Telco Customer Churn Prediction Churn Analysis Project (classification model)
تفاصيل العمل
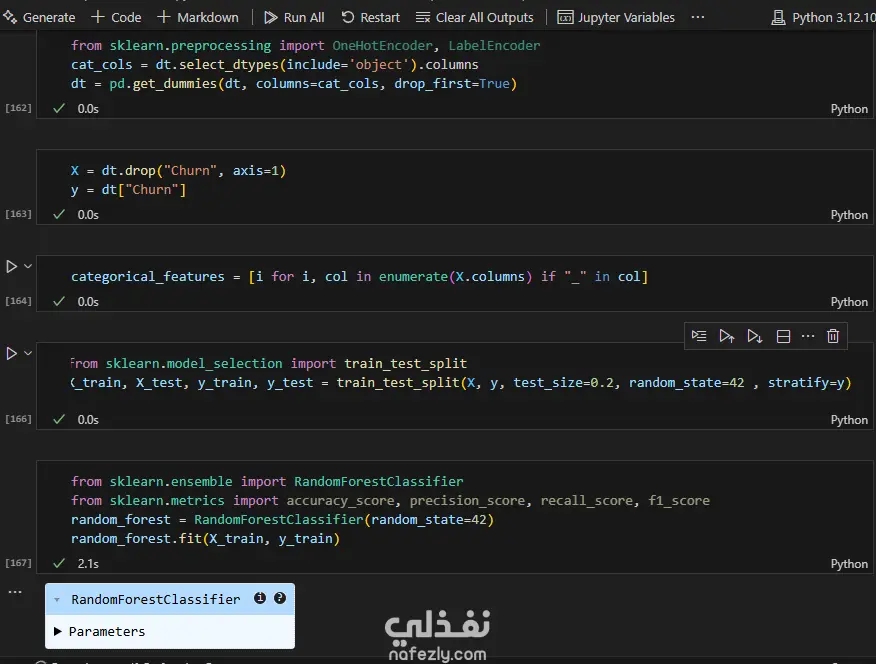
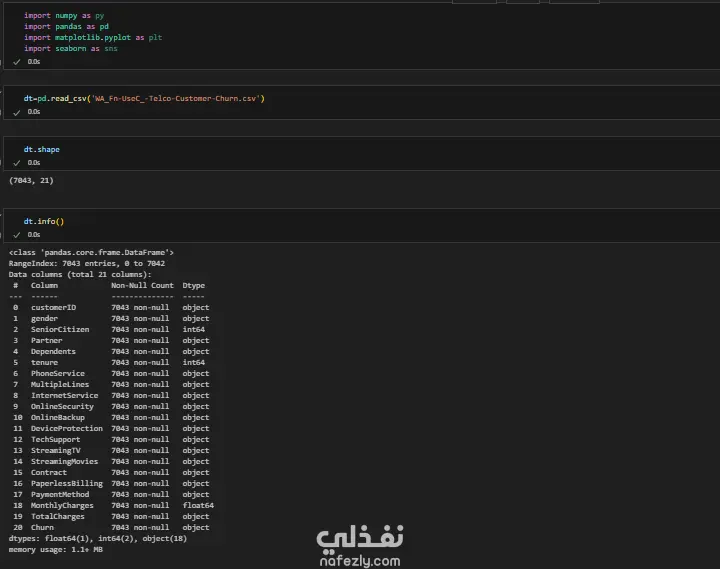
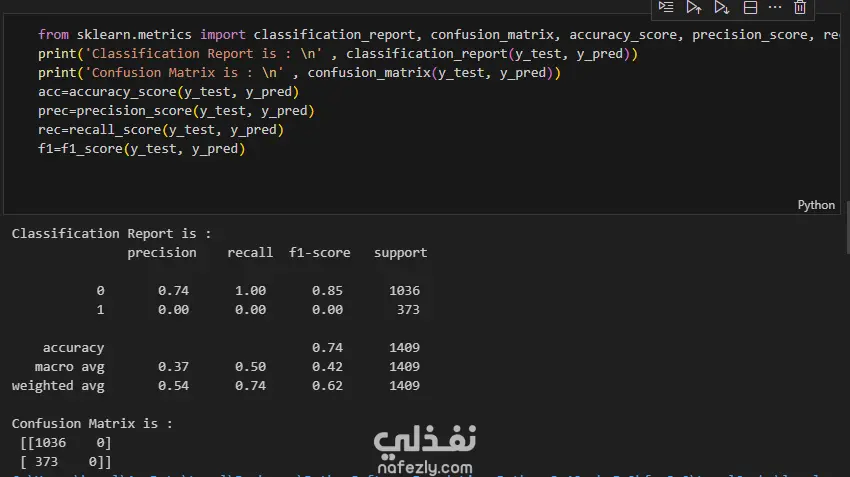
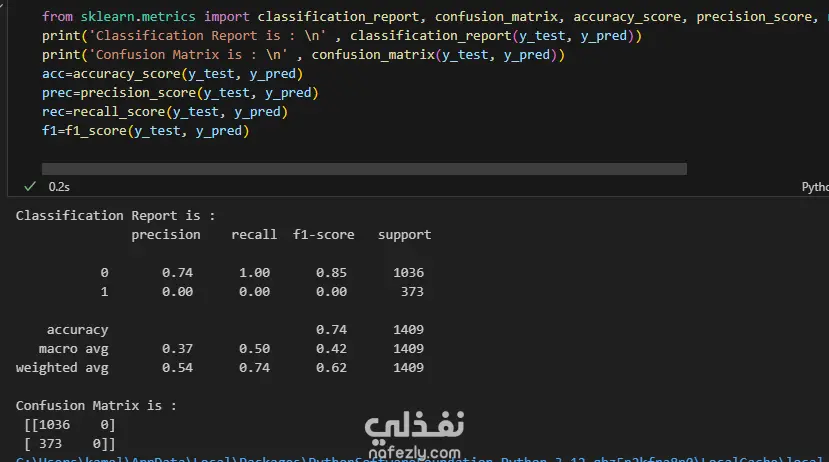
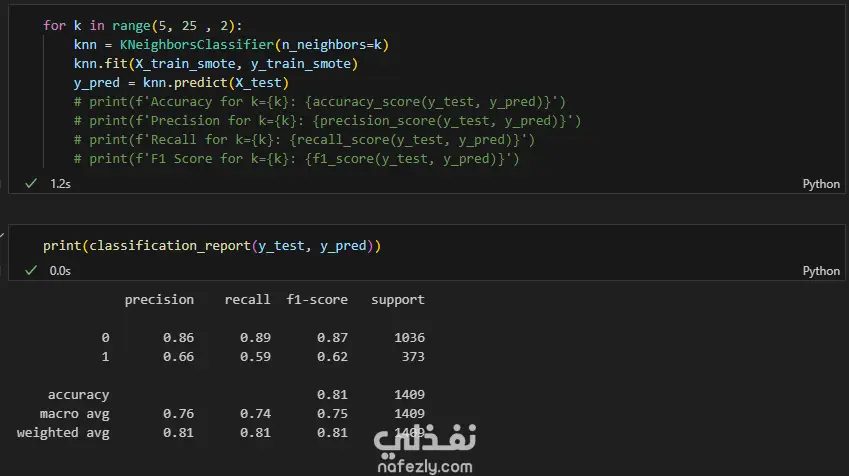
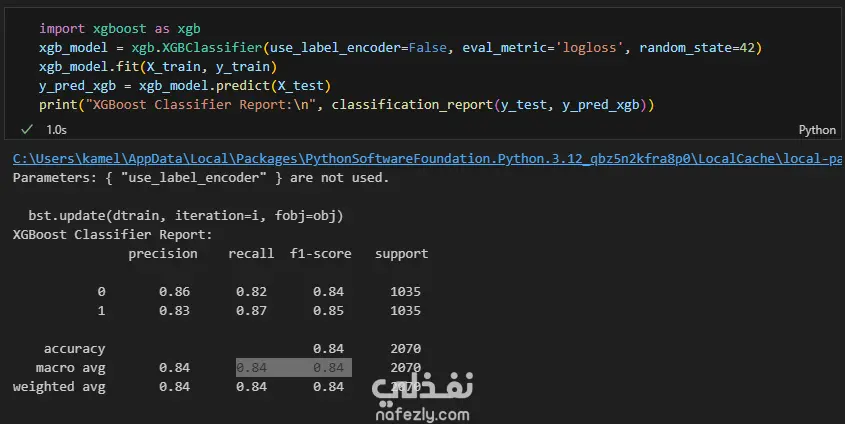
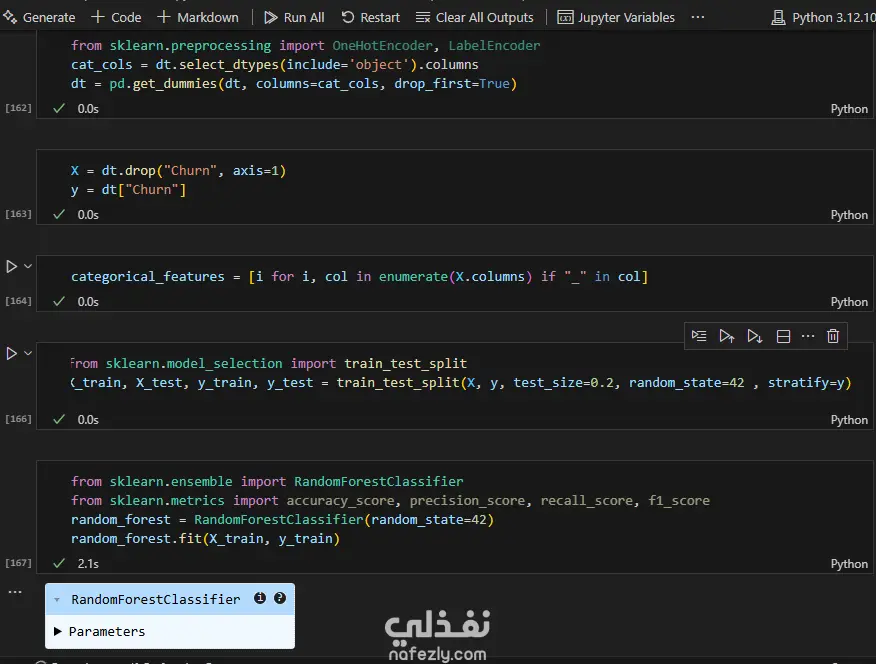
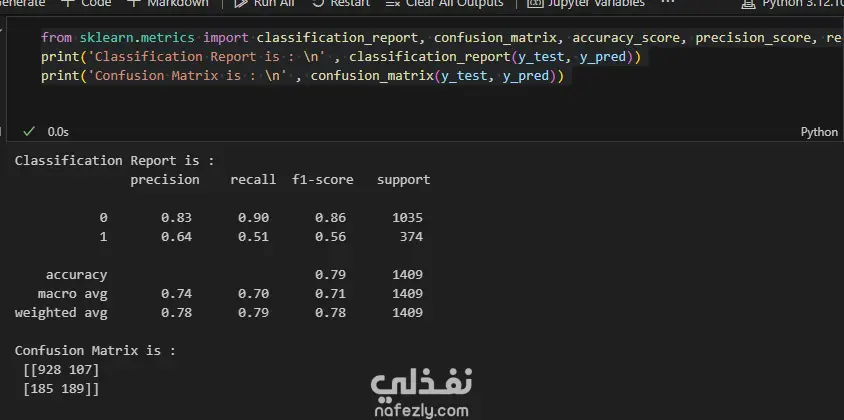
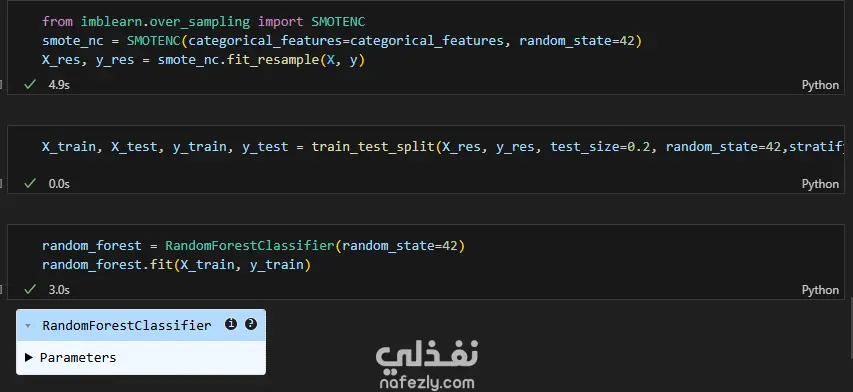
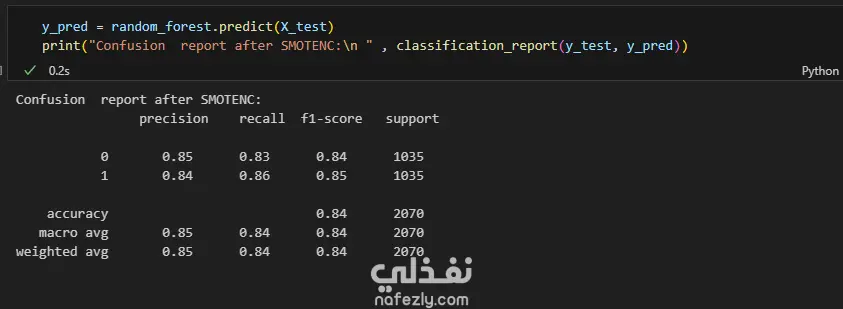
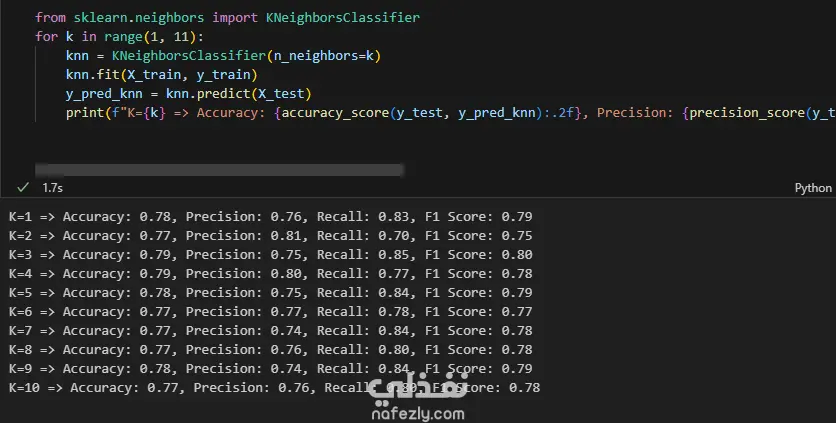
Data Exploration and Preprocessing I began with a dataset of 7,043 customer records and 21 features. My preprocessing workflow included several key steps: Data Cleaning: I identified and handled missing values in the TotalCharges column, filling 11 empty entries with the column's median value to maintain data integrity. Feature Engineering: The customerID column was dropped as it provided no predictive value. Data Transformation: I converted binary categorical columns like Partner, Dependents, and Churn into numerical format (0s and 1s). All remaining object-type columns were transformed into numerical data using one-hot encoding. Initial Model and Performance My initial model was a Random Forest Classifier. While it performed reasonably well, the evaluation revealed a significant issue with class imbalance. The model struggled to correctly identify customers who would actually churn (the minority class), achieving a recall of only 0.51 for "Class 1". This meant it was missing almost half of the customers who were about to leave. Model Improvement: Tackling Class Imbalance To address this, I implemented the SMOTENC (Synthetic Minority Over-sampling Technique for Nominal and Continuous features) algorithm. This technique balances the dataset by generating synthetic samples for the minority class (churned customers). After applying SMOTENC and retraining the Random Forest model on the newly balanced data, the results improved dramatically. The recall for "Class 1" jumped from 0.51 to 0.86, and the F1-score increased from 0.56 to 0.85. Final Model Comparison and Results To ensure the best possible performance, I trained and evaluated several other classification algorithms on the balanced dataset: Decision Tree Classifier: Achieved an overall F1-score of 0.80. K-Nearest Neighbors (KNN): Tested with K values from 1 to 10, showing consistent performance. Support Vector Machine (SVM): Resulted in a macro average F1-score of 0.68. XGBoost Classifier: This model emerged as one of the top performers, delivering a robust F1-score of 0.85 for the churn class and an overall accuracy of 84%. Both the Random Forest and XGBoost models, after balancing the data with SMOTENC, proved to be highly effective for this prediction task. This project highlights the critical importance of preprocessing and handling class imbalance to build truly useful machine learning models.
مهارات العمل















