استخراج وجمع البيانات (Web Scraping) من المواقع

تفاصيل العمل
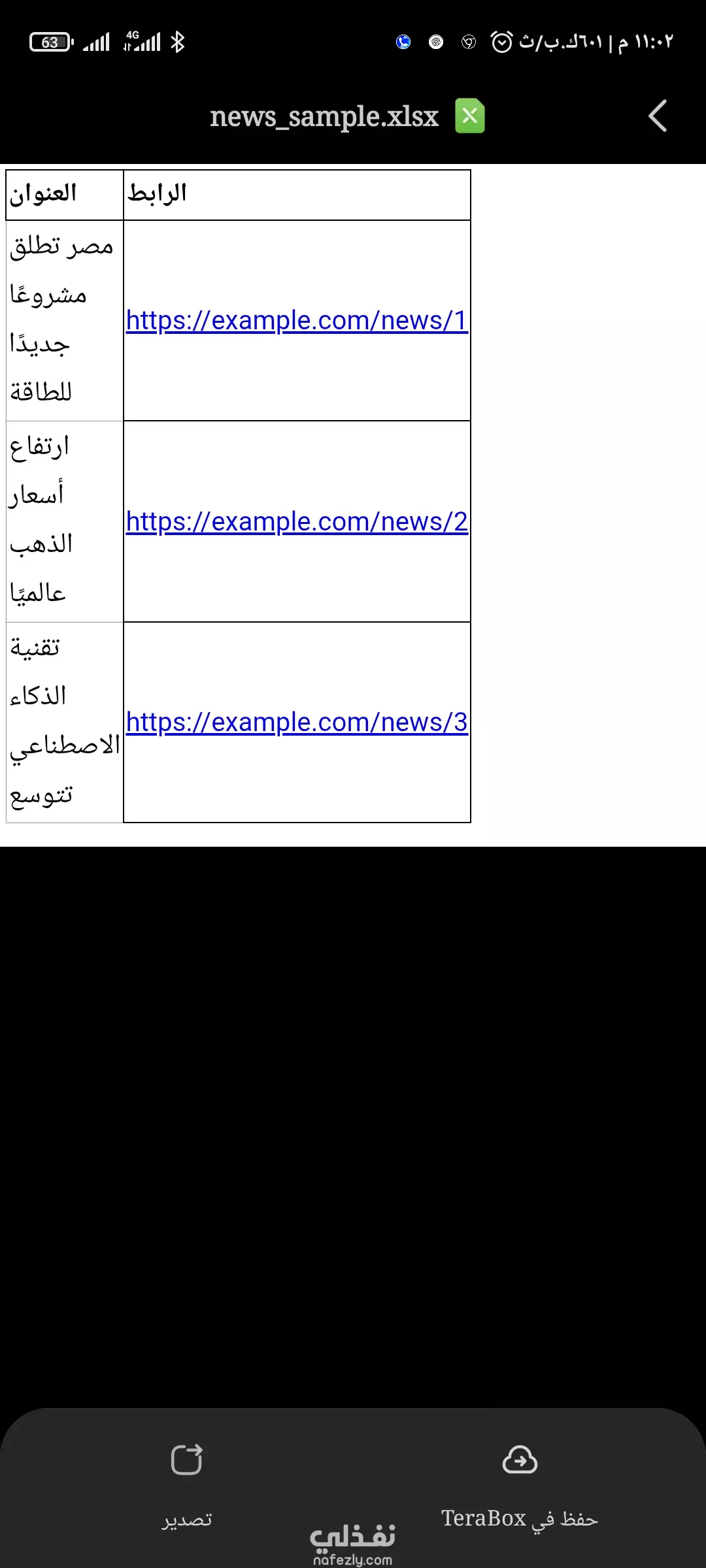
أوفر لك خدمة Web Scraping لالتقاط أي بيانات من المواقع (أسعار، منتجات، مقالات، قوائم شركات…) وتنظيمها في ملفات Excel/CSV أو قواعد بيانات. باستخدام Python (BeautifulSoup, Scrapy, Selenium) أضمن لك سرعة ودقة في جمع البيانات + مرونة في الصيغ المطلوبة. 💰 الأسعار: من 25$ لموقع صغير حتى 100$ لمشاريع احترافية تشمل عدة مواقع + تسليم الكود مثال عينة Web Scraping الفكرة: استخراج آخر الأخبار من موقع إخباري (مثال: عناوين + روابط). 📂 النتيجة (ملف CSV أو Excel): العنوان الرابط مصر تطلق مشروعًا جديدًا للطاقة https://example.com/news/1 ارتفاع أسعار الذهب عالميًا https://example.com/news/2 تقنية الذكاء الاصطناعي تتوسع https://example.com/news/3 --- 💻 مثال كود import requests from bs4 import BeautifulSoup import pandas as pd url = "https://example.com/news" res = requests.get(url) soup = BeautifulSoup(res.text, "html.parser") titles = [] links = [] for item in soup.select(".news-title a"): titles.append(item.text.strip()) links.append(item['href']) df = pd.DataFrame({"العنوان": titles, "الرابط": links}) df.to_excel("news_sample.xlsx", index=False) --- 📌 ملاحظات للعميل: دي مجرد عينة بسيطة على الأخبار. أقدر أطبق نفس الفكرة على أي موقع (متاجر، شركات، مقالات، منتجات…). التسليم بيكون ملف Excel/CSV منظم وجاهز للاستخدام.
مهارات العمل
بطاقة العمل

طلب عمل مماثل












