تصنيف النصوص باستخدام Streamlit و Transformers
تفاصيل العمل
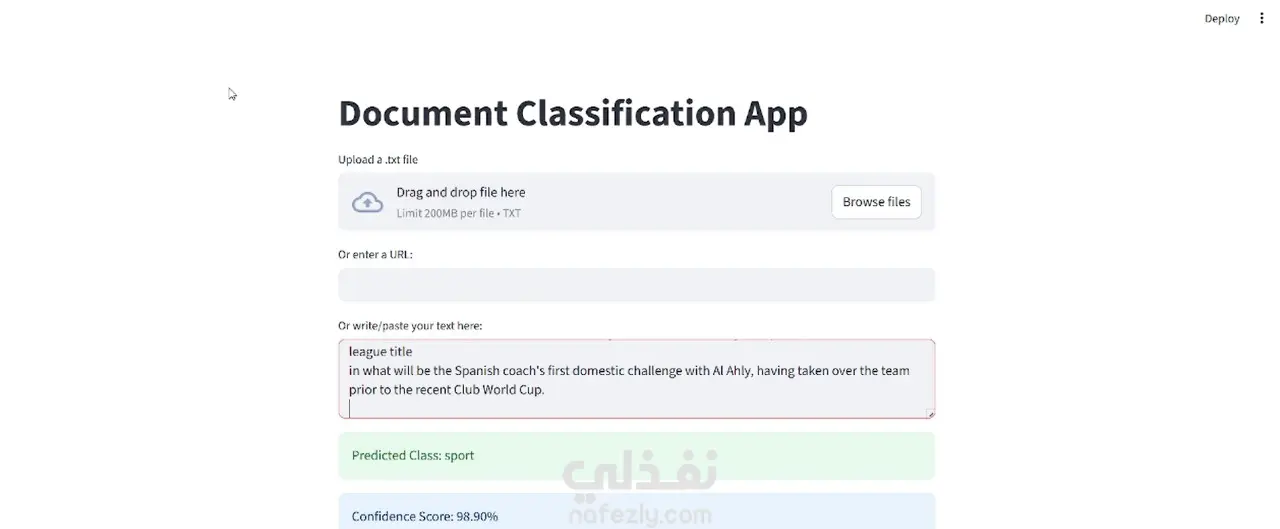
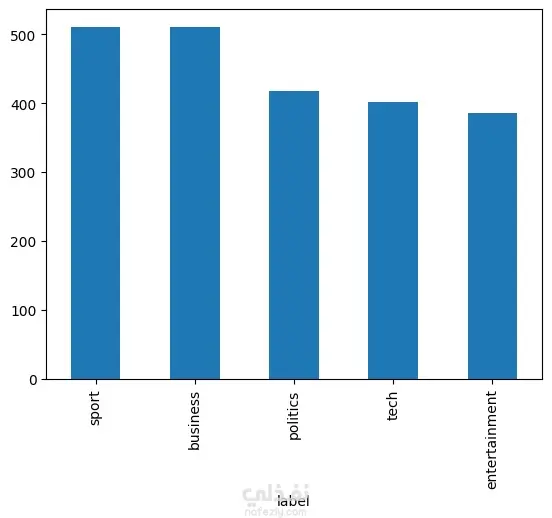
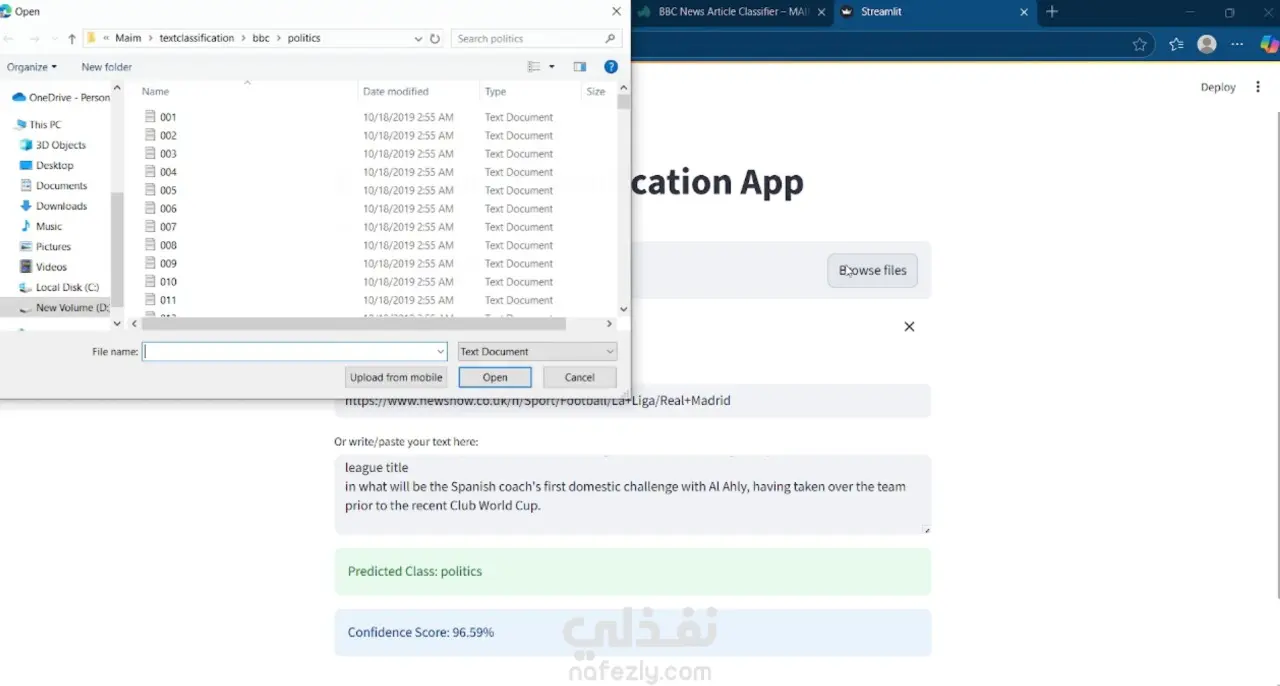
قمتُ بتطوير نظام متكامل لتصنيف النصوص اعتمادًا على مجموعة بيانات BBC News، يتضمن المراحل التالية: معالجة البيانات النصية (Text Preprocessing): تحويل النصوص إلى حروف صغيرة (lowercasing)، إزالة علامات الترقيم والكلمات الشائعة (stopwords)، وتطبيق عملية التجذير (lemmatization). النماذج الأساسية (Baseline Models): بناء نموذجين باستخدام تمثيلات TF-IDF مع خوارزميتي الانحدار اللوجستي (Logistic Regression) و نايف بايز (Naïve Bayes)، مع تقييم الأداء باستخدام مقاييس الدقة (Accuracy)، الدقة الإحصائية (Precision)، الاستدعاء (Recall)، ومصفوفة الالتباس (Confusion Matrix). النموذج المتقدم: تحسين الأداء عبر تخصيص نموذج DistilBERT من مكتبة Hugging Face Transformers، مما أدى إلى تحسن ملحوظ في نتائج التصنيف مقارنة بالنماذج الأساسية. نشر التطبيق: إنشاء تطبيق تفاعلي باستخدام Streamlit يتيح للمستخدم: 🔹 كتابة النص أو لصقه مباشرة 🔹 رفع ملف نصي (.txt) 🔹 إدخال رابط لمقال 🔹 والحصول على فئة الخبر المتوقعة مع درجة الثقة (Confidence Score)
مهارات العمل
بطاقة العمل

طلب عمل مماثل











