تحليل وتصور بيانات زهور السوسن (Iris Dataset) باستخدام Python وMachine Learning

تفاصيل العمل
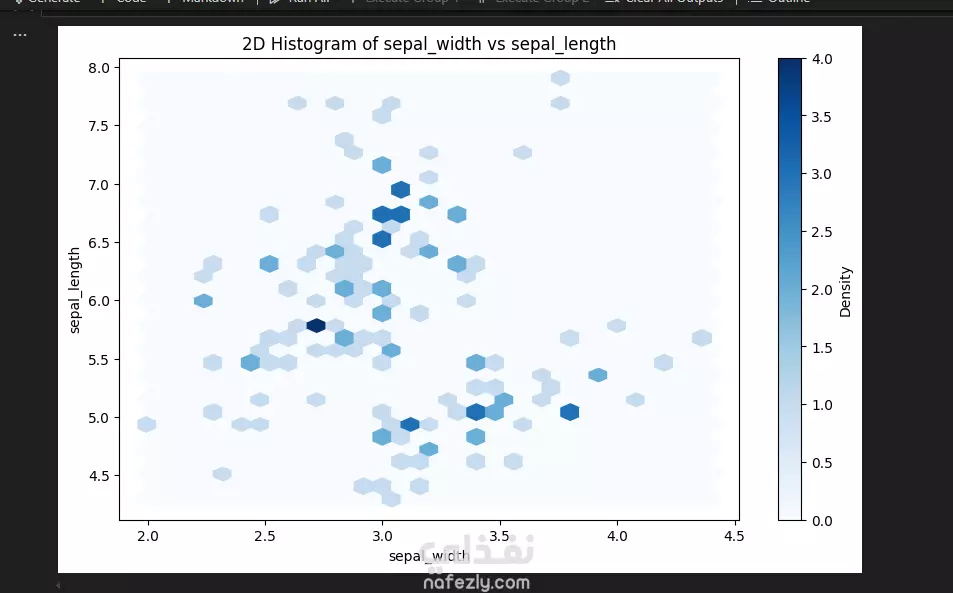
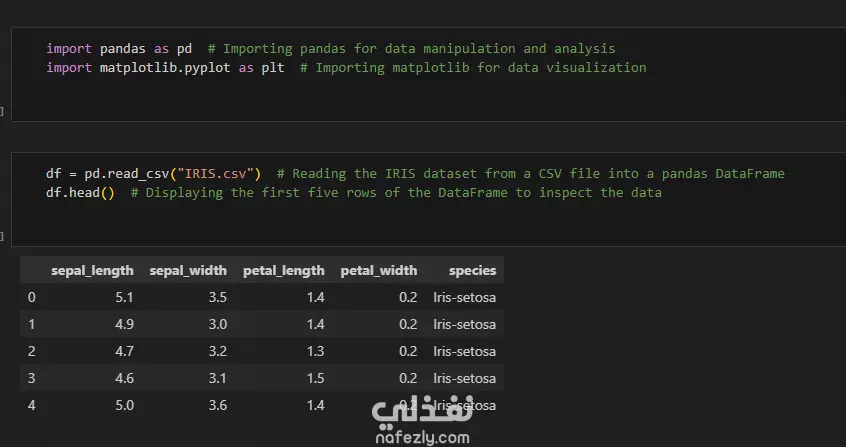
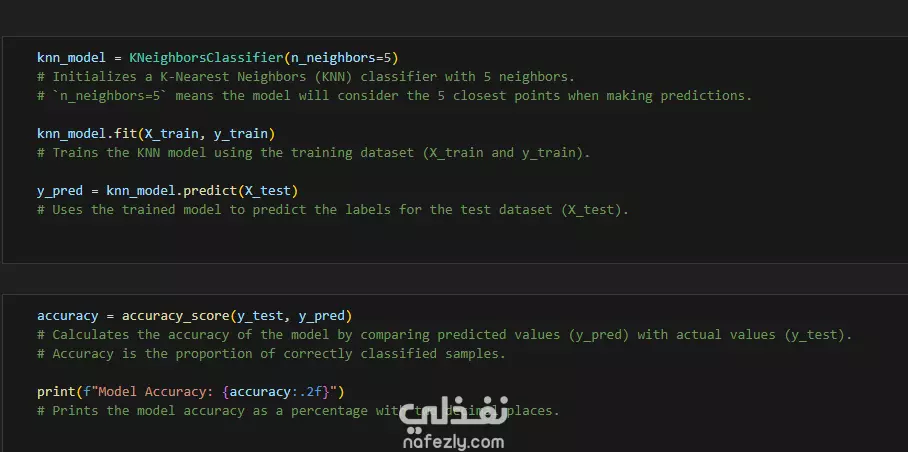
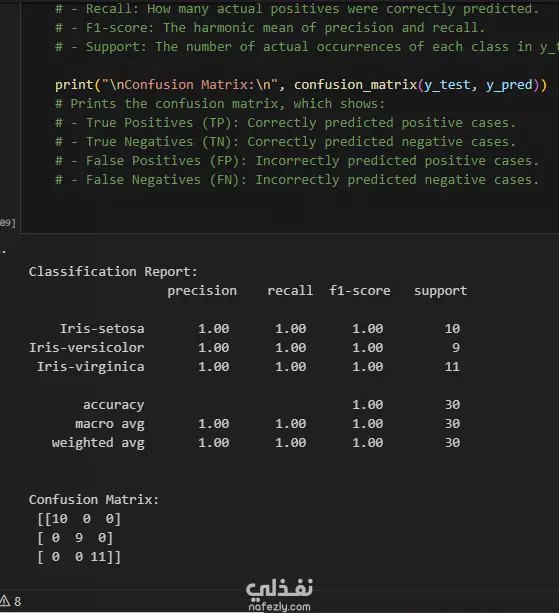
في هذا العمل، قمت بتحليل مجموعة بيانات زهور السوسن (Iris Flower Dataset)، وهي واحدة من أشهر مجموعات البيانات في مجال تعلم الآلة وتحليل البيانات. خطوات التنفيذ كانت كالتالي: استكشاف وتحليل البيانات (EDA): قمت بفحص الخصائص الأساسية للبيانات، مثل طول وعرض البتلة (Petal) والكأس (Sepal)، لكل نوع من الأنواع الثلاثة: Setosa، Versicolor، وVirginica. تنظيف وتجهيز البيانات: تأكدت من خلو البيانات من القيم المفقودة أو المتطرفة، وتجهيزها للتحليل والنمذجة. تصور البيانات: استخدمت مكتبات Seaborn وMatplotlib لإنشاء رسوم بيانية تفاعلية مثل: Pairplot لمقارنة السمات المختلفة. Heatmap للمصفوفة الارتباطية بين الخصائص. Boxplots وViolin plots لتوضيح التوزيعات والاختلافات بين الأنواع. تصنيف الأنواع باستخدام التعلم الآلي: قمت ببناء واختبار أكثر من نموذج باستخدام: Logistic Regression K-Nearest Neighbors (KNN) Decision Tree مع مقارنة أداء النماذج باستخدام دقة التصنيف (Accuracy). النتائج: نجحت النماذج في تصنيف أنواع الزهور بدقة عالية، وتم توضيح أهمية كل سمة في عملية التصنيف من خلال الرسوم التوضيحية. هذا النوع من التحليل يساهم في توضيح المبادئ الأساسية لتعلم الآلة.
مهارات العمل
بطاقة العمل

طلب عمل مماثل











