم بيانية (Histograms) لجميع المتغيرات لفهم توزيعها وخصائصها (الخلية 47). تقسيم البيانات والتدريب الأولي: تم تقسيم البيانات إلى 80% للتدريب و 20% للاختبار (train_test_split) مع تحديد random_state لضمان إمكانية تكرار النتائج. تم تدريب نموذج أساسي (Baseline) باستخدام الانحدار اللوجستي (Logistic Regression)، والذي حقق دقة 95.6% ومعدل استدعاء 90.7% (الخلايا 16-20). تطبيق وتقييم النماذج (Modeling & Evaluation): تم تجربة مجموعة واسعة من خوارزميات التصنيف لضمان الوصول لأفضل أداء ممكن، وشملت: K-Nearest Neighbors (KNN) (الخلية 25) Support Vector Machine (SVC) مع RBF Kernel (الخلية 30) Gaussian Naive Bayes (الخلية 31) شجرة القرار (Decision Tree) (الخلية 32) الغابات العشوائية (Random Forest) (الخلية 33) التقنيات المتقدمة (Advanced Techniques): نماذج التجميع (Ensemble Methods): تم تطبيق تقنيات متقدمة مثل Bagging Classifier (الخلية 34)، AdaBoost (الخلية 35)، Stacking Classifier (الخلية 36)، و Voting Classifier (بالدمج مع XGBoost) (الخلية 37). معالجة عدم التوازن (Imbalance Handling): تم استخدام تقنية SMOTE لزيادة عينات الفئة الأقل (الأورام الخبيثة) في بيانات التدريب (الخلية 37)، بالإضافة لاستخدام class_weight في النماذج (مثل SVC و RF) لضمان عدم تحيز النموذج. هندسة الميزات (Feature Engineering): تم تطبيق StandardScaler لتوحيد مقياس البيانات، ثم استخدام تحليل المكونات الرئيسية (PCA) لتقليل الأبعاد إلى 10 مكونات رئيسية وتدريب نموذج عليها (الخلية 38). تحسين الأداء (Hyperparameter Tuning): تم استخدام GridSearchCV و RandomizedSearchCV للبحث عن أفضل المعاملات، مع التركيز على مقياس "Recall" كونه الأهم في التشخيص الطبي (الخلايا 39-40). النتائج وأفضل أداء: في مهام التشخيص الطبي، يعتبر مقياس الاستدعاء (Recall) هو الأهم لضمان اكتشاف جميع الحالات الإيجابية (الأورام الخبيثة) وتقليل النتائج السلبية الكاذبة (False Negatives). أفضل أداء شامل (Overall): حقق نموذج Bagging Classifier (الموجود في الخلية 34) أفضل توازن وأعلى أداء، حيث وصل إلى: دقة (Accuracy): 99.1% استدعاء (Recall): 100% (نجح النموذج في اكتشاف جميع الحالات الخبيثة في مجموعة الاختبار). أداء متميز آخر: نموذج KNN مع ضبط العتبة (Threshold Tuning) (الخلية 29) حقق أيضاً استدعاء 100% (مع دقة 95.6%). أفضل أداء متوازن: نماذج Stacking Classifier، PCA + Logistic Regression، و Tuned Logistic Regression حققت جميعها أداءً ممتازاً ومتوازناً بدقة 98.2% واستدعاء 97.7%.
بطاقة العمل

طلب عمل مماثل














