التعبئة التلقائية لبيانات باستخدام الذكاء الاصطناعي (LLM)
تفاصيل العمل
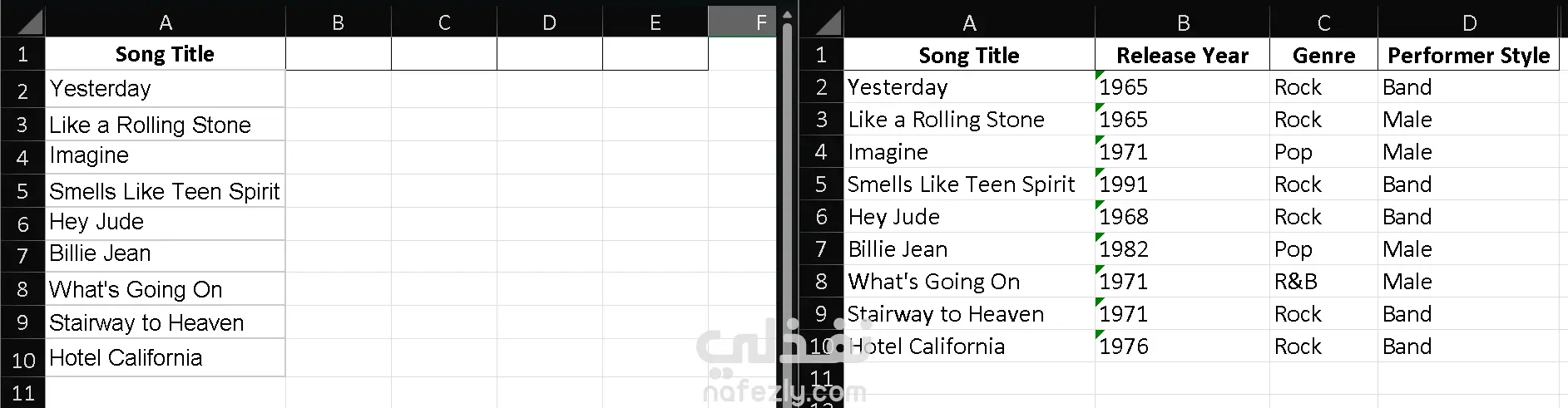
يركز هذا المشروع على استغلال قوة النماذج اللغوية الكبيرة (LLMs) لأتمتة عملية إثراء البيانات الوصفية للموسيقى. الهدف الأساسي هو تطوير نظام قادر على أخذ عنوان الأغنية كمدخل وحيد، ومن ثم توليد أو استرجاع مجموعة من المعلومات الإضافية الهامة المتعلقة بها. آلية العمل: يقوم النموذج اللغوي الكبير بتحليل عنوان الأغنية المقدم له، وباستخدام معرفته الواسعة المكتسبة من تدريبه على كميات هائلة من النصوص والبيانات، يستنتج أو يبحث عن تفاصيل مثل: - سنة الإصدار - النوع الموسيقي (Genre) - أسلوب المؤدي أو الفرقة (Performer Style) - معلومات أخرى قد تكون متاحة (مثل الألبوم، الفنان، إلخ، حسب قدرة النموذج وتوفر البيانات). الفائدة: يُعد هذا المشروع حلاً فعالاً للمشكلات المتعلقة بنقص البيانات في المكتبات الموسيقية الرقمية أو قواعد البيانات. فبدلاً من إدخال هذه المعلومات يدويًا لكل أغنية، وهو أمر شاق ويستغرق وقتًا طويلاً، يقوم النظام بأتمتة هذه العملية، محولاً قائمة بسيطة من العناوين (كما في الجانب الأيسر من الصورة المصغرة) إلى جدول بيانات غني ومفصل (كما في الجانب الأيمن). هذا يساهم في تحسين تنظيم المحتوى الموسيقي، وتسهيل عمليات البحث والتصنيف، وتقديم تجربة أفضل للمستخدم.
مهارات العمل
بطاقة العمل

طلب عمل مماثل













