مشروع تحليل بيانات بطاقات الائتمان باستخدام تقنيات الـ Clustering
تفاصيل العمل
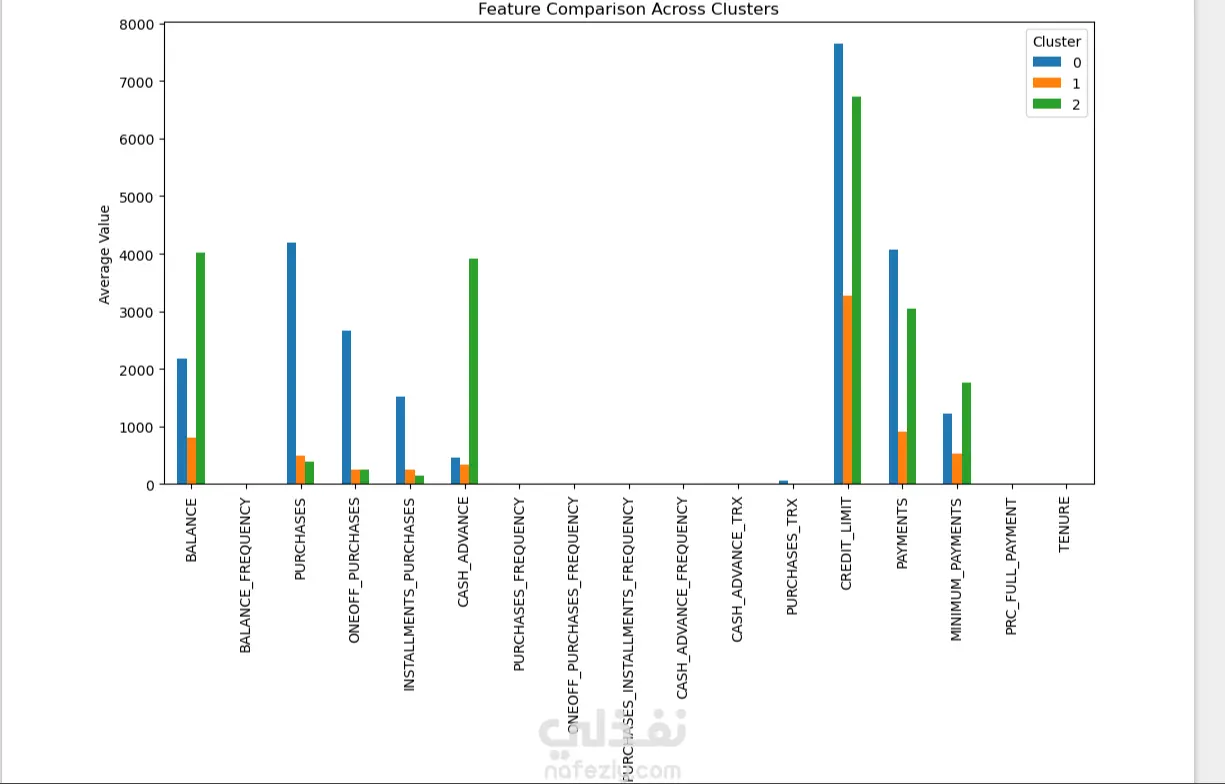
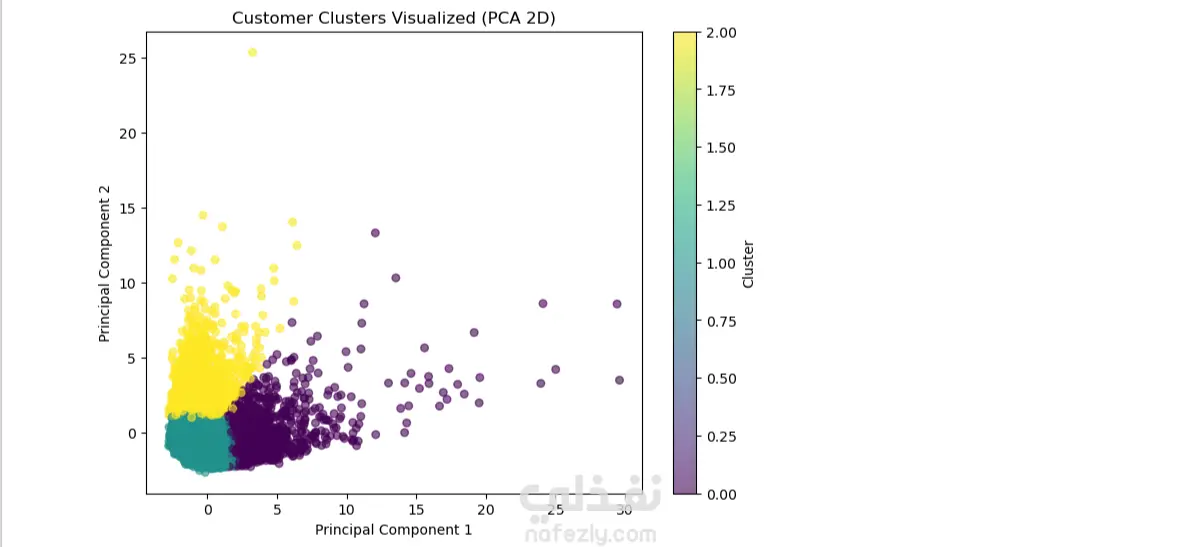
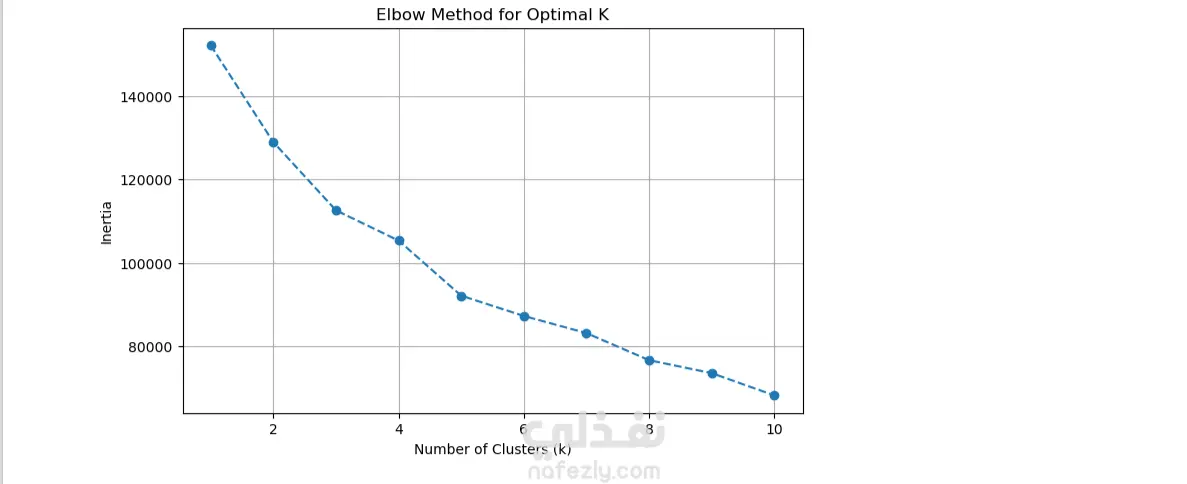
هذا المشروع عبارة عن نموذج عملي في تحليل البيانات باستخدام لغة Python داخل بيئة Jupyter Notebook. يعتمد على مجموعة بيانات حقيقية من ملف "CC GENERAL.csv" المتعلق ببطاقات الائتمان، ويهدف إلى تطبيق خوارزميات الـ Clustering لتصنيف العملاء بناءً على سلوكياتهم المالية. يساعد ذلك في اكتشاف أنماط الإنفاق، الاستخدام، والمخاطر المحتملة، مما يوفر رؤى قيمة للشركات المالية أو البنوك. الخطوات الرئيسية في الـ Notebook: استيراد المكتبات الأساسية: Pandas لمعالجة البيانات وإدارة الجداول. NumPy للعمليات الرياضية والحسابية. Matplotlib و Seaborn لإنشاء الرسوم البيانية والتصورات. تحميل وفحص البيانات: قراءة الملف CSV وعرض عينة من الجدول (8950 سجل × 18 عموداً). التحقق من هيكل البيانات باستخدام info() لمعرفة أنواع الأعمدة وعدد القيم غير الفارغة. التأكد من عدم وجود تكرارات باستخدام duplicated().sum(). اكتشاف القيم المفقودة باستخدام isna().sum() (مثل 313 قيمة مفقودة في عمود MINIMUM_PAYMENTS وواحدة في CREDIT_LIMIT). التحليل والتصور: إنشاء رسم بياني شريطي (Bar Plot) باستخدام matplotlib لمقارنة متوسط قيم الميزات الرئيسية عبر الكتل المختلفة. الرسم يغطي ميزات مثل: BALANCE (الرصيد)، PURCHASES (المشتريات)، CASH_ADVANCE (السحب النقدي)، PURCHASES_FREQUENCY (تكرار المشتريات)، وغيرها. يساعد التصور في توضيح الاختلافات بين مجموعات العملاء، مثل العملاء ذوي الإنفاق العالي أو الذين يعتمدون على السحب النقدي. البيانات المستخدمة: تشمل أعمدة رئيسية مثل: CUST_ID (معرف العميل)، BALANCE_FREQUENCY (تكرار تحديث الرصيد)، ONEOFF_PURCHASES (المشتريات لمرة واحدة)، INSTALLMENTS_PURCHASES (المشتريات بالتقسيط)، CREDIT_LIMIT (حد الائتمان)، PAYMENTS (المدفوعات)، PRC_FULL_PAYMENT (نسبة الدفع الكامل)، و TENURE (مدة الاشتراك). البيانات نظيفة نسبياً مع بعض القيم المفقودة التي يمكن معالجتها في الخطوات التالية. النتائج والفائدة: يقسم الـ Clustering العملاء إلى مجموعات متميزة بناءً على سلوكياتهم، مما يسهل تحديد العملاء عالي المخاطر أو ذوي الإنفاق المنخفض. الرسم البياني النهائي يقدم مقارنة بصرية واضحة، تساعد في اتخاذ قرارات أعمالية مثل تصميم حملات تسويقية مستهدفة أو تحسين إدارة المخاطر الائتمانية. المشروع قابل للتوسع بإضافة خوارزميات مثل K-Means من Scikit-learn لتحديد عدد الكتل الأمثل. المهارات المستخدمة: برمجة Python في Jupyter Notebook. معالجة وتنظيف البيانات باستخدام Pandas و NumPy. التصور البياني باستخدام Matplotlib و Seaborn. مفاهيم الـ Machine Learning غير الموجَّه (Unsupervised Learning) مثل الـ Clustering. هذا المشروع يعكس خبرتي في تحليل البيانات المالية ويمكن تخصيصه لأي مجموعة بيانات مشابهة. إذا كنت بحاجة إلى خدمات في تحليل البيانات، بناء نماذج Clustering، أو تطوير تقارير تفاعلية، فأنا جاهز للمساعدة! تواصل معي لمناقشة التفاصيل أو طلب تعديلات مخصصة. الكلمات المفتاحية: تحليل بيانات، Clustering، Python، Pandas، بطاقات ائتمان، Machine Learning، تصور بيانات.
مهارات العمل
بطاقة العمل

طلب عمل مماثل












