تحليل بيانات طلبات Uber - مشروع علم بيانات باستخدام بايثون | Uber Ride Requests Analysis and Clustering

تفاصيل العمل
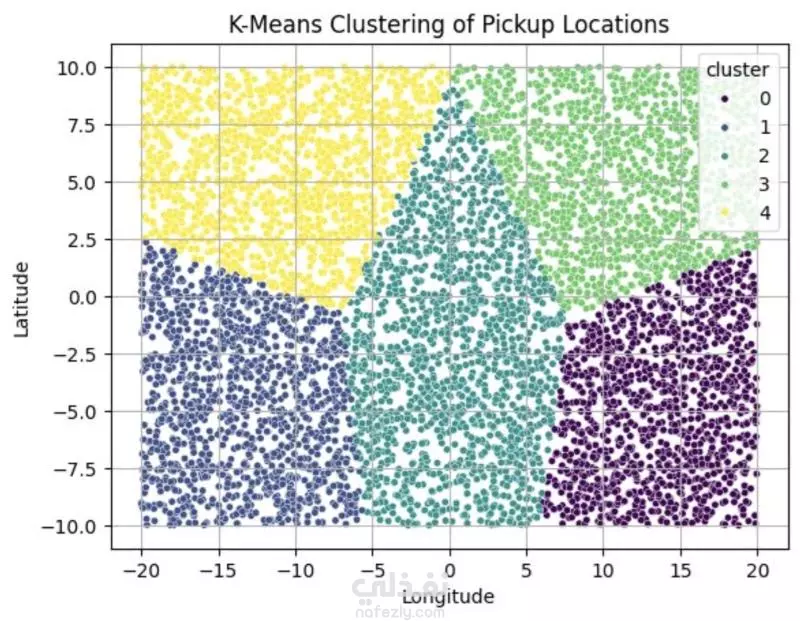
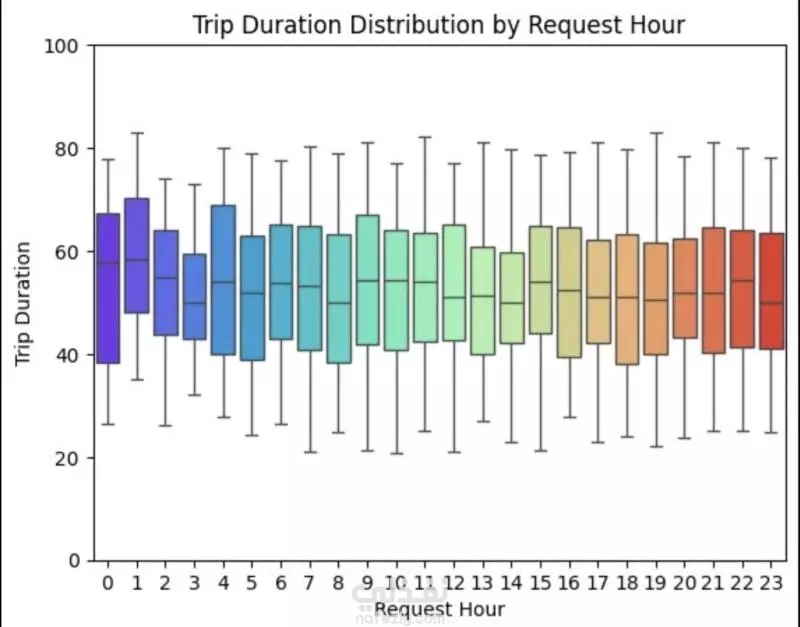
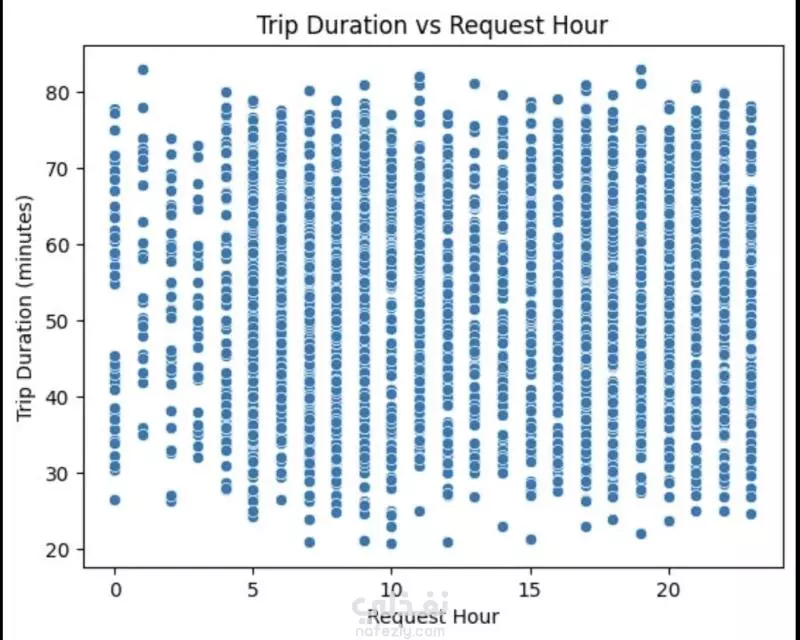
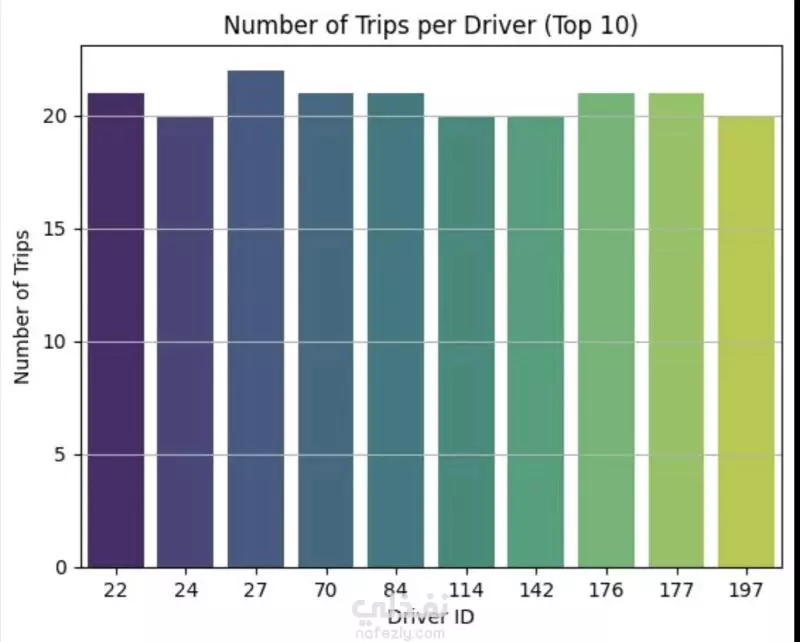
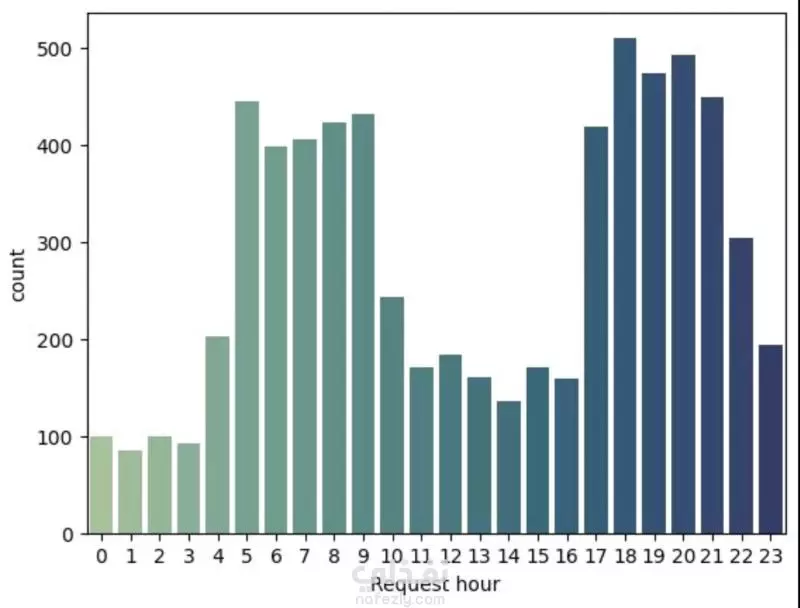
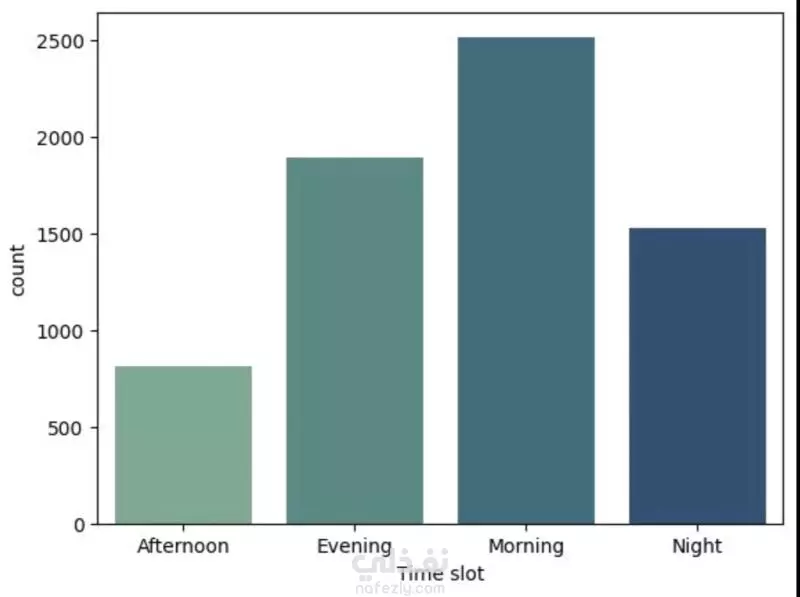
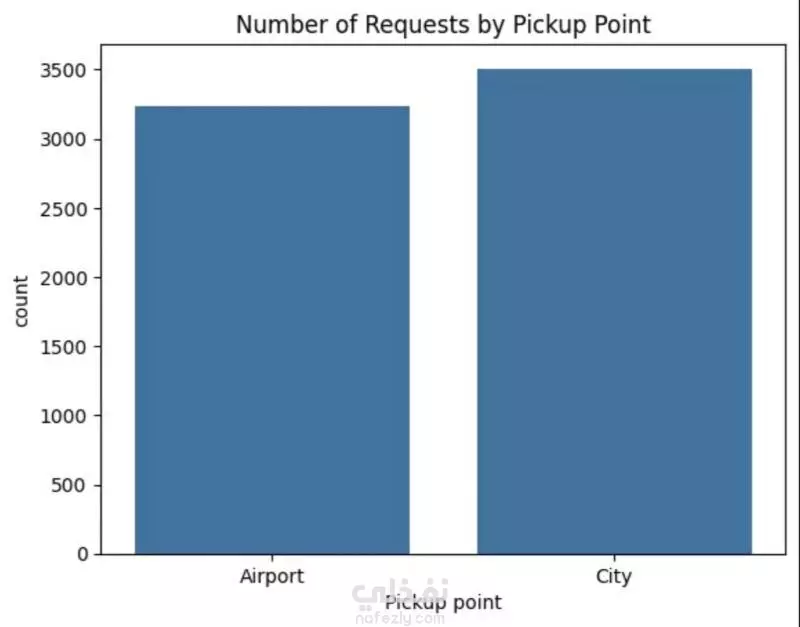
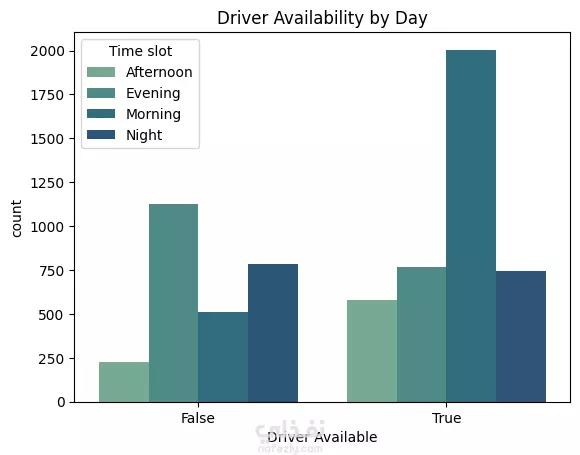
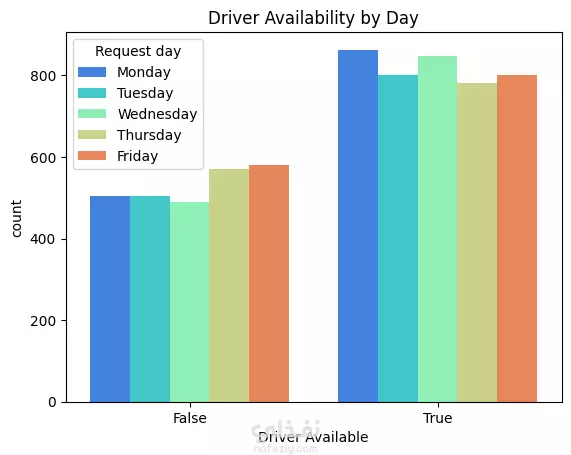
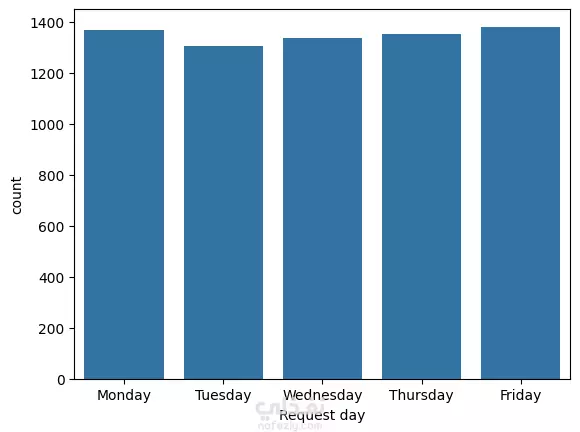
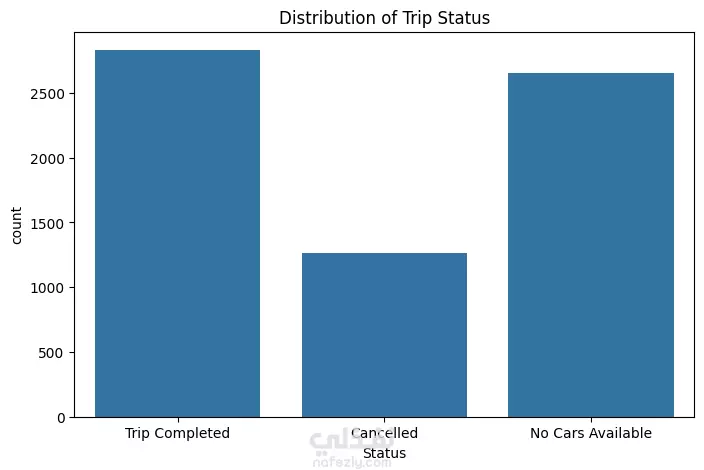
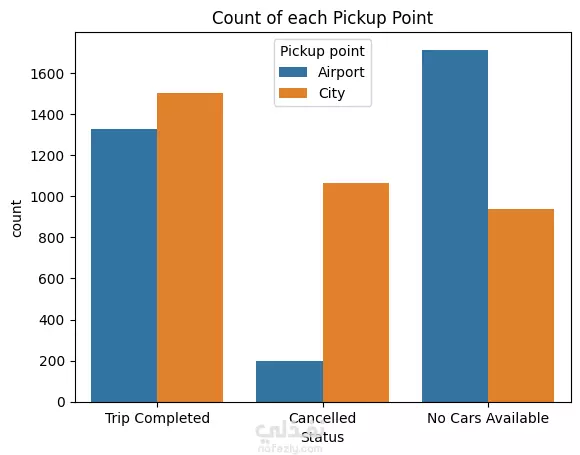
نبذة عن المشروع مشروع علم بيانات شامل يهدف إلى تحليل بيانات طلبات ركوب Uber الحقيقية للكشف عن أنماط الطلب وسلوك السائقين باستخدام لغة Python. يشمل المشروع مراحل تنظيف البيانات، توليد الميزات، التصور البياني، والتجميع العنقودي (Clustering) باستخدام خوارزمية K-Means. ---------------------------------------- أهداف المشروع تحليل أنماط الطلب خلال اليوم والأسبوع فهم فترات الخمول لدى السائقين رصد مشكلات الإلغاء ونقص السيارات تقسيم مناطق التشغيل باستخدام التجميع الجغرافي ----------------------------------- سير العمل: # تنظيف البيانات - تحويل وتوحيد صيغ التاريخ والوقت (طلب وتوصيل) - معالجة القيم المفقودة بدون إسقاط البيانات الهامة - تنسيق القيم الفئوية مثل "الحالة" و"نقطة الالتقاط" # توليد الميزات (Feature Engineering) - استخراج ميزات زمنية مثل ساعة الطلب ويوم الأسبوع - حساب مدة الرحلة بدقائق - تصنيف الأوقات إلى (صباح - عصر - مساء - ليل) - توليد مؤشرات منطقية مثل: هل السائق متاح؟ هل الرحلة مكتملة؟ # التصور البياني (Visualization) - عرض ذكي لنقاط الذروة في الطلب وفترات خمول السائقين - تحليل الاتجاهات حسب الوقت والمكان - فهم أنماط الإلغاء ومعدلات الإكمال # التجميع المكاني (K-Means Clustering) - محاكاة إحداثيات الالتقاط وتقسيم المدينة إلى 5 مناطق تشغيل - تمثيل بصري للمناطق عالية الطلب مقابل المناطق الراكدة ------------------------------ أهم النتائج الطلب الأعلى: بين الساعة 5-9 مساءً، مع توفر أقل للسائقين الخمول الأعلى للسائقين: يوم الجمعة، رغم ارتفاع الطلب مدة الرحلات: الأطول تكون بين 12–4 صباحًا أنماط الالتقاط: معظم الطلبات من داخل المدينة، بينما المطار يشهد نقصًا في السيارات أفضل السائقين: أكملوا عدد رحلات متقارب (20–22) --------------------------------- مكونات المشروع Uber-Trip-Analysis/ │ ├── data/ ← ملف البيانات الخام │ └── Uber Request Data.csv ├── output/ ← البيانات بعد المعالجة والنتائج │ └── Uber with features.csv ├── src/ ← جميع الملفات البرمجية المنظمة │ ├── data_loading_and_exploration.py │ ├── data_cleaning_and_preprocessing.py │ ├── data_feature_engineering.py │ ├── data_visualization.py │ ├── location_clustering.py │ └── save_transformed_data.py ├── main.py ← ملف التشغيل الرئيسي ├── requirements.txt ← مكتبات Python المستخدمة └── README.md ← مستند توثيق المشروع ---------------------------------- مواصفات البيانات عدد الصفوف: 6,745 عدد الأعمدة: 6 تنسيق الملف: TSV (قيم مفصولة بعلامة تبويب) الأعمدة الأساسية: Request id Pickup point Driver id Status Request timestamp Drop timestamp -------------------------- التقنيات والأدوات Python 3.10+ pandas, numpy, matplotlib, seaborn scikit-learn (KMeans) dateutil (لتحليل الوقت) --------------------------------------------- تشغيل المشروع pip install -r requirements.txt python main.py
مهارات العمل
بطاقة العمل

طلب عمل مماثل












