في مشروع تحليل وتوقع جودة النبيذ الأحمر (Red Wine Quality Prediction)اشتغلت على مجموعة بيانات عن النبيذ الأحمر عشان أكتشف العوامل اللي بتأثر على جودته، وأبني نموذج يتوقع إذا كان النبيذ "جيد" أو "ضعيف" من خلال بياناته الكيميائية.
🔹 1: تجهيز البيانات وتنظيفها
فحصت البيانات للتأكد إنها خالية من القيم الناقصة أو الأخطاء.
تأكدت إن كل الأعمدة بصيغة صحيحة.
فهمت مكونات البيانات وعدد الصفوف والأعمدة (حوالي 1599 صف و12 عمود).
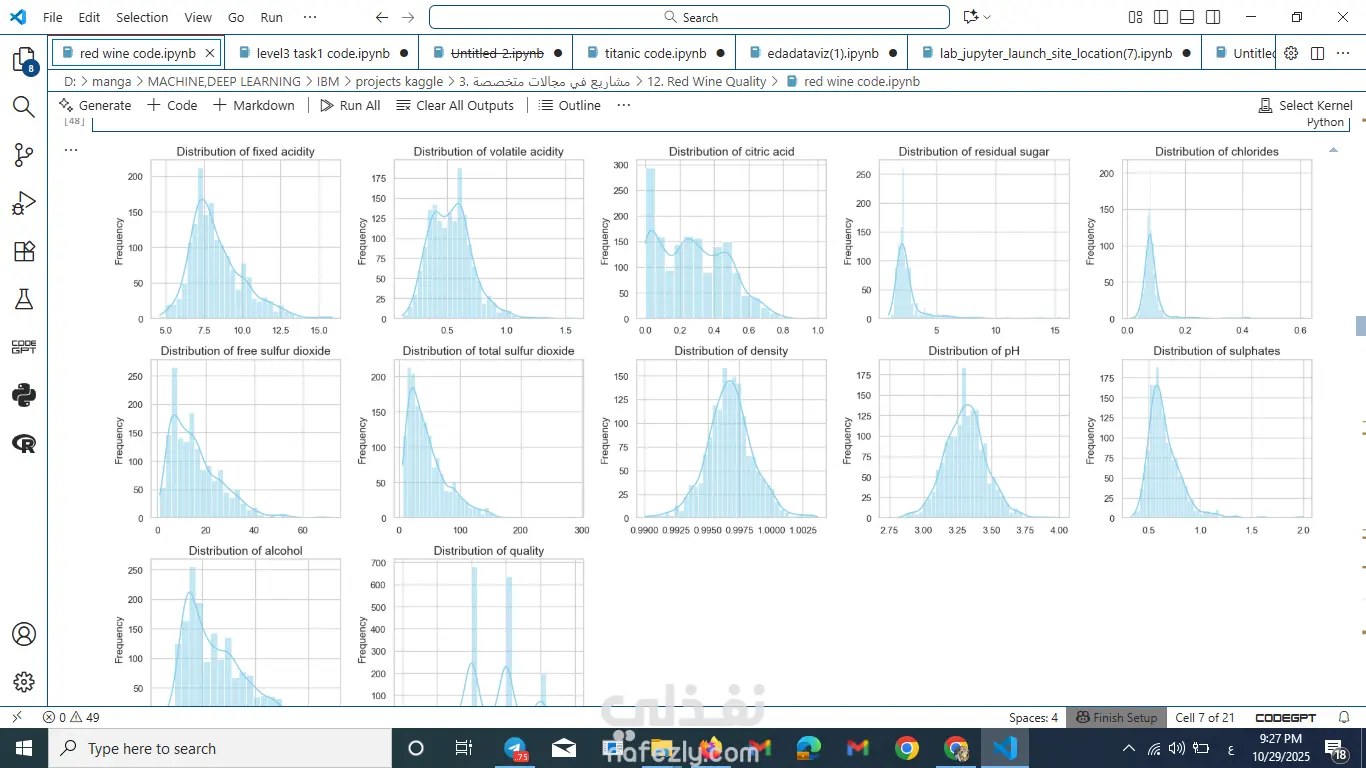
🔹 2: تحليل استكشافي (EDA)
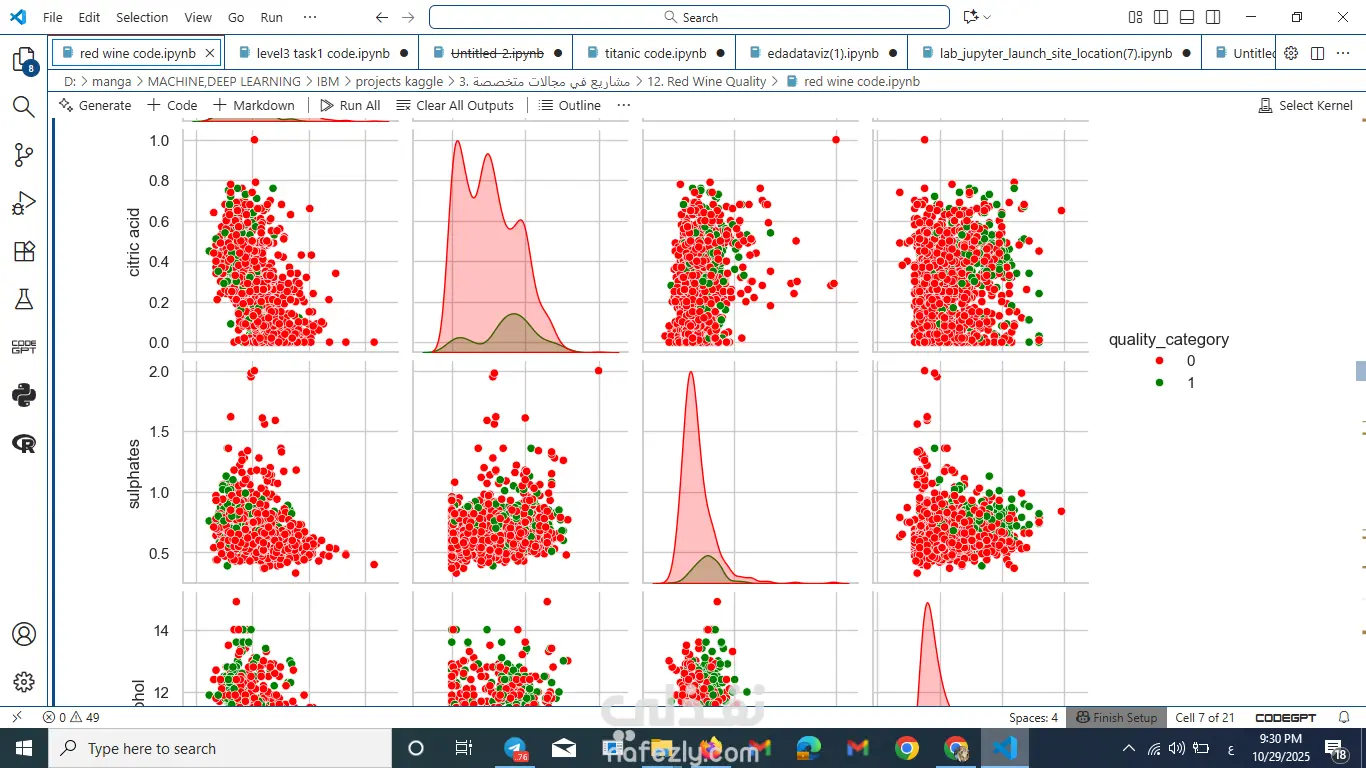
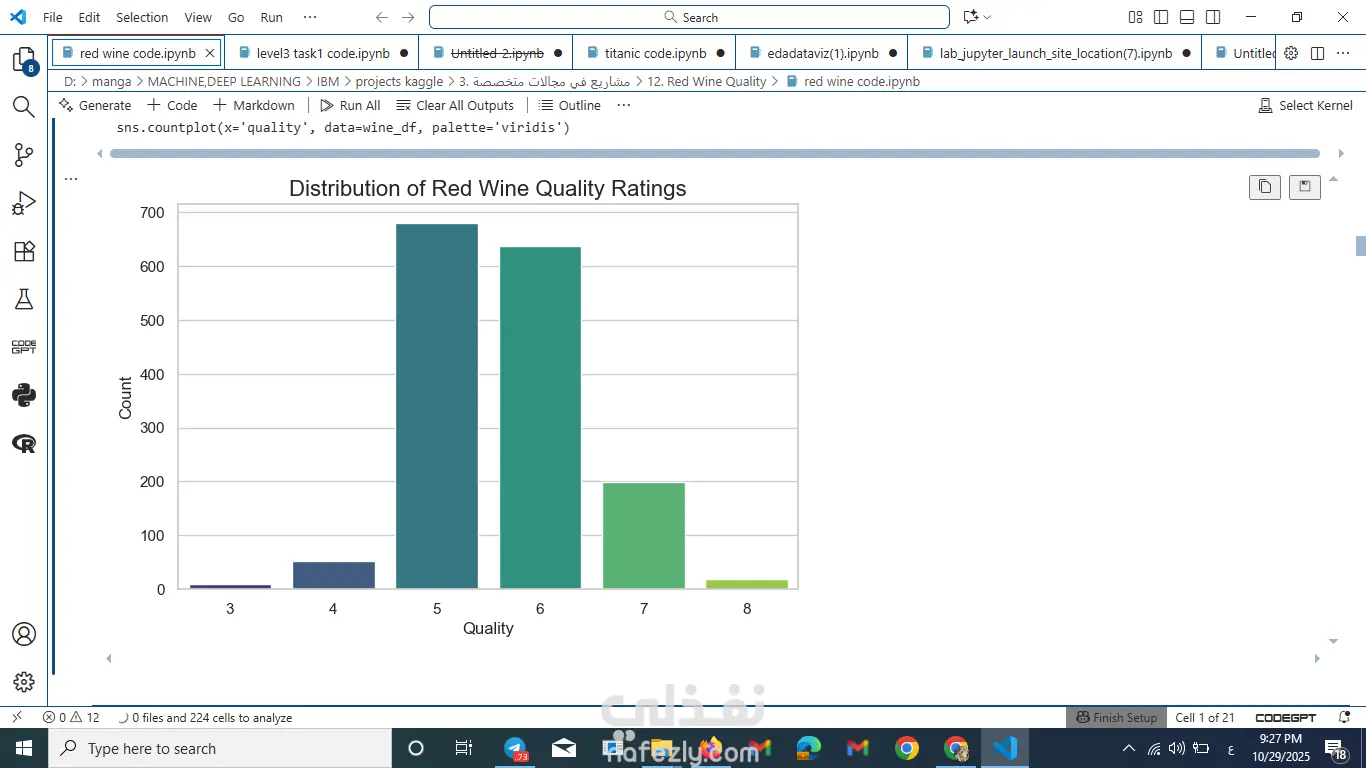
عملت تحليل بصري باستخدام Matplotlib وSeaborn وPlotly.
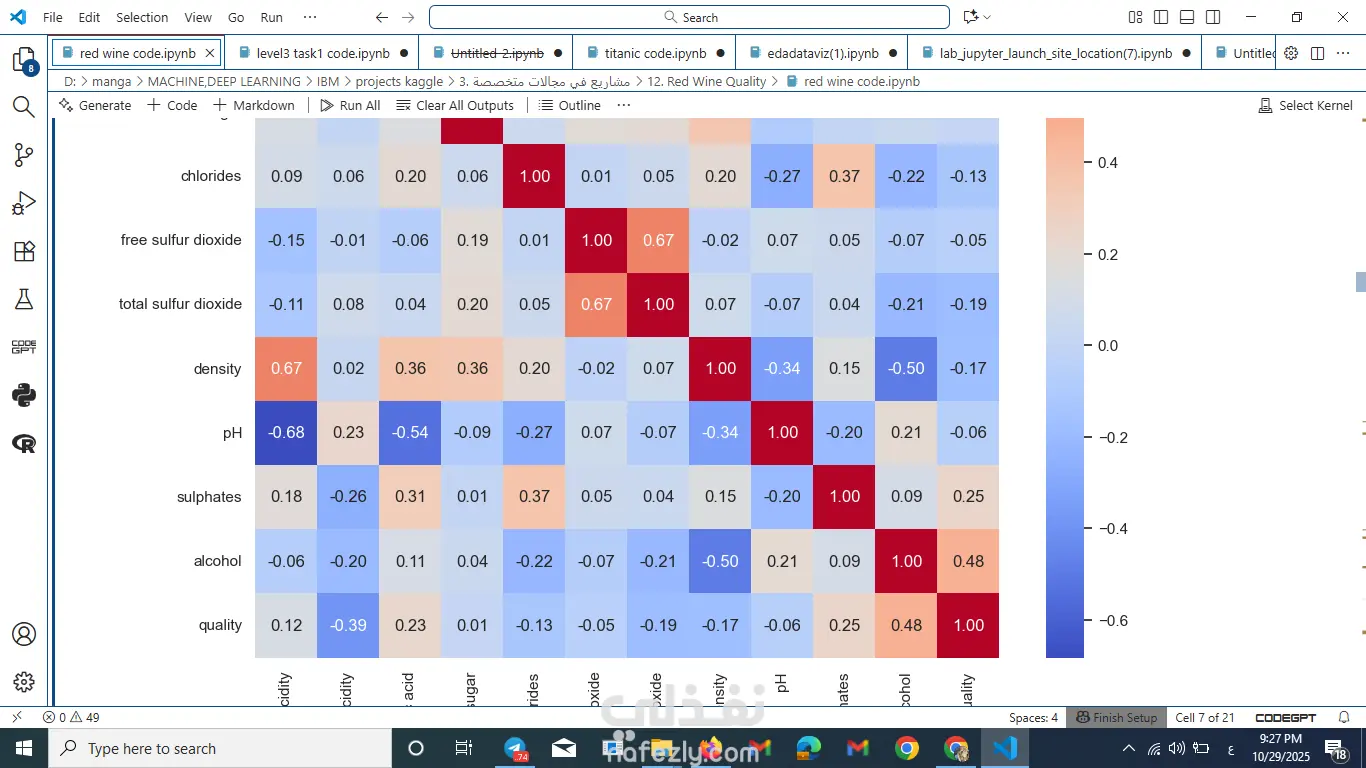
لاحظت إن جودة النبيذ بتزيد لما بيزيد الكحول والسلفات، وبتقل مع زيادة الحموضة المتطايرة.
درست العلاقة بين الخصائص المختلفة وجودة النبيذ.
🔹 3: تجهيز البيانات للنمذجة
قسمت الجودة لفئتين: "جيد" و"ضعيف".
استخدمت StandardScaler لتوحيد المقاييس.
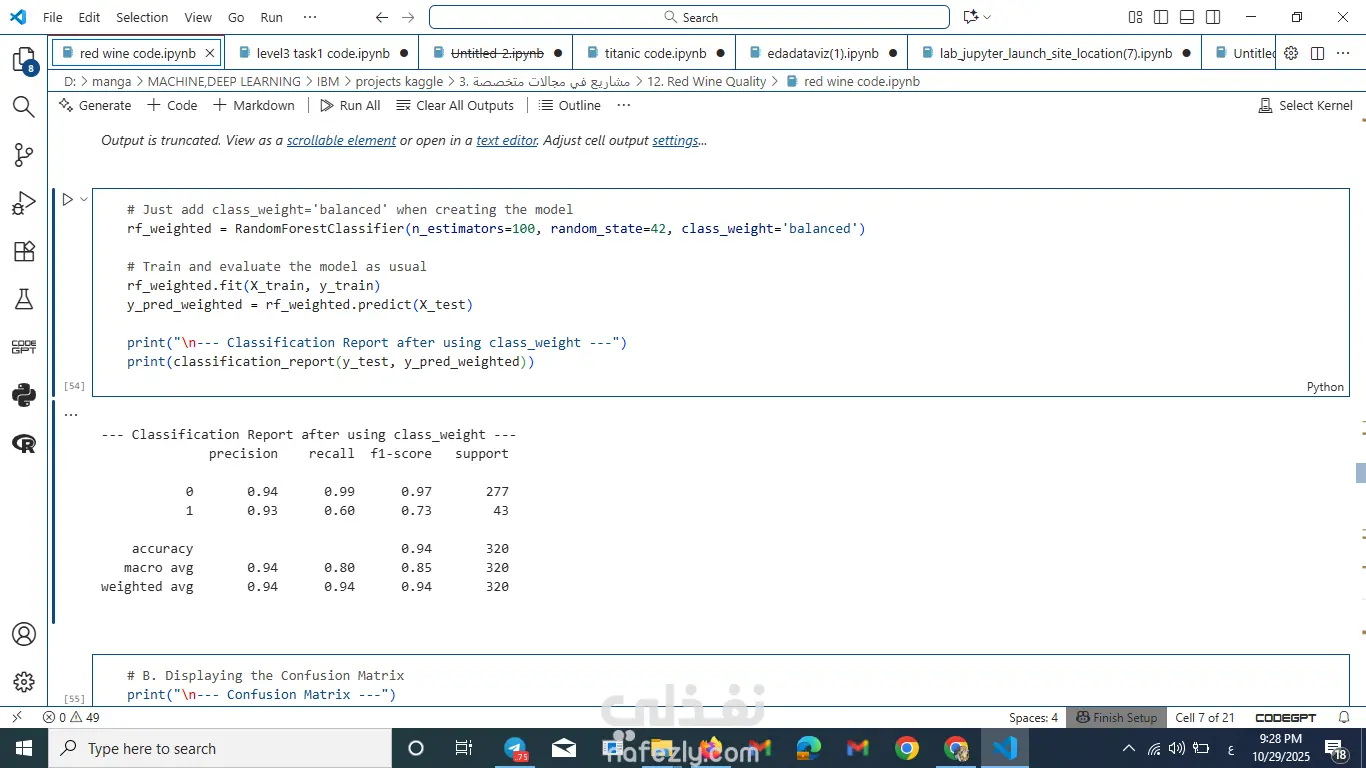
عالجت عدم التوازن بين الفئات باستخدام SMOTE.
🔹 4: بناء النموذج وتجربته
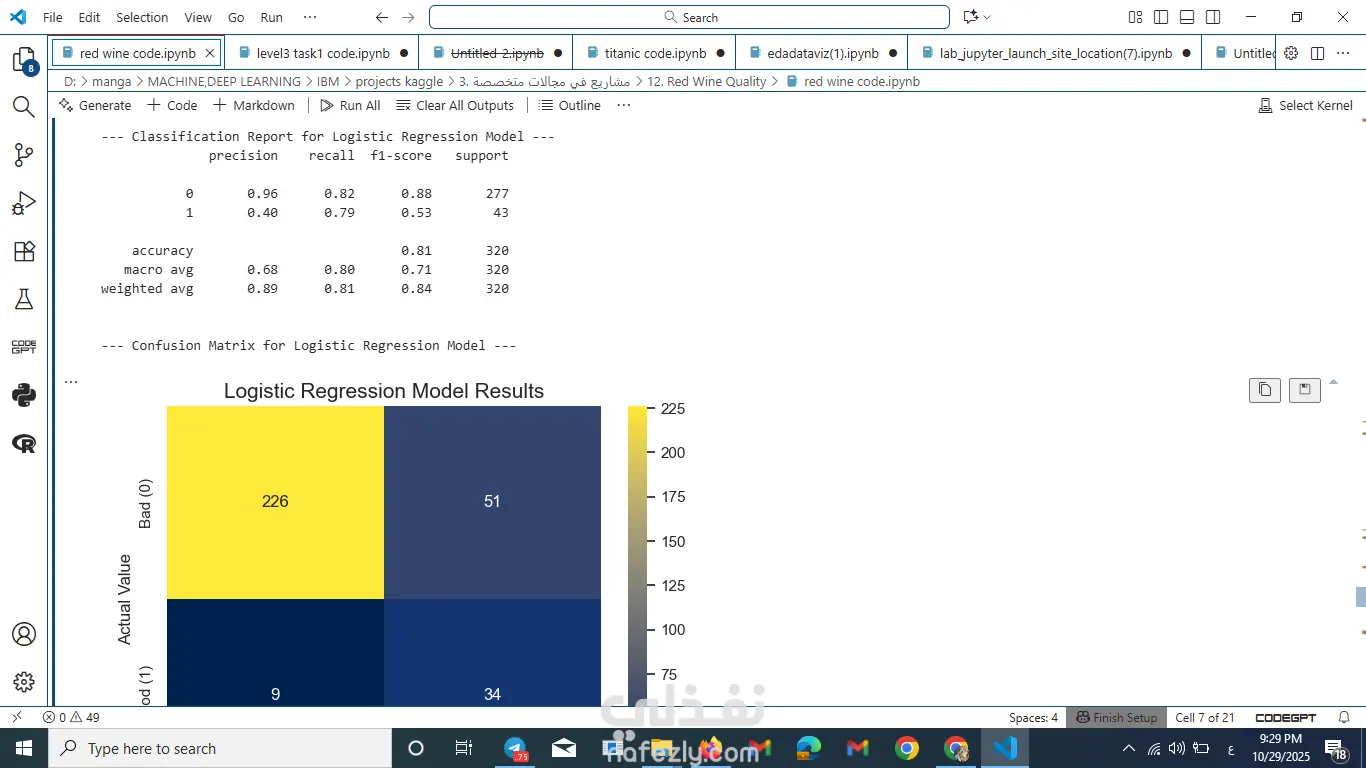
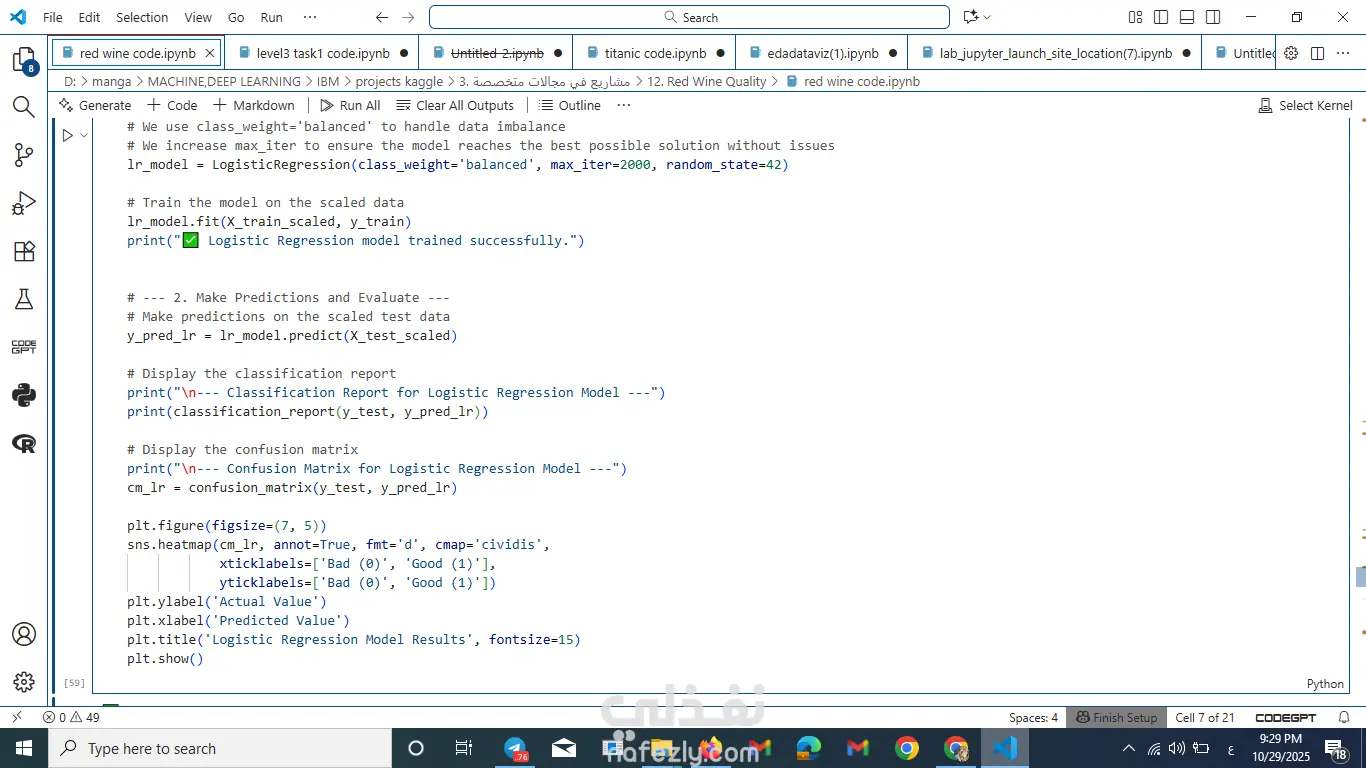
جربت أكثر من خوارزمية: Logistic Regression وRandom Forest.
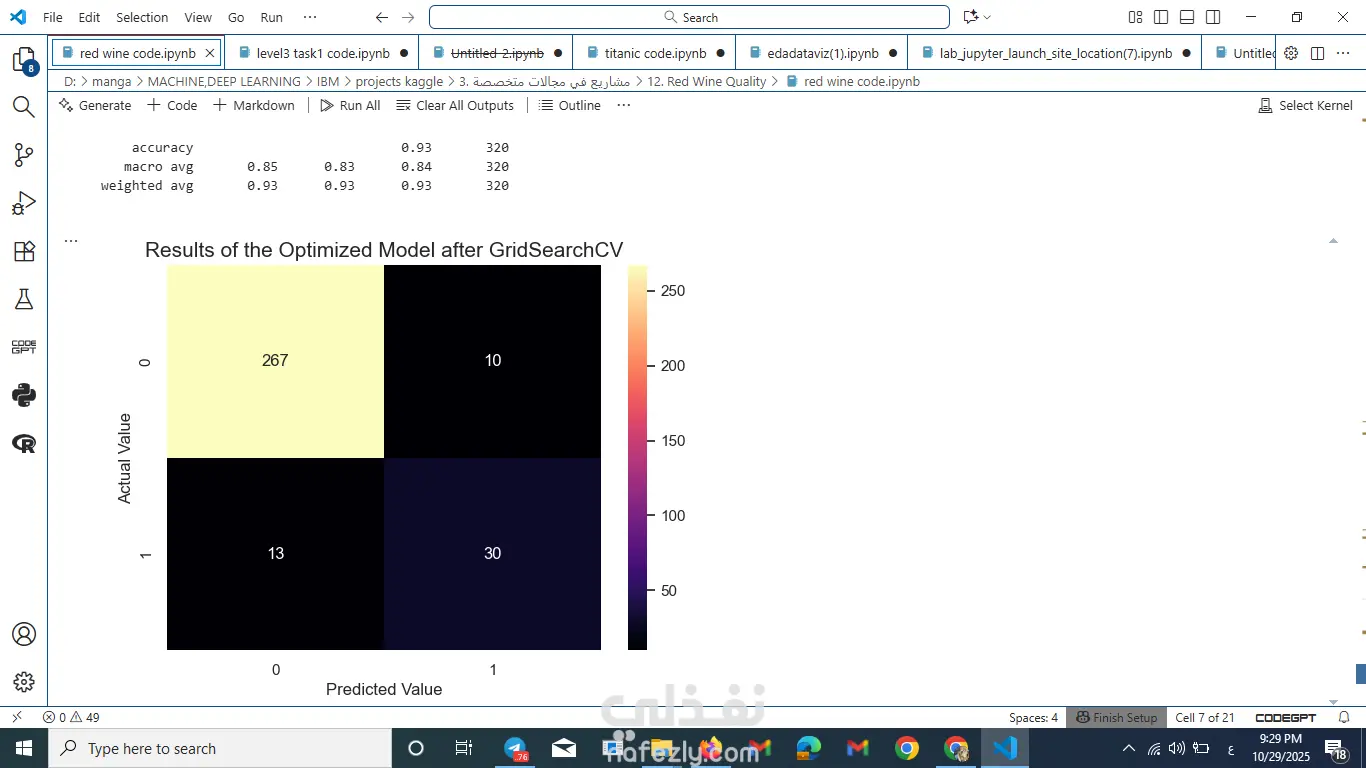
استخدمت GridSearchCV عشان أختار أفضل إعداد للنموذج.
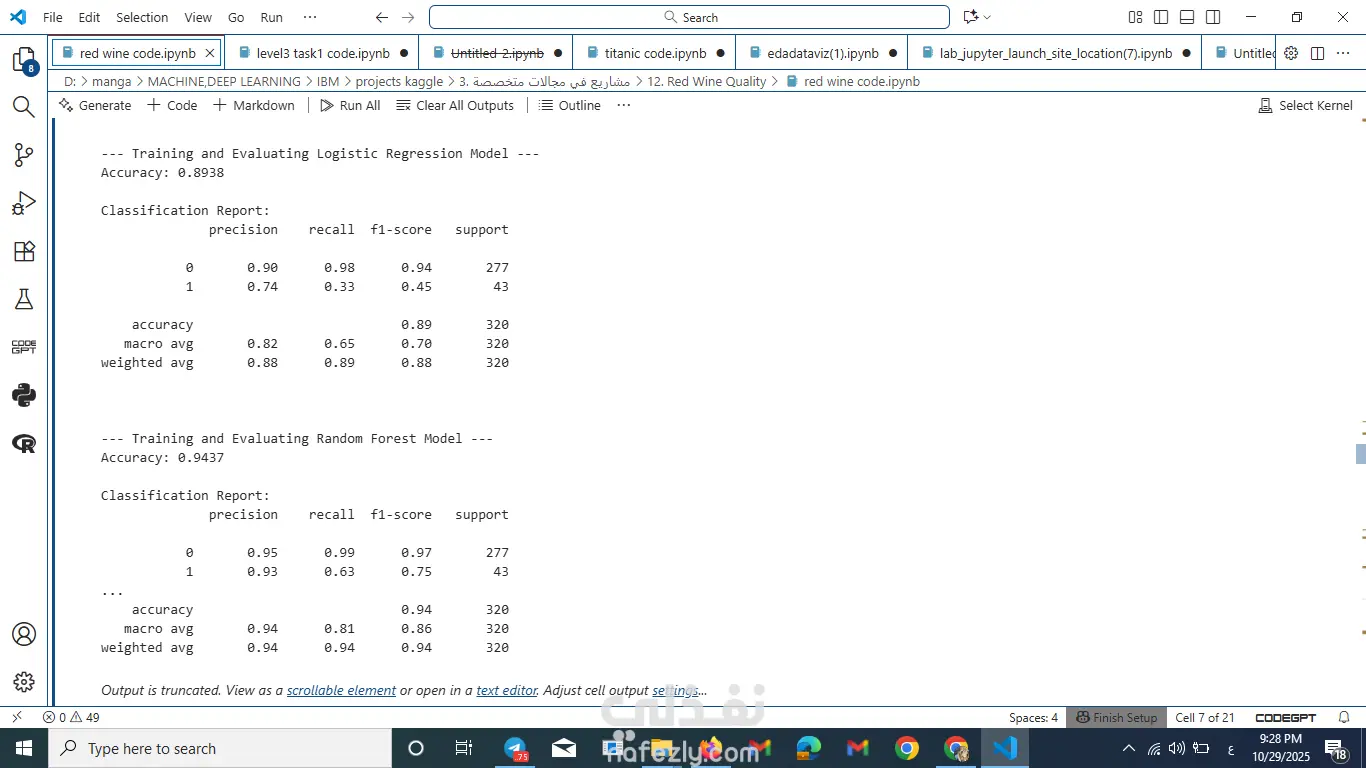
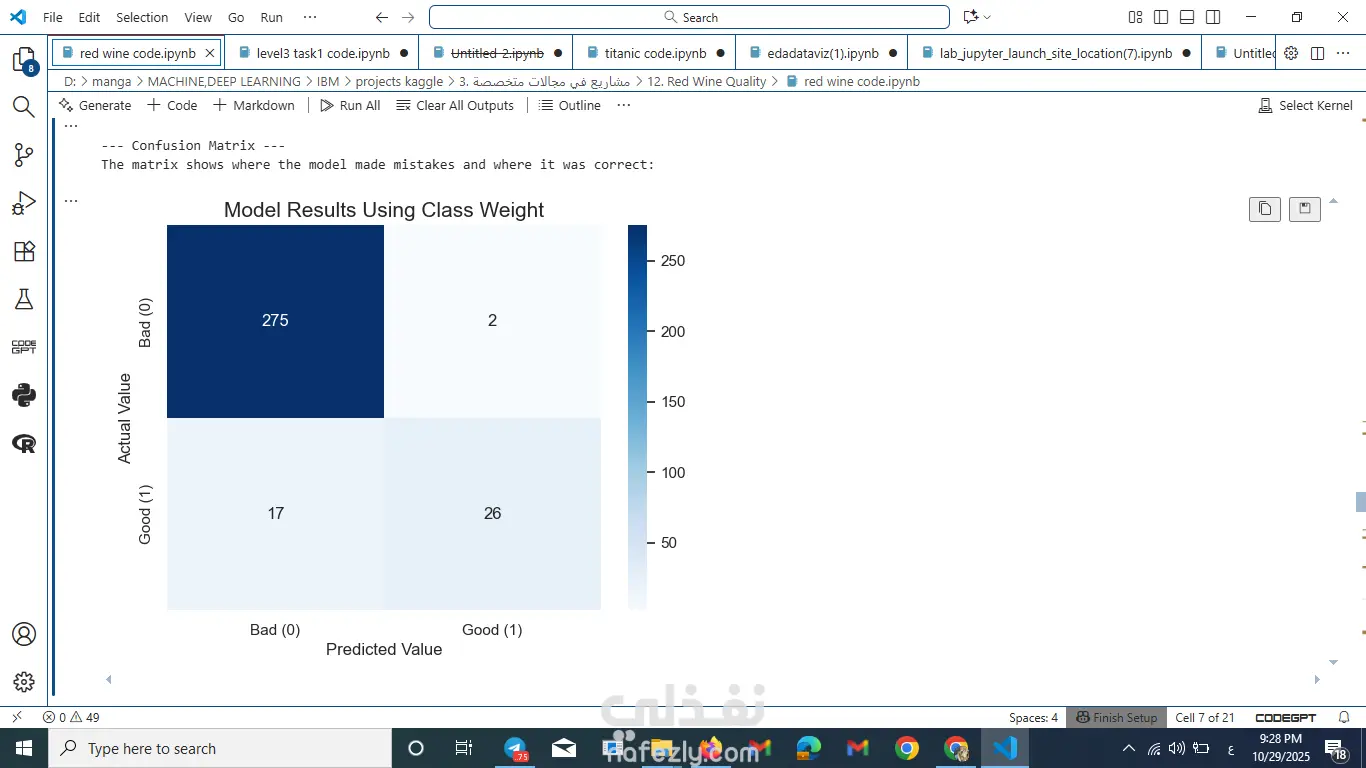
في النهاية كان Random Forest هو الأفضل في الدقة وتوازن النتائج.
🔹 5: عرض النتائج
النموذج قدر يتنبأ بجودة النبيذ بدقة عالية.
العوامل الأكثر تأثيرًا كانت: نسبة الكحول، السلفات، والحموضة المتطايرة.
🧠 الأدوات اللي استخدمتها:
Python – Pandas – NumPy – Matplotlib – Seaborn – Plotly – Scikit-learn
مستعدة أطبق نفس العملية باحترافية في مشروعك القادم!