adult-income-ml-accuracy-95
تفاصيل العمل
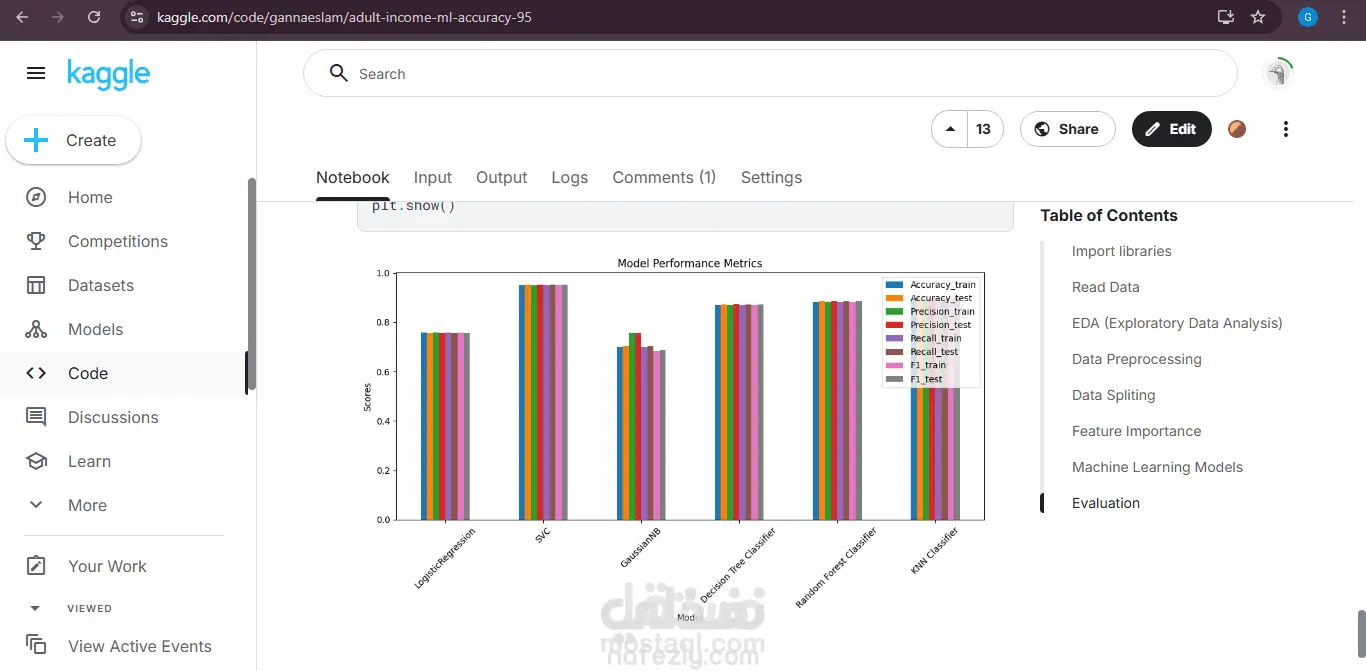
مشروع تعلم الآلة لتصنيف الدخل (≤50K أو >50K) باستخدام مجموعة بيانات Adult Income التي تحتوي على 48,842 سجلًا و15 ميزة. هذه المجموعة من البيانات الواقعية تضمن تطبيقًا عمليًا للمشروع. يستخدم المشروع مكتبات Pandas و NumPy و Matplotlib و Seaborn و Scikit-learn للتحليل وبناء النماذج. إتقان هذه المكتبات القياسية في بايثون يعزز من المصداقية التقنية. يتم تحميل البيانات بصيغة CSV، والتي تحتوي على ميزات رقمية (مثل العمر) وأخرى تصنيفية (مثل المهنة)، مما يُظهر القدرة على التعامل مع أنواع بيانات متنوعة. يتم إجراء التحليل الاستكشافي للبيانات (EDA) باستخدام أوامر مثل df.head() لمعاينة البيانات، والتحقق من الأبعاد (48,842×15)، واستعراض معلومات الأعمدة باستخدام df.info(). هذا الفهم العميق للبيانات يُحسن من جودة مرحلة الإعداد المسبق. تتضمن مرحلة المعالجة المسبقة التعامل مع القيم المفقودة (الممثلة بالرمز “?”)، وترميز البيانات التصنيفية، وتطبيع القيم باستخدام StandardScaler. هذه الخطوات الشاملة في المعالجة المسبقة تساهم في تحسين أداء النماذج. يتم بناء نماذج باستخدام خوارزميات متعددة مثل: الانحدار اللوجستي (Logistic Regression)، شجرة القرار (Decision Tree)، الغابة العشوائية (Random Forest)، آلة المتجهات الداعمة (SVM)، نايف بايز (Naive Bayes)، و KNN، مع تقسيم البيانات إلى مجموعة تدريب واختبار. تنوع الخوارزميات يعكس مرونة الباحث في اختيار النماذج المناسبة. يتم تقييم النماذج باستخدام مقاييس متعددة مثل الدقة (Accuracy) والدقة النوعية (Precision) والاسترجاع (Recall) ومعدل F1، مما يضمن اختيار النموذج الأمثل بناءً على أكثر من معيار واحد. حقق المشروع دقة تقارب 95%، وهو ما يشير إلى أداء قوي للغاية. هذه النتيجة المرتفعة تجعل المشروع مميزًا ومناسبًا لتطبيقات تصنيف البيانات الواقعية.
مهارات العمل














