📄 Automated PDF Data Extraction

تفاصيل العمل
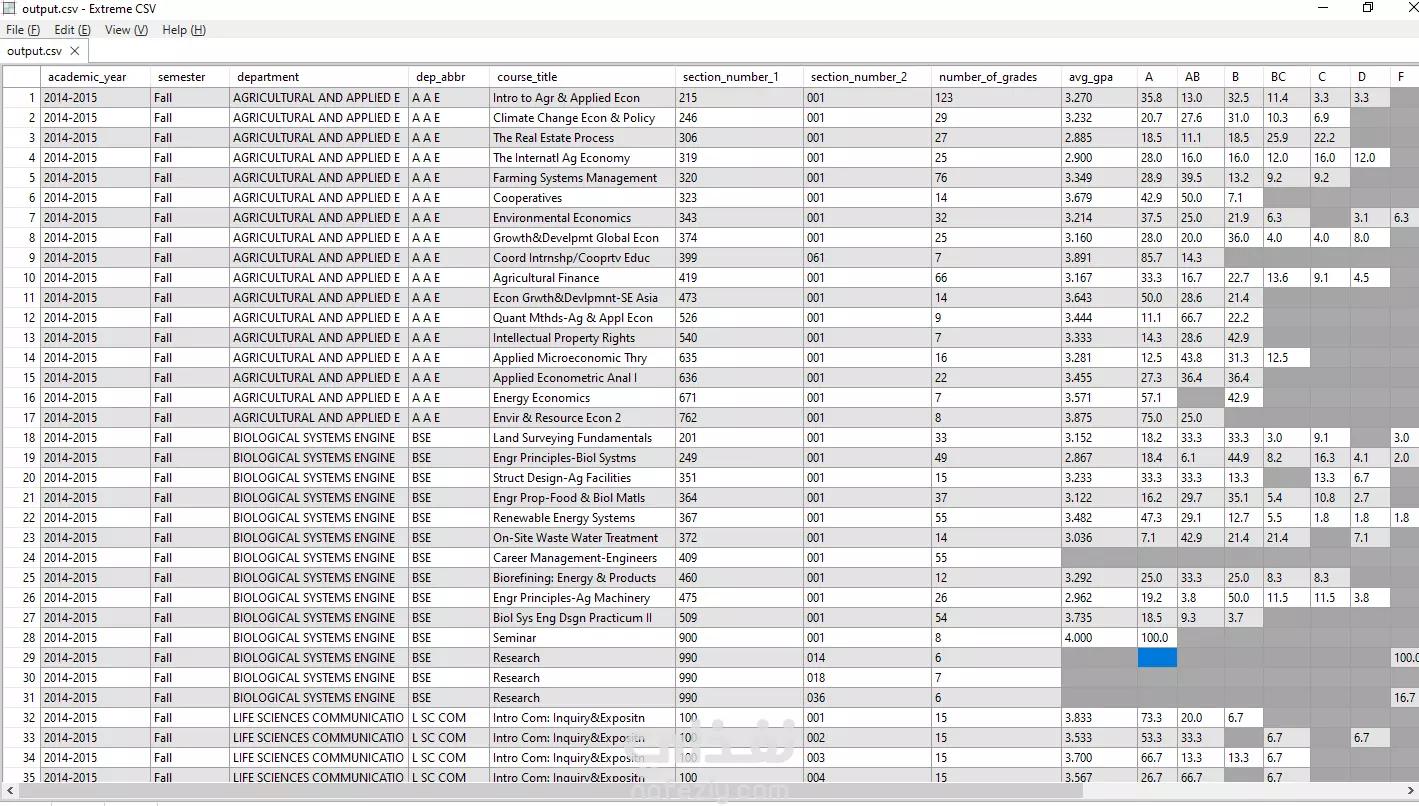
📄 Automated PDF Data Extraction جالي عميل عنده مشكلة كبيرة: كان محتاج يستخرج بيانات من 20 ملف PDF، كل ملف حوالي 400 صفحة (يعني أكتر من 8,000 صفحة إجمالًا). العملية يدويًا كانت هتاخد أسابيع ومجهود ضخم جدًا، غير إنها معرضة للأخطاء. أنا بدأت أدرس طبيعة الملفات، ولاحظت إن الجودة ضعيفة والتنسيق غير ثابت. هنا كانت التحدي: إزاي أعمل نظام يقدر يتعامل مع الوضع ده ويطلع نتائج دقيقة. ✦ الحل اللي نفذته طورت سكريبت ذكي باستخدام Python قدر يقرأ ويحلل الملفات بشكل آلي بدقة وصلت لـ 95%، واعتمدت فيه على: • pdfplumber لاستخراج النصوص من الـ PDF. • Regex للتعرف على الأنماط وتنظيم البيانات. • CSV لتجهيز البيانات بشكل منظم وسهل التحليل. • tqdm لمتابعة تقدم العملية مع الملفات الكبيرة. 🚀 النتائج • قدرت أعالج 8,000+ صفحة في أقل من 15 دقيقة بدل أسابيع يدويًا. • استخرجت أكتر من 50,000 سجل منظم (السنة الدراسية، الترم، القسم، المعدل، الدرجات...). • دقة 95% بالرغم من ضعف جودة الملفات وعدم انتظام التنسيق. • وفرنا أكتر من 98% من الوقت مقارنة بالشغل اليدوي. • النتيجة النهائية كانت CSV نظيف وجاهز للتحليل من غير أي تدخل يدوي. 🎯 القيمة للعميل • وفرت عليه آلاف الساعات من الشغل اليدوي. • مكنته يعمل تقارير وتحليلات فورية مباشرة من البيانات المصدرة. • ضمنت إن البيانات متسقة وصحيحة. • الحل كان مرن وقابل لإعادة الاستخدام مع مئات الملفات المشابهة بسهولة.
مهارات العمل
بطاقة العمل

طلب عمل مماثل











