استخراج افضل 250 فلم على حسب تقييم IMDB
تفاصيل العمل
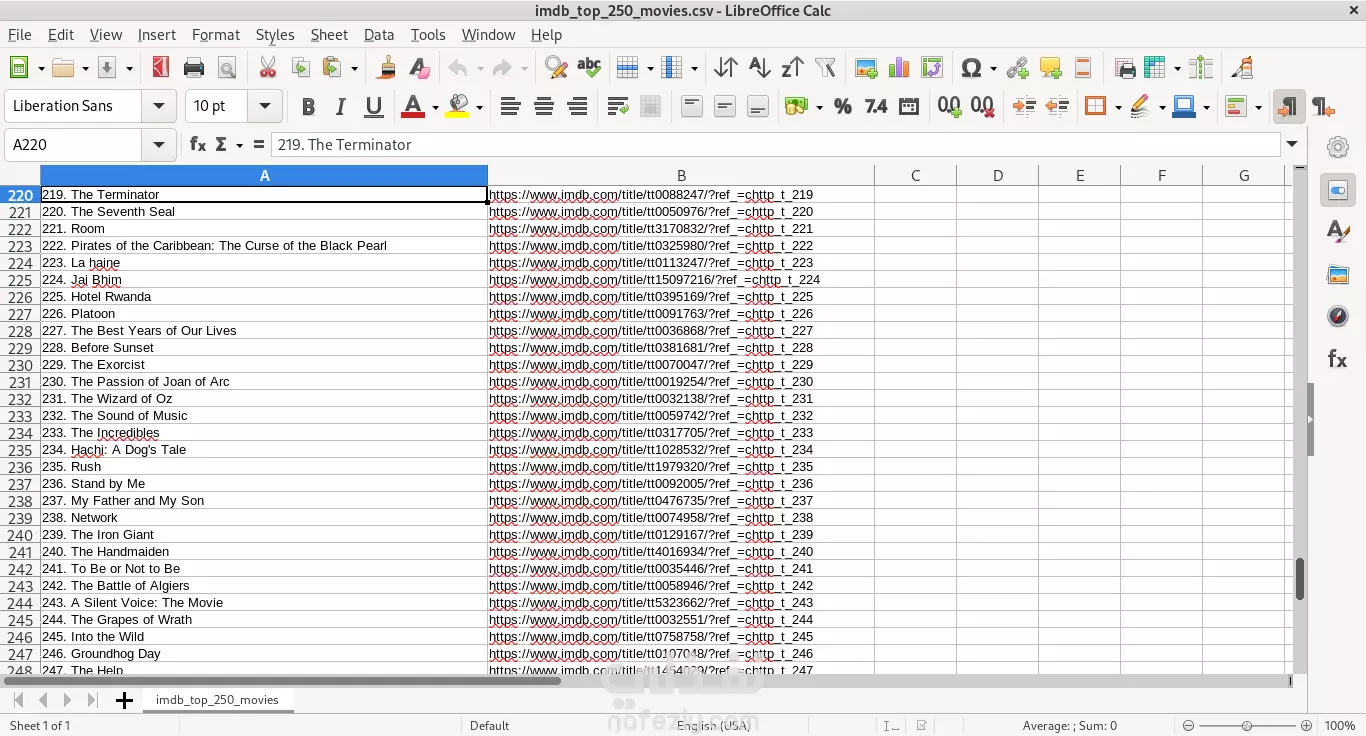
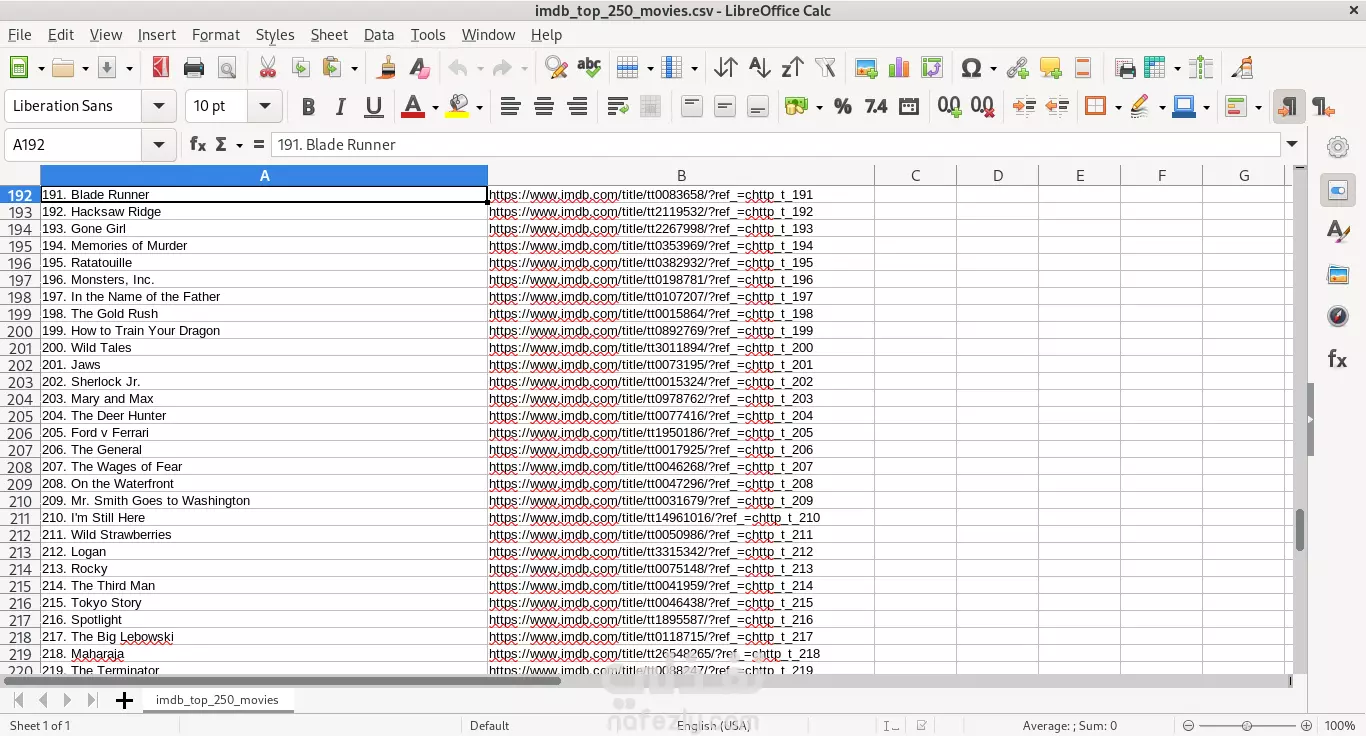
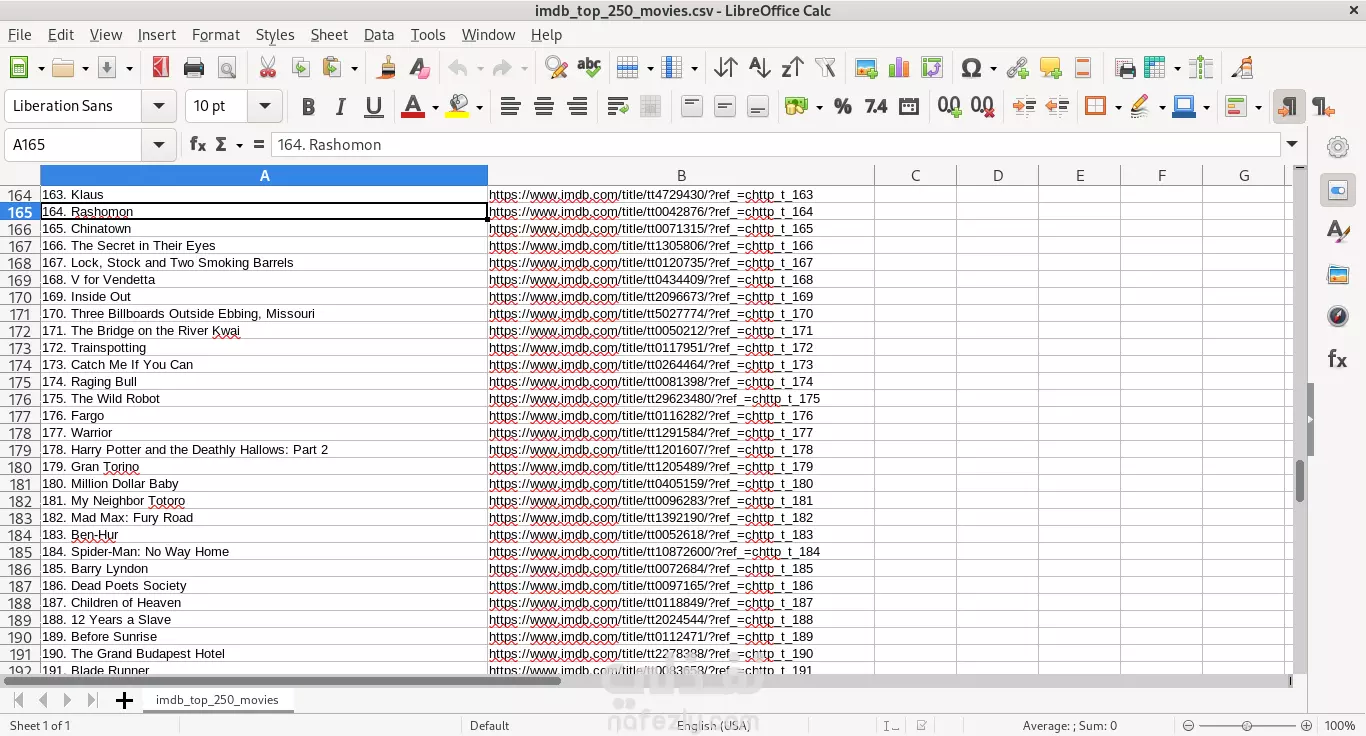
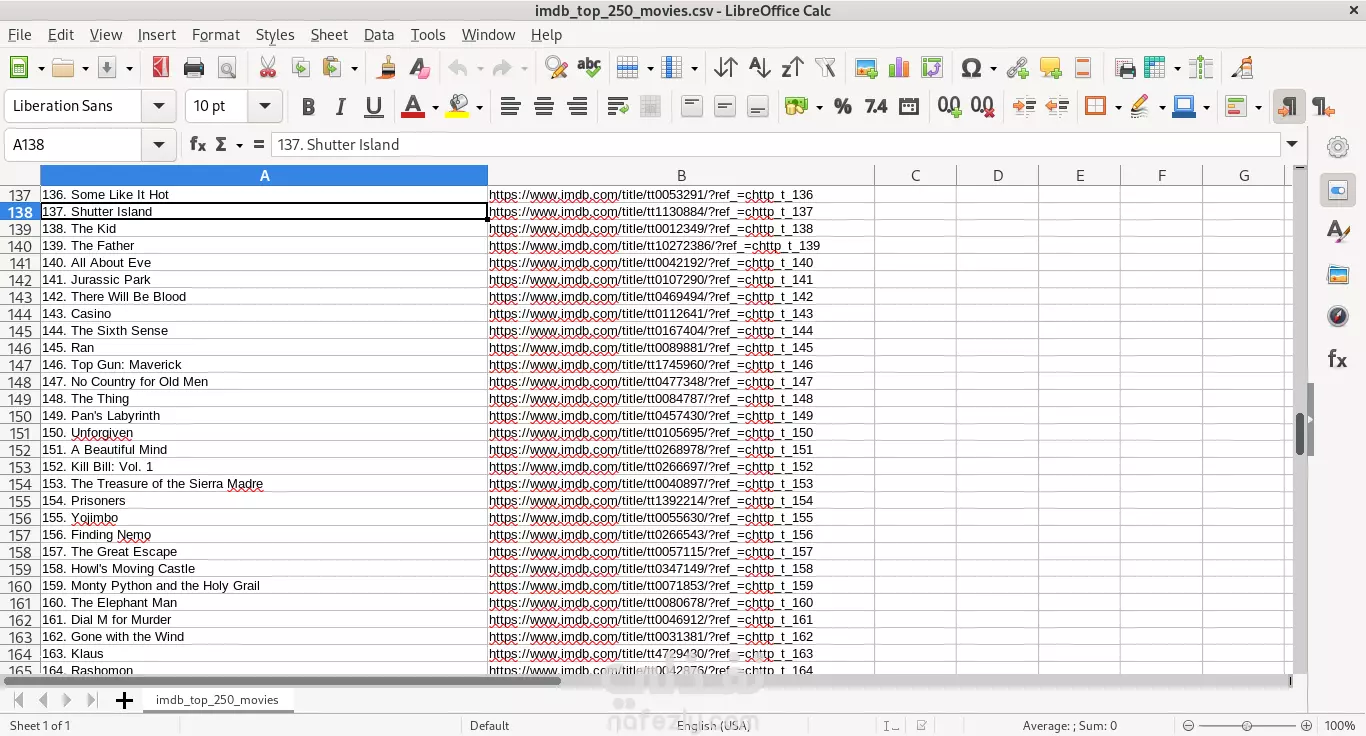
هذا المشروع يهدف إلى جمع بيانات عن أفضل 250 فيلمًا حسب تقييمات موقع IMDb (Internet Movie Database). يتم استخدام تقنيات التحليل الإلكتروني (Web Scraping) لجمع البيانات من الموقع، مع مراعاة قواعد الموقع وشروط الاستخدام. النتيجة النهائية هي ملف CSV يحتوي على أسماء الأفلام وأرائها. الأهداف الرئيسية جمع البيانات : استخراج أسماء الأفلام وأرائها من صفحة IMDb. تخزين البيانات : حفظ البيانات في ملف CSV للاستخدام المستقبلي. البيانات المطلوبة أسماء الأفلام . روابط الأفلام . الخطوات التنفيذية تحليل الصفحة الهدف : تم فحص صفحة IMDb للتأكد من كيفية عرض البيانات. تم تحديد العناصر التي تحتوي على أسماء الأفلام والروابط. استخدام أدوات التحليل الإلكتروني : تم استخدام Playwright ، وهو إطار عمل قوي لتحليل الويب باستخدام Python. Playwright يدعم تشغيل المتصفحات بشكل آلي (Headless Mode) لتجنب الحاجة إلى تثبيت ملحقات إضافية مثل ChromeDriver. جمع البيانات : تم تصفح الصفحة الرئيسية لموقع IMDb. تم استخراج أسماء الأفلام والروابط الخاصة بها. تم تخزين البيانات في قائمة Python. حفظ البيانات : تم تحويل القائمة إلى جدول باستخدام مكتبة Pandas . تم حفظ الجدول النهائي في ملف CSV لسهولة الوصول إليه واستخدامه لاحقًا. النتائج تم جمع بيانات لأفضل 250 فيلمًا من IMDb. تم تنظيم البيانات في ملف CSV يحتوي على: أسماء الأفلام. روابط الأفلام. التقنيات المستخدمة Python : لتنفيذ كود التحليل الإلكتروني. Playwright : لإنشاء متصفح آلي لتحليل الصفحات الديناميكية. Pandas : لتنظيم البيانات وإدارتها. BeautifulSoup : لتحليل HTML واستخراج البيانات. Requests : لتحميل صفحات الويب إذا كانت البيانات ثابتة. CSV : لتخزين البيانات في صيغة قابلة للقراءة والتحليل.
مهارات العمل
بطاقة العمل

طلب عمل مماثل












