🚀 I’ve just completed a new Data Engineering task as part of my training journey!
The scenario was working as a Data Engineer in one of the biggest markets in Egypt, where the data sources were:
🛒 Products stored in a JSON file (id, name, price)
📊 Transactions stored in multiple CSV files (1,000 transactions per file → starting with 12,000 transactions = 3 days of data)
👥 Customers stored in a SQL Server database table (2,000 customers)
📌 My task was to build and manage an Orders table:
(transaction_id, product_name, amount, customer_full_name, transaction_date, branch)
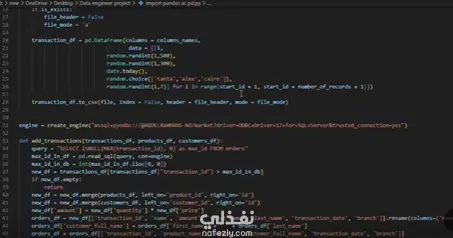
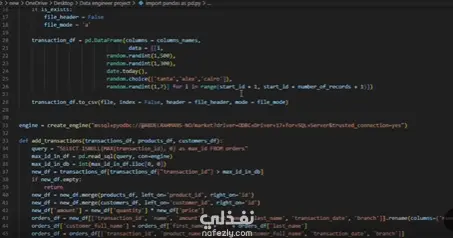
Key steps I implemented:
1️⃣ Initial Load → Inserted the first 12,000 transactions into the Orders table.
2️⃣ Delta Load → Inserted the new day’s transactions (incremental insert).
3️⃣ Product Price Update → Applied changes to reflect the updated product price in the Orders table using an UPDATE statement.
4️⃣ Change Data Capture (CDC) → On day 3, transaction files included both modified old transactions and new ones. I used a MERGE statement to update existing records and insert new ones.
Skills gained & applied:
✅ ETL processes using Pandas & SQL Server
✅ Data integration from JSON, CSV, and SQL DB
✅ Handling incremental & CDC scenarios in real-world datasets